I have recently started training with the group and coming from a slightly different research background I was unfamiliar with some a lot of the terminology. I thought it might be useful to put together a glossary of sorts containing the terms that someone new to this field of study might not intuitively understand. The idea is that when someone encounters an unfamiliar term while going through the training or reading through the material, they can come to the blog glossary and quickly Ctrl-F the term (yes, that is a keyboard shortcut used as a verb).
The definitions are not exhaustive, but links/references are provided so the reader can find additional material. The glossary is a work in progress, some definitions are still incomplete, but it will be regularly updated. I’m also probably the least qualified person in the group to provide the definitions, so any corrections/suggestions are more than welcome. If there’s any other term I’ve omitted and you feel should be included, please leave a comment so I can edit the post.
Glossary
Adaptive metropolis algorithm
It is based on the classical random walk Metropolis algorithm and adapts continuously to the target distribution. 1
Akaike’s Information Criterion (AIC)
A measure of the relative quality of statistical models for a given set of data.2
AMALGAM
MOEA that applies a multi-algorithm search that combines the NSGAII, particle swarm optimization, differential evolution, and adaptive metropolis.3
Approximation set
The set of solutions output by a multi-objective evolutionary algorithm approximating the Pareto front.4
Archive
A secondary population used by many multi-objective evolutionary algorithms to store non-dominated solutions found through the generational process.5
Attainment
Attainment plot
Bayesian Information Criterion
Borg MOEA
Iterative search algorithm for multi-objective optimization. It combines adaptive operator selection with ε-dominance, adaptive population sizing and time continuation. 6
Classification and Regression Trees (CART)
Decision tree algorithms that can used for classification and regression analysis of predictive modeling problems.7
Closed vs. open loop control
Concavity
See Convexity.
Constraints
Restrictions imposed on the decision space by the particular characteristics of the system. They must be satisfied for a certain solution to be considered acceptable.5
Control map
Controllability
Refers to whether the parameterization choices have significant impacts on the success or failure for an algorithm.
Convergence
Progress towards the reference set.
Convexity
Geometrically, a function is convex is a line segment drawn from any point along function f to any other point along f lies on or above the graph of f. For optimization problems, a problem is convex if the objective function and all constraints are convex functions if minimizing, and concave is maximizing.
(The) Cube
The Reed Group’s computing cluster run by the Center for Advanced Computing (CAC) at Cornell. The cluster has 32 nodes, each with Dual 8-core E5-2680 CPUs @ 2.7 GHz and 128 GB of RAM. For more information see: https://www.cac.cornell.edu/wiki/index.php?title=THECUBE_Cluster
Decision space
The set of all decision variables.
Decision variables
The numerical quantities (variables) that are manipulated during the optimization process and they represent how our actions are encoded within the problem.5
Deterioration
When elements of a solution set at a given time are dominated by a solution set the algorithm maintained some time before.5
Differential evolution
Evolutionary algorithm designed to optimize problems over continuous domains.5
Direct policy search
Dominance resistance
The inability of an algorithm to produce offspring that dominates poorly performing, non-dominated members of the population. (See also Pareto dominance).8
DTLZ problems
A suite of representative test problems for MOEAs that for which the analytical solutions have been found. The acronym is a combination of the first letters of the creators’ last names (Deb, Thiele, Laumanns, Zitzler). DTLZ problems have been used for benchmarking and diagnostics when evaluating the performance of MOEAs.
Dynamic memory
Elitism
Refers to a case where as evolution progresses, non-dominated solutions will not be lost in subsequent generations.
Epsilon (ε) dominance
When dominance is determined by use of a user-specified precision to simplify sorting. Pareto epsilon (ε) optimality and Pareto epsilon (ε) front are defined accordingly. (See also Pareto dominance).5
Epsilon (ε) dominance archive
Epsilon (ε)-box dominance archive
ε-MOEA
A steady-state MOEA, the first to incorporate ε-dominance archiving into its search process.
