Typing ‘python’ into your command line launches the default global Python environment (which you can change by changing your path) that includes every package you’ve likely installed since the dawn of man (or since you adopted your machine).
But what happens when you are working between Python 2.7 and Python 3.x due to collaboration, using Python 3.4 because the last time you updated your script was four years ago, collaborating with others and want to ensure reproducibility and compatible environments, or banging your head against the wall because that one Python library installation is throwing up errors (shakes fist at PIL/Pillow)?
Creating Python environments is a straightforward solution to save you headaches down the road.
Python environments are a topic that many of us have feared through the years due to ambiguous definitions filled with waving hands. An environment is simply the domain in which users run software or scripts. With this same train of thought, a python environment is the domain with all of the Python packages are installed where a user (you!) is executing a script (usually interfacing through an IDE or Terminal/Command Prompt).
However, different scripts will work or fail in different environments avoid having to use all of these packages at once or having to completely reinstall Python, what we want to do is create new and independent Python environments. Applications of these environments include:
- Have multiple versions of Python (e.g. 2.7 and 3.4 and 3.6) installed on your machine at once that you can easily switch between
- Work with specific versions of packages and ensure they don’t update for the specific script you’re developing
- Allow for individuals to install the same, reproducible environment between workstations
- Create standardized environments for seamless collaboration
- Use older versions of packages to utilize outdated code
Creating Your First Python Environment
One problem that recent arose in Ithaca was that someone was crunching towards deadlines and could only run PIL (Python Imaging Library) on their home machine and not their desktop on campus due to package installation issues. This individual had the following packages they needed to install while using Python 2.7.5:
- PIL
- matplotlib
- numpy
- pandas
- statsmodels
- seaborn
To start, let’s first create an environment! To do this, we will be using Conda (install Anaconda for new users or MiniConda for anyone who doesn’t want their default Python environment to be jeopardized. If you want to avoid using Conda, feel free to explore Pipenv). As a quick note on syntax, I will be running everything in Windows 7 and every command I am using can be found on the Conda Cheatsheet. Only slight variations are required for MacOS/Linux.
First, with your Command Prompt open, type the following command to create the environment we will be working in:
conda create --name blog_pil_example python=2.7.5

At this point, a new environment titled blog_pil_example with Python 2.7.5 has been created. Congrats! Don’t forget to take screenshots to add to your new environment’s baby book (or just use the one above if it’s not your first environment).
From here, we need to activate the environment before interacting with it. To see which environments are available, use the following:
conda env list
Now, let’s go ahead and activate the environment that we want (blog_pil_example):
activate blog_pil_example
To leave the environment you’re in, simply use the following command:
deactivate
(For Linux and MaxOS, put ‘source ‘ prior to these commands)

We can see in the screenshot above that multiple other environments exist, but the selected/activated environment is shown in parentheses. Note that you’re still navigating through the same directories as before, you’re just selecting and running a different version of Python and installed packages when you’re using this environment.
Building Your Python Environment
(Installing Packages)
Now onto the real meat and potatoes: installing the necessary packages. While you can use pip at this point, I’ve found Conda has run into fewer issues over the past year. (Read into channel prioritization if you’re interested in where package files are being sourced from and how to change this.) As a quick back to basics, we’re going to install one of the desired packages, matplotlib, using Conda (or pip). Using these ensures that the proper versions of the packages for your environment (i.e. the Python version and operating system) are retrieved. At the same time, all dependent packages will also be installed (e.g. numpy). Use the following command when in the environment and confirm you want to install matplotlib:
conda install matplotlib
Note that you can specify a version much like how we specified the python version above for library compatibility issues:
conda install matplotlib=2.2.0
If you wish to remove matplotlib, use the following command:
conda remove matplotlib
If you wish to update a specific package, run:
conda update matplotlib
Or to update all packages:
conda update
Additionally, you can prevent specific packages from updating by creating a pinned file in the environment’s conda-meta directory. Be sure to do this prior to running the command to update all packages!
After installing all of the packages that were required at the start of this tutorial, let’s look into which packages are actually installed in this environment:
conda list

By only installing the required packages, Conda was kind and installed all of the dependencies at the same time. Now you have a Python environment that you’ve created from scratch and developed into a hopefully productive part of your workflow.
Utilizing Your Python Environment
The simplest way to utilize your newly created python environment is simply run python directly in the Command Prompt above. You can run any script when this environment is activated (shown in the parentheses on the left of the command line) to utilize this setup!
If you want to use this environment in your IDE of choice, you can simply point the interpreter to this new environment. In PyCharm, you can easily create a new Conda Environment when creating a new project, or you can point the interpreter to a previously created environment (instructions here).
Additional Resources
For a good ground-up and more in depth tutorial with visualizations on how Conda works (including directory structure, channel prioritization) that has been a major source of inspiration and knowledge for me, please check out this blog post by Gergely Szerovay.
If you’re looking for a great (and nearly exhaustive) source of Python Packages (both current and previous versions), check out Gohlke’s webpage. To install these packages, download the associated file for your system (32/64 bit and then your operating system) then use pip to install the file (in Command Prompt, navigate to the folder the .whl file is located in, then type ‘pip install ,file_name>’). I’ve found that installing packages this way sometimes allows me to step around errors I’ve encountered while using
You can also create environments for R. Check it out here.
If you understand most of the materials above, you can now claim to be environmentally conscious!




 the kth sampled value of input variable i, with
the kth sampled value of input variable i, with  and
and 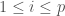 .
.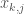 the values of these variables i and j in sample k
the values of these variables i and j in sample k  have:
have:
 and
and  are the average sampled values of inputs i and j .
are the average sampled values of inputs i and j . 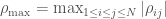
 .
.