

In this blog post, we will be reviewing how to perform runtime diagnostics using MOEAFramework. This software has been used in prior blog posts by Rohini and Jazmin to perform MOEA diagnostics across multiple MOEA parameterizations. Since then, MOEAFramework has undergone a number of updates and structure changes. This blog post will walk through the updated functionality of running MOEAFramework (version 4.0) via the command line to perform runtime diagnostics across 20 seeds using one set of parameters. We will be using the classic 3-objective DTLZ2 problem optimized using NSGAII, both of which are in-built into MOEAFramework.
Before we begin, some helpful tips and system configuration requirements:
- Ensure that you have the latest version of Java installed (as of April 2024, this is Java Version 22). The current version of MOEAFramework was compiled using class file version 61.0, which was made available in Java Version 17 (find the complete list of Java versions and their associated class files here). This is the minimum requirement for being able to run MOEAFramework.
- The following commands are written for a Linux interface. Download a Unix terminal emulator like Cygwin if needed.
Another helpful tip: to see all available flags and their corresponding variables, you can use the following structure:
java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.mainClass.subClass.functionName --help
Replace mainClass, subClass, and functionName with the actual class, subclass, and function names. For example,
java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.SampleGenerator --help
You can also replace --help with -h (if the last three alphabets prove too much to type for your weary digits).
Runtime diagnostics across 20 different seeds for one set of parameters
Generating MOEA parameters and running the optimization
To run NSGAII using one set of parameters, make sure to have a “parameters file” saved as a text file containing the following:
populationSize 10.0 250.999
maxEvaluations 10000 10000
sbx.rate 0.0 1.0
sbx.distributionIndex 0.0 100.0
pm.rate 0.0 1.0
pm.distributionIndex 0.0 100.0
For the a full list of parameter files for each of the in-built MOEAFramework algorithms, please see Jazmin’s post here.
In this example, I have called it NSGAII_Params.txt. Note that maxEvaluations is set to 10,000 on both its lower and upper bounds. This is because we want to fix the number of function evaluations completed by NSGAII. Next, in our command line, we run:
java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.SampleGenerator --method latin --numberOfSamples 1 --parameterFile NSGAII_Params.txt --output NSGAII_Latin
The output NSGAII_Latin file should contain a single-line that can be opened as a text file. It should have six tab-delineated values that correspond to the six parameters in the input file that you have generated. Now that you have your MOEA parameter files, let’s begin running some optimizations!
First, make a new folder in your current directory to store your output data. Here, I am simply calling it data.
mkdir data
Next, optimize the DTLZ2 3-objective problem using NSGAII:
for i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.RuntimeEvaluator --parameterFile NSGAII_Params.txt --input NSGAII_Latin --problem DTLZ2_3 --seed $i --frequency 1000 --algorithm NSGAII --output data/NSGAII_DTLZ2_3_$i.data; done
Here’s what’s going down:
- First, you are performing a runtime evaluation of the optimization of the 3-objective DTLZ2 problem using NSGAII
- You are obtaining the decision variables and objective values at every 1,000 function evaluations, effectively tracking the progress of NSGAII as it attempts to solve the problem
- Finally, you are storing the output in the
data/folder - You then repeat this for 20 seeds (or for as many as you so desire).
Double check your .data file. It should contain information on your decision variables and objective values at every 1,000 NFEs or so, seperated from the next thousand by a “#”.
Generate the reference set
Next, obtain the only the objective values at every 1,000 NFEs by entering the following into your command line:
for i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.ResultFileMerger --problem DTLZ2_3 --output data/NSGAII_DTLZ2_3_$i.set --epsilon 0.01,0.01,0.01 data/NSGAII_DTLZ2_3_$i.data; done
Notice that we have a new flag here – the --epsilon flag tells MOEAFramework that you only want objective values that are at least 0.01 better than other non-dominated objective values for a given objective. This helps to trim down the size of the final reference set (coming up soon) and remove solutions that are only marginally better (and may not be decision-relevant in the real-world context).
On to generating the reference set – let’s combine all objectives across all seeds using the following command line directive:
for i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.ReferenceSetMerger --output data/NSGAII_DTLZ2_3.ref -epsilon 0.01,0.01,0.01 data/NSGAII_DTLZ2_3_$i.set; done
Your final reference set should now be contained within the NSGAII_DTLZ2_3.ref file in the data/ folder.
Generate the runtime metrics
Finally, let’s generate the runtime metrics. To avoid any mix-ups, let’s create a folder to store these files:
mkdir data_metrics
And finally, generate our metrics!
or i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.ResultFileEvaluator --problem DTLZ2_3 --epsilon 0.01,0.01,0.01 --input data/NSGAII_DTLZ2_3_$i.data --reference data/NSGAII_DTLZ2_3.ref --output data_metrics/NSGAII_DTLZ2_3_$i.metrics; done
If all goes well, you should see 20 files (one each for each seed) similar in structure to the one below in your data_metrics/ folder:

