Hello there, welcome to a new training series!
In a series of five posts, we will be analyzing and exploring the Fisheries Game, which is a rich, predator-prey system with complex and nonlinear dynamics arising from the interactions between two fish species. This game will be used to walk through the steps of performing a broad a posteriori decision making process, including the exploration and characterization of impacts of system uncertain on the performance outcomes. It also serves as a conceptual tool to demonstrate the importance of accounting for deep uncertainty, and the significance of its effects on system response to management actions.
A GitHub repository containing all of the necessary code for this series is available here, and will be updated as the series develops.
We will begin here (Post 0) with an introduction to the Fisheries Game, using a modified form of the Lotka-Volterra equations for predator-prey dynamics.
Toward the end of this post, we will provide an overview of where this series is going and the tools that will be used along the way.
A very quick introduction to the Lotka-Volterra system of equations
In this game, we are stakeholders for a managed fishery. Our goal is to determine a harvesting strategy which balances tradeoffs between ecological and economic objectives. Throughout this process we will consider ecological stability, harvest yield, harvest predictability, and profits while attempting to maintain the robustness of both the ecological system and economic performance under the presence of uncertainty.
The first step in our decision making process is to model population dynamics of the fish species.

Equation 1 is the original Lotka-Volterra system of equations (SOE) as developed independently by Alfred Lotka in 1910, and by Vito Volterra in 1928. In this equation, x is the population density of the prey, and y is the population density of the predator. This SOE characterizes a prey-dependent predator-prey functional response, which assumes a linear relationship between prey consumption and predator growth.
Arditi and Akçakaya (1990) constructed an alternative predator-prey SOE, which assume a non-linear functional response (i.e., predator population growth is not linear with consumption). It accounts for predation efficiency parameters such as interference between predators, time needed to consume prey after capture, and a measure of how long it takes to convert consumed prey into new predators. This more complex SOE takes the form:

The full description of the variables are as follows: x and y are the prey and predator population densities at time t respectively (where t is in years); α is the rate at which the predator encounters the prey; b is the prey growth rate; c is the rate at which the predator converts prey to new predators; d is predator death rate; h is the time it needs to consume the prey (handling time); K is the environmental carrying capacity; m is the level of predator interaction; and z is the fraction of the prey population that is harvested. In this post, we will spend some time exploring the potential behavior of these equations.
Before proceeding further, here are some key terms used throughout this post:
- Zero isoclines: Lines on the plot indicating prey or predator population levels that result in constant population size over time (zero growth rate).
- Global attractor: The specific value that the system tends to evolve toward, independent of initial conditions.
- Equilibrium point: The intersection of two (or more) zero isoclines; a point or line of trajectory convergence.
- Stable (nontrivial) equilibrium: Equilibrium at which both prey and predator exist
- Unstable equilibrium: Global attractor is a stable limit cycle
- Stable limit cycle: A closed (circular) trajectory
- Trajectory: The path taken by the system given a specific set of initial conditions.
- Functional response: The rate of prey consumption by your average predator.
Population equilibrium and stability
When beginning to consider a harvesting policy, it is important to first understand the natural stability of the system.
Population equilibrium is a necessary condition for stability. The predator and prey populations are in equilibrium if the rate of change of the populations is zero:

Predator stability
Let’s first consider the equilibria of the predator population. In this case, we are only interested in the non-trivial (or co-existence) equilibria where the predator and prey populations are non-zero (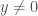

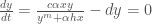
Here, we are interested in solving for the predator zero-isocline (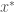


Solving for 
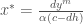
In the context of the fisheries, we are interested in the co-existence conditions in which 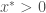
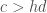
Simply put, the rate at which predators convert prey into new predators (
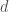
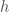
Prey stability
A similar process can be followed for the derivation of the zero-isocline stability condition for the prey population. The stability condition can be determined by solving for:

As the derivation of the prey isocline is slightly more convoluted than the predator isocline, the details are not presented here, but are available in the Supplementary Materials of Hadjimichael et al. (2020), which is included in the GitHub repository for this post here.
Resolution of this stability condition yields the second necessary co-existence equilibrium condition:

Uncertainty
As indicated by the two conditions above, the stability of the predator and prey populations depends upon ecosystem properties (e.g., the availability of prey, 



Specification of different values for these parameters results in wildly different system dynamics. Below are examples of three different population trajectories, each generated using the same predator-dependent system of equations, with different parameter values.

Exploring system dynamics (interactive!)
To emphasize the significance of parameter uncertainty on the behavior of predator-prey system behavior, we have prepared an interactive Jupyter Notebook. Here, you have ability to interactively change system parameter values and observe the subsequent change in system behavior.
The Binder link to the interactive Jupyter Notebook prepared by Trevor Amestoy can be found here. Before the code can be run, open the ‘Terminal’, as shown in Figure 2 below.

Install the necessary libraries by entering the following line into the terminal:
pip install numpy scipy matplotlib pandas
You’re good to go once the libraries have been loaded. Open the Part_0_Interactive_fisheries_ODEs.ipynb file in the Part_0_ODE_Dynamics/ folder.
Play around with the sliders to see what system trajectories you end up with! Notice how abruptly the population dynamics change, even with minor changes in parameter values.
The following GIFs show some potential trajectories you might observe as you vary the ranges of the variables:
Starting at a stable equilibrium
In Figure 3 below, both prey and predator eventually coexist at constant population sizes with no human harvesting.

