
My last post on machine learning basics ended with a discussion of the curse of dimensionality when using K-Nearest Neighbors (K-NN) for classification. To summarize, curse of dimensionality states that as the number of features a point has increases, the more difficult it becomes to find other points that are “close” to that point. This makes classification through K-NN nearly impossible when the number of features is large: if all points are distant from each other, how can you define neighbors? While techniques such as dimensional reduction may help improve the effectiveness of K-NN for high dimensional data, other machine learning algorithms do not suffer from this curse and can allow us to perform classification regardless of dimensionality. One of the first examples of such methods was the Perceptron algorithm, invented right here at Cornell by Frank Rosenblatt in 1957.
Some history
Perceptron is a single layer neural network (though the idea of layered neural networks was not invented until many years after Perceptron). Though the algorithm could run on computers of the day, the first implementation of Perceptron was on a custom built physical machine, the “Mark 1 Perceptron” and used for image recognition. The algorithm was lauded by the press at the time as the beginning of a revolution in artificial intelligence. The New York Times wrote that: “the embryo of an electronic computer that [the Navy] expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence” [1]. Obviously, they got a bit ahead of themselves… The success and popularity of Perceptron was initial a boon for the field of machine learning until a seminal text by Marvin Minsky and Seymour Papert demonstrated that Perceptron is incapable of classifying problems that are not linearly separable (more on this later). This led to a withdrawal of funding for AI research in a period termed the first AI winter (1974-1980).
So what is Perceptron?
While all points in a high dimensional space are distant from each other, it turns out that these same points are all close to any hyperplane drawn within this space. For a nice explanation of this concept, see the excellent course notes from CEE 4780, here (discussion starts at the “distance to hyperplane” section about 3/4 of the way down).
The Perceptron algorithm is simply a method for finding a hyperplane that bisects two classes of data (labeled positive or negative).

Where w is an orthogonal vector that defines the orientation of hyperplane H, as shown in Figure 1. The sign of the inner product of w and each point, xi, can then be used to classify xi:
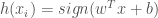


Figure 1: A hyperplane, H, that divides positive points (blue dots) and negative points (red triangles). The hyperplane’s orientation is defined by an orthogonal vector, w, which can be thought of as a vector of weights across d dimensions (in this case 3).
The Perceptron algorithm
To find the proper w for data set x, Perceptron uses the following steps:
- Start with an initial guess of w = 0
- Check to see if there are any misclassified points (ie. is yi(wTxi) > 0 for all xi?)
- If any point is found is to be misclassified, it is added to w, creating a new hyperplane
- With the updated w, loop through all points again checking for misclassification and update if necessary
- Continue until there are no misclassfied points remaining (ie the algorithm has converged)
It can be formally proven that if the data is linearly separable, Perceptron will converge in a finite number of updates.
I should note that while this discussion of perceptron has used geometric intuition to explain the algorithm (which is how professor Weinberger teaches it in his 4780 class and how I find it easiest to understand), many people conceptualize Perceptron as a step function and w as the weights for each input to this function. While this results in exactly the same thing as the above description, if you think this may be an easier way to understand, see this link.
Problems with Perceptron
While Perceptron does not suffer from the curse of dimensionality as K-NN does, it is still highly limited in its capabilities as it will never converge on data that is not linearly separable (such as the famous XOR problem demonstrated by Minsky and Papert). Luckily for us many more techniques have been developed to handle such data sets since the late 60’s when their book was written! Stay tuned for future posts for more machine learning topics.
References
1: “New Navy Device Learns By Doing” the New York Times, 7/8/1958 (These seem like fairly grandiose claims for such a small column, just saying)

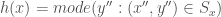






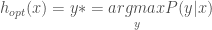
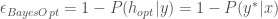

 In this specific example, we were able to discover that the National Agricultural Statistics Service has a raster dataset called the Cropland Data Layer that shows annual crop-specific land cover for the entire continental United States that was created using moderate-resolution satellite imagery and validated/corrected with agriculture ground truth. (Notably, CropScape has its own web-based GIS viewer, shown below)
In this specific example, we were able to discover that the National Agricultural Statistics Service has a raster dataset called the Cropland Data Layer that shows annual crop-specific land cover for the entire continental United States that was created using moderate-resolution satellite imagery and validated/corrected with agriculture ground truth. (Notably, CropScape has its own web-based GIS viewer, shown below)
 Source:
Source: 







{kind=link}
{kind=link}