The header values are the names of each of the MOEA performance metrics that MOEAFramework measures. In this blog post, we will proceed with visualizing the hypervolume over time across all 20 seeds.
Visualizing runtime diagnostics
The following Python code first extracts the metric that you would like to view, and saves the plot as a PNG file in the data_metrics/ folder:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
# define constants
num_seeds = 20
NFE = 10000
freq = 1000
num_output = int(NFE/freq)
algorithm = 'NSGAII'
problem = 'DTLZ2_3'
folder_name = 'data_metrics/'
metric_name = 'Hypervolume'
# create matrix of hypervolume runtimes
hvol_matrix = np.zeros((num_seeds, num_output), dtype=float)
for seed in range(num_seeds):
runtime_df = pd.read_csv(f'{folder_name}{algorithm}_{problem}_{seed+1}.metrics', delimiter=' ', header=0)
if metric_name == 'Hypervolume':
hvol_matrix[seed] = runtime_df['#Hypervolume'].values
else:
hvol_matrix[seed] = runtime_df[metric_name].values
# plot the hypervolume over time
fig, ax = plt.subplots(figsize=(10, 6))
ax.fill_between(np.arange(freq, NFE+freq, freq), np.min(hvol_matrix, axis=0), np.max(hvol_matrix, axis=0), color='paleturquoise', alpha=0.6)
ax.plot(np.arange(freq, NFE+freq, freq), np.min(hvol_matrix, axis=0), color='darkslategrey', linewidth=2.0)
ax.plot(np.arange(freq, NFE+freq, freq), np.max(hvol_matrix, axis=0), color='darkslategrey', linewidth=2.0)
ax.plot(np.arange(freq, NFE+freq, freq), np.mean(hvol_matrix, axis=0), color='darkslategrey', linewidth=2.0 ,label='Mean', linestyle='--')
ax.set_xlabel('NFE')
ax.set_xlim([freq, NFE+freq])
ax.set_ylabel(metric_name)
ax.set_ylim([0, 1])
ax.set_title(f'{metric_name} over time')
ax.legend(loc='upper left')
plt.savefig(f'{folder_name}{algorithm}{problem}_{metric_name}.png')
If you correctly implemented the code, you should be able to be view the following figure that shows how the hypervolume attained by the NSGAII algorithm improves steadily over time.

In the figure above, the colored inner region spans the hypervolume attained across all 20 seeds, with the dotted line representing the mean hypervolume over time. The solid upper and lower bounding lines are the maximum and minimum hypervolume achieved every 1,000 NFEs respectively. Note that, in this specific instance, NSGAII only achieves about 50% of the total hypervolume of the overall objective space. This implies that a higher NFE (a longer runtime) is required for NSGAII to further increase the hypervolume achieved. Nonetheless, the rate of hypervolume increase is gradually decreasing, indicating that this particular parameterization of NSGAII is fast approaching its maximum possible hypervolume, which additional NFEs only contributing small improvements to performance. It is also worth noting the narrow range of hypervolume values, especially as the number of NFEs grows larger. This is representative of the reliability of the NGSAII algorithm, demonstrating that is can somewhat reliably reproduce results across multiple different seeds.
Summary
This just about brings us to the end of this blog post! We’ve covered how to perform MOEA runtime diagnostics and plot the results. If you are curious, here are some additional things to explore:
- Plot different performance metrics against NFE. Please see Joe Kasprzyk’s post here to better understand the plots you generate.
- Explore different MOEAs that are built into MOEAFramework to see how they perform across multiple seeds.
- Generate multiple MOEA parameter samples using the in-built MOEAFramework Latin Hypercube Sampler to analyze the sensitivity of a given MOEA to its parameterization.
- Attempt examining the runtime diagnostics of Borg MOEA using the updated version of MOEAFramework.
On that note, make sure to check back for updates as MOEAFramework is being actively reviewed and improved! You can view the documentation of Version 4.0 here and access its GitHub repository here.
Happy coding!











 is the pollution concentration in the lake,
is the pollution concentration in the lake,  is the anthropogenically pollution discharged from the town,
is the anthropogenically pollution discharged from the town, 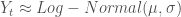 is the natural pollution inflow into the lake and follows a log-normal distribution,
is the natural pollution inflow into the lake and follows a log-normal distribution,  is the rate at which pollution is recycled from the sediment into the water column, and
is the rate at which pollution is recycled from the sediment into the water column, and  is the rate at which the nutrient pollution is removed from the lake due to natural processes.
is the rate at which the nutrient pollution is removed from the lake due to natural processes.  is generated and the policy is evaluated under these conditions. This is repeated 100 times for 100 unique realizations of natural inflow.
is generated and the policy is evaluated under these conditions. This is repeated 100 times for 100 unique realizations of natural inflow.  ) for an increasingly large number of realizations:
) for an increasingly large number of realizations:












{kind=link}