However, this is a fishery with very small initial initial prey population size. Here, note how quickly the system changes from one of stable equilibrium into that of unstable equilibrium with a small decrease in the value of α. Without this information, stakeholders might unintentionally over-harvest the system, causing the extinction of the prey population.
Starting at an unstable equilibrium
Next, Figure 4 below shows an unstable equilibrium with limit cycles and no human harvesting.

Figure 4 shows that a system will be in a state of unstable equilibrium when it takes very little time for the predator to consume prey, given moderately low prey population sizes and prey population growth rate. Although predators die at a relatively high rate, the prey population still experiences extinction as it is unable to replace population members lost through consumption by the predator species. This is a system in which stakeholders might instead choose to harvest the predator species.
Introducing human harvesting
Finally, a stable equilibrium that changes when human harvesting of the prey population is introduced in Figure 5 below.

This Figure demonstrates a combination of system parameters that might represent a system that can be harvested in moderation. It’s low prey availability is abated by a relatively high predator growth rate and relatively low conversion rates. Be that as it may, exceeding harvesting rates may suddenly cause the system to transition into an unstable equilibrium, or in the worst case lead to an unexpected collapse of the population toward extinction.
Given that the ecosystem parameters are uncertain, and that small changes in the assumed parameter values can result in wildly different population dynamics, it begs the question: how can fisheries managers decide how much to harvest from the system, while maintaining sustainable population levels and avoiding system collapse?
This is the motivating question for the upcoming series!
The MSD UC eBook

To discover economic and environmental tradeoffs within the system, reveal the variables shaping the trajectories shown in Figure 3 to 5, and map regions of system vulnerability, we will need suitable tools.
In this training series, we will be primarily be using the MSD UC eBook and its companion GitHub repository as the main resources for such tools. Titled ‘Addressing uncertainty in MultiSector Dynamics Research‘, the eBook is part of an effort towards providing an open, ‘living’ toolkit of uncertainty characterization methods developed by and for the MultiSector Dynamics (MSD) community. The eBook also provides a hands-on Jupyter Notebook-based tutorial for performing a preliminary exploration of the dynamics within the Fisheries Game, which we will be expanding on in this tutorial series. We will primarily be using the eBook to introduce you to sensitivity analysis (SA) methods such as Sobol SA, sampling techniques such as Latin Hypercube Sampling, scenario discovery approaches like Logistic Regression, and their applications to complex, nonlinear problems within unpredictable system trajectories. We will also be making frequent use of the functions and software packages available on the MSD GitHub repository.
To make the most out of this training series, we highly recommend familiarizing yourself with the eBook prior to proceeding. In each of the following posts, we will also be making frequent references to sections of the eBook that are relevant to the current post.
Training sequence
In this post, we have provided an overview of the Fisheries Game. First, we introduced the basic Lotka-Volterra equations and its predator-dependent predator-prey variation (Arditi and Akcakaya, 1990) used in Hadjimichael et al. (2020). We also visualized the system and explored how the system trajectories change with different parameter specifications. Next, we introduced the MSD UC eBook as a toolkit for exploring the Fisheries’ system dynamics.
Overall, this post is meant to be a gateway into a deep dive into the system dynamics of the Fisheries Game as formulated in Hadjimichael et al. (2020), using methods from the UC eBook as exploratory tools. The next few posts will set up the Fisheries Game and its objectives for optimization, explore the implications of varying significant decision variables, map parameter ranges that result in system vulnerability, and visualize these outcomes. The order for these posts are as follows:
Post 1 Problem formulation and optimization of the Fisheries Game in Rhodium
Post 2 Visualizing and exploring the Fisheries’ Pareto set and Pareto front using Rhodium and J3
Post 3 Identifying important system variables using different sensitivity analysis methods
Post 4 Mapping consequential scenarios that drive the Fisheries’ vulnerability to deep uncertainty
That’s all from us – see you in Post 1!
References
Abrams, P., & Ginzburg, L. (2000). The nature of predation: prey dependent, ratio dependent or neither?. Trends In Ecology &Amp; Evolution, 15(8), 337-341. https://doi.org/10.1016/s0169-5347(00)01908-x
Arditi, R., & Akçakaya, H. R. (1990). Underestimation of Mutual Interference of Predators. Oecologia, 83(3), 358–361. http://www.jstor.org/stable/4219345
Hadjimichael, A., Reed, P., & Quinn, J. (2020). Navigating Deeply Uncertain Tradeoffs in Harvested Predator-Prey Systems. Complexity, 2020, 1-18. https://doi.org/10.1155/2020/4170453
Lotka, A. (1910). Contribution to the Theory of Periodic Reactions. The Journal Of Physical Chemistry, 14(3), 271-274. https://doi.org/10.1021/j150111a004
Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
Volterra, V. (1928). Variations and Fluctuations of the Number of Individuals in Animal Species living together. ICES Journal Of Marine Science, 3(1), 3-51. https://doi.org/10.1093/icesjms/3.1.3