
")
Creating a silent movie to tell a narrative is a powerful yet challenging endeavor. Perhaps with inspirations to create an eye-catching graphic for your social media followers or to better visualize intertemporal and interspatial changes, one can utilize GIFs to best meet their goals. However, with great (computational functionality and) power comes great responsibility. Creating a clean, minimalistic, and standalone graphic that quickly conveys information is key, so knowing what tips to follow along with a few linked tutorials will be a good starting point for creating your own effective animated visual.
I recently utilized a GIF in a presentation to show changes in perennial crop coverage in Kern County, CA alongside changes in drought intensity. While the GIF (shown at the end) wasn’t perfect, general tips for animation creation along with a quick critique to point out specific issues in the generated animation can help you when you plan out the creation of your own animation.
Considerations and Tips for Image Quality Control
Making an effective static graphic that easily conveys information without being overwhelming is tough, but creating a GIF can lead to disaster even faster than the blink of an eye. The most straightforward way to create your animation is to generate a incremental series of individual images you will be combining to create a short movie.
The main considerations for creating an effective movie visual is ensuring it is readable, engaging, and informative. The first question you should ask is whether the story you want to tell can be fully and effectively explained with a static image. If it can be, stop and make it before wasting your time on creating an animation.
Assuming you’ve passed the first step, it’s time to storyboard your visual. Draw out what you’re wanting to show so you have a template to follow. (If you find that what you’re wanting to animate can be effectively told with a static image, please revisit the previous paragraph.)
Much like a paper, there should be an introduction or orienting feature that allows the consumer to easily understand the thesis idea of the graphic at a glance in a standalone setting. With this key point in mind, driving the central theme of your graphic (likely) allows for the visual to appear randomly in public without fear of it being without a caption to fully tell a story.
Here is an example of a well-made, informative, and engaging GIF that shows how to make effective tables:
It is clear and to the point, stepping the audience through a range of steps in a clear and entertaining manner. It is well labeled, showing the author’s website, and is very concise in its messaging. Furthermore, it has been very memorable for me after initially seeing it on Twitter years ago.
This website has plenty of examples for effective animations that you could use for inspiration. Additionally, for those Pinterest users out there, DataGIFs has plenty of good examples. On Reddit, plenty of beautiful (and ugly) animated and static graphics alike appear on /r/dataisbeautiful. If you have a narrative to tell, there are likely similar animations that exist that you can use as a base to convey your tale.
With the big picture stuff out of the way, the next few points to consider can make or break your animation. While not every tip applies to every situation, covering them helps ensure your visual doesn’t have any glaring issues.
- Looping and Timing
- Make sure the timing of the gif isn’t too long or short.
- 20 seconds is generally the maximum recommended length for audience engagement
- Make sure there is enough time on each component of the GIF to be understood within two to three loops
- Ensure the individual frames can be read in a timely fashion
- Don’t have a jarring transition from the end of the GIF back to the start
- Make sure the first and last frames match up in style
- You can pull the user away from the original frame, but bring them back in since they’ll likely repeat the loop two to three times
- Consider starting with a base slide
- Individually add features so individuals are not overwhelmed
- Much like a slide presentation, if the reader is overwhelmed with too much information from the start, they are likely not going to understand the progression of the story being conveyed
- Slow is boring and may cause people to prematurely end their engagement with the animation
- Make sure the timing of the gif isn’t too long or short.
- Content Layout
- Consider the story you want to portray
- Much like any figure, ensuring the animation can stand alone and be posted online while out of context without killing its meaning is essential
- Select a “master frame” that is descriptive enough to be the “title slide” of the GIF—this is what will be seen when your slide deck is printed
- Image Manipulation
- For reproducibility, you should try to use scikit-image to edit reproducible figures as needed
- Definitely use Illustrator or Inkscape for fine tuning images
- If you have the choice to create a vector-based GIF over a raster-based GIF, go for the vector
- Consider using a transparent background unless the medium you’