Epsilon (ε) indicator
Additive ε-indicator (ε+-indicator) (performance metric)
The smallest distance ε that the approximation set must be translated by in order to completely dominate the reference set.4
Epsilon (ε) progress
Equifinality
Evolutionary algorithms
A class of search and optimization algorithms inspired by processes of natural evolution.5
Multi-objective evolutionary algorithms (MOEAs)
Evolutionary algorithms used for solving multi-objective problems.5
Evolutionary operators
They operate on the population of an evolutionary algorithm attempting to generate solutions with higher and higher fitness.5
Mutation evolutionary operators
They perturb the decision variables of a single solution to look for improvement in its vicinity.
Recombination evolutionary operators
They combine decision variables from two or more solutions to create new solutions.
Selection evolutionary operators
They determine which solutions are allowed to proceed to the next cycle.
Executioner
A cross-language automation tool for running models. (See also Project Platypus).
Exploratory Modeling and Analysis (EMA)
A research methodology that uses computational experiments to analyze complex and uncertain systems.9
Data-driven exploratory modeling
Used to reveal implications of a data set by searching through an ensemble of models for instances that are consistent with the data.
Question-driven exploratory modeling
Searches over an ensemble of models believed to be plausible to answer a question of interest or illuminate policy choices.
Model-driven exploratory modeling
Investigates the properties of an ensemble of models without reference to a data set or policy question. It is rather a theoretical investigation into the properties of a class of models.
Feasible region
The set of all decision variables in the decision space that are feasible (i.e. satisfy all constraints).5
GDE3
Generational algorithms
A class of MOEAs that replace the entire population during each full mating, mutation, and selection iteration of the algorithm.5 (See also Steady-state algorithms).
Generational distance (performance metric)
The average distance from every solution in the approximation set to the nearest solution in the reference set.4
Gini index
A generalization of the binomial variance used in Classification and Regression Trees (CART). (See also Classification and Regression Trees (CART)).
High performance computing
Hypervolume (performance metric)
The volume of the space dominated by the approximation set.4
Inverted generational distance (performance metric)
The average distance from every solution in the reference set to the nearest solution in the approximation set.4
J3
A free desktop application for producing and sharing high-dimensional, interactive scientific visualizations. (See also Project Platypus).
Kernel density estimation
Latin Hypercube Sampling (LHS)
Stratified technique used to generate samples of parameter values.
Markov chain
Method of moments
MOEA Framework
A free and open source Java library for developing and experimenting with multi-objective evolutionary algorithms and other general-purpose optimization algorithms.4
Monte Carlo
Morris method
NSGA-II
The Non-dominated Sorting Genetic Algorithm-II. MOEA featuring elitism, efficient non-domination sorting, and parameter free diversity maintenance.10
ε-NSGA-II
A generational algorithm that uses e-dominance archiving, adaptive population sizing and time continuation.
Number of function evaluations (NFE)
Objectives
The criteria used to compare solutions in an optimization problem.
OMOPSO
A particle swarm optimization algorithm—the first to include e-dominance as a means to solve many-objective problems.11
Optimization
The process of identifying the best solution (or a set of best solutions) among a set of alternatives.
Multi-objective optimization
Multi-objective optimization employs two or more criteria to identify the best solution(s) among a set of alternatives
Intertemporal optimization
Parallel computing
Parametric generator
Pareto optimality
The notion that a solution is superior or inferior to another solution only when it is superior in all objectives or inferior in all objectives respectively.
Pareto dominance
A dominating solution is superior to another in all objectives. A dominated solution is inferior to another in all objectives. A non-dominated solution is superior in one objective but inferior in another.
Pareto front
Contains the objective values of all non-dominated solutions (in the objective function space).
Pareto optimal set
Contains the decision variables of all non-dominated solutions (in the decision variable space).
Particle swarm optimization
Population-based stochastic optimization technique where the potential solutions, called particles, fly through the problem space by following the current optimum particles.
Patient Rule Induction method (PRIM)
A rule induction algorithm.
Performance metrics
Procedures used to compare the performance of approximation sets.
Pointer
Population
The set of encoded solutions that are manipulated and evaluated during the application of an evolutionary algorithm.
Principle Component Analysis (PCA)
Project Platypus
A Free and Open Source Python Library for Multiobjective Optimization. For more information see: https://github.com/Project-Platypus
Radial basis function
Reference set
The set of globally optimal solutions in an optimization problem.
Rhodium
Python Library for Robust Decision Making and Exploratory Modelling. (See also Project Platypus).
Robust Decision Making (RDM)
An analytic framework that helps identify potential robust strategies for a particular problem, characterize the vulnerabilities of such strategies, and evaluate trade-offs among them.12
Multi-objective robust decision making (MORDM)
An extension of Robust Decision Making (RDM) to explicitly include the use of multi-objective optimization to discover robust strategies and explore the trade-offs among multiple competing performance objectives.13
OpenMORDM
An open source implementation of MORDM with the tools necessary to perform a complete MORDM analysis.14 For more information see: https://github.com/OpenMORDM
Safe operating space
SALib
Seeding
Sobol sampling
Spacing (performance metric)
The uniformity of the spacing between the solutions in an approximation set.
SPEA2
MOEA that assigns a fitness value to each solution based on the number of competing solutions it dominates.
State of the world
A fundamental concept in decision theory which refers to a feature of the world that the agent/decision maker has no control over and is the origin of the agent’s uncertainty about the world.
Steady-state algorithms
A class of MOEAs that only replace one solution in the population during each full mating, mutation, and selection iteration of the algorithm. (See also Generational algorithms).
Time continuation
The injection of new solutions in the population to reinvigorate search.
Tournament
The set of candidate solutions selected randomly from a population.
Trace
Visual analytics
The rapid analysis of large datasets using interactive software that enables multiple connected views of planning problems.
More information on the concepts
- Haario, H., Saksman, E. & Tamminen, J. An adaptive Metropolis algorithm. Bernoulli 7, 223–242 (2001).
- Akaike, H. Akaike’s information criterion. in International Encyclopedia of Statistical Science 25–25 (Springer, 2011).
- Vrugt, J. A. & Robinson, B. A. Improved evolutionary optimization from genetically adaptive multimethod search. Proc. Natl. Acad. Sci. 104, 708–711 (2007).
- Hadka, D. Beginner’s Guide to the MOEA Framework. (CreateSpace Independent Publishing Platform, 2016).
- Coello, C. A. C., Lamont, G. B. & Van Veldhuizen, D. A. Evolutionary algorithms for solving multi-objective problems. 5, (Springer, 2007).
- Hadka, D. & Reed, P. Borg: An Auto-Adaptive Many-Objective Evolutionary Computing Framework. Evol. Comput. 21, 231–259 (2012).
- Breiman, L. Classification and Regression Trees. (Wadsworth International Group, 1984).
- Reed, P. M., Hadka, D., Herman, J. D., Kasprzyk, J. R. & Kollat, J. B. Evolutionary multiobjective optimization in water resources: The past, present, and future. Adv. Water Resour. 51, 438–456 (2013).
- Bankes, S. Exploratory Modeling for Policy Analysis. Oper. Res. 41, 435–449 (1993).
- Deb, K., Pratap, A., Agarwal, S. & Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. Evol. Comput. IEEE Trans. On 6, 182–197 (2002).
- Sierra, M. R. & Coello, C. C. Improving PSO-based multi-objective optimization using crowding, mutation and e-dominance. in Evolutionary multi-criterion optimization 3410, 505–519 (Springer, 2005).
- Lempert, R. J., Groves, D. G., Popper, S. W. & Bankes, S. C. A general, analytic method for generating robust strategies and narrative scenarios. Manag. Sci. 52, 514–528 (2006).
- Kasprzyk, J. R., Nataraj, S., Reed, P. M. & Lempert, R. J. Many objective robust decision making for complex environmental systems undergoing change. Environ. Model. Softw. (2013). doi:10.1016/j.envsoft.2012.12.007
- Hadka, D., Herman, J., Reed, P. & Keller, K. An open source framework for many-objective robust decision making. Environ. Model. Softw. 74, 114–129 (2015).






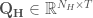 and the set of synthetic streamflows as
and the set of synthetic streamflows as  , where
, where  and
and  are the number of years in the historical and synthetic records, respectively, and T is the number of time steps per year. Here T=12 for 12 months. For the synthetic generation, the streamflows in
are the number of years in the historical and synthetic records, respectively, and T is the number of time steps per year. Here T=12 for 12 months. For the synthetic generation, the streamflows in  are log-transformed to yield the matrix
are log-transformed to yield the matrix  , where i and j are the year and month of the historical record, respectively. The streamflows in
, where i and j are the year and month of the historical record, respectively. The streamflows in  are then standardized to form the matrix
are then standardized to form the matrix 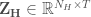 according to equation 1:
according to equation 1:
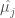 and
and  are the sample mean and sample standard deviation of the j-th month’s log-transformed streamflows, respectively. These variables follow a standard normal distribution:
are the sample mean and sample standard deviation of the j-th month’s log-transformed streamflows, respectively. These variables follow a standard normal distribution:  .
. by first creating a matrix
by first creating a matrix  of randomly sampled standard normal streamflows from
of randomly sampled standard normal streamflows from  whose elements are independently sampled integers from
whose elements are independently sampled integers from  . Each element of
. Each element of 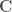 is then assigned the value
is then assigned the value  , i.e. the elements in each column of
, i.e. the elements in each column of 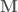 is used to generate
is used to generate  . Denoting the historical autocorrelation
. Denoting the historical autocorrelation 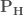 =corr(
=corr(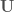 , can be found using Cholesky decomposition (
, can be found using Cholesky decomposition ( .
. 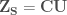 . Finally, for each site, the auto-correlated synthetic standard normal streamflows
. Finally, for each site, the auto-correlated synthetic standard normal streamflows  according to
according to  . These are then transformed back to real-space streamflows
. These are then transformed back to real-space streamflows 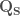 according to
according to 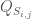 =exp(
=exp( ).
). will yield discontinuities in the autocorrelation from month 12 of one year to month 1 of the next. To resolve this issue, Kirsch et al. (2013) repeat the method described above with a historical matrix
will yield discontinuities in the autocorrelation from month 12 of one year to month 1 of the next. To resolve this issue, Kirsch et al. (2013) repeat the method described above with a historical matrix  , where each row i of
, where each row i of  contains historical data from month 7 of year i to month 6 of year i+1, removing the first and last 6 months of streamflows from the historical record.
contains historical data from month 7 of year i to month 6 of year i+1, removing the first and last 6 months of streamflows from the historical record.  is then generated from
is then generated from 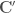 is generated from
is generated from 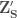 is then calculated as
is then calculated as 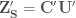 . Concatenating the last 6 columns of
. Concatenating the last 6 columns of ![d = \left[\sum^{M}_{m=1} \left({\left(q_{S}\right)}_{m} - {\left(q_{H}\right)}_{m}\right)^2\right]^{1/2}](https://s0.wp.com/latex.php?latex=d+%3D+%5Cleft%5B%5Csum%5E%7BM%7D_%7Bm%3D1%7D+%5Cleft%28%7B%5Cleft%28q_%7BS%7D%5Cright%29%7D_%7Bm%7D+-+%7B%5Cleft%28q_%7BH%7D%5Cright%29%7D_%7Bm%7D%5Cright%29%5E2%5Cright%5D%5E%7B1%2F2%7D&bg=ffffff&fg=444444&s=0&c=20201002)
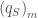 is the real-space synthetic monthly flow generated at site m and
is the real-space synthetic monthly flow generated at site m and  is the real-space historical monthly flow at site m. The k-nearest neighbors are then sorted from i=1 for the closest to i=k for the furthest, and probabilistically selected for proportionally scaling streamflows in disaggregation.
is the real-space historical monthly flow at site m. The k-nearest neighbors are then sorted from i=1 for the closest to i=k for the furthest, and probabilistically selected for proportionally scaling streamflows in disaggregation. 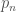 of selecting neighbor n (equation 3):
of selecting neighbor n (equation 3):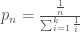
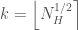 . After a neighbor is selected, the final step in disaggregation is to proportionally scale all of the historical daily streamflows at site m from the selected neighbor so that they sum to the synthetically generated monthly total at site m. For example, if the first day of the month of the selected historical neighbor represented 5% of that month’s historical flow, the first day of the month of the synthetic series would represent 5% of that month’s synthetically-generated flow. The random neighbor selection is performed by
. After a neighbor is selected, the final step in disaggregation is to proportionally scale all of the historical daily streamflows at site m from the selected neighbor so that they sum to the synthetically generated monthly total at site m. For example, if the first day of the month of the selected historical neighbor represented 5% of that month’s historical flow, the first day of the month of the synthetic series would represent 5% of that month’s synthetically-generated flow. The random neighbor selection is performed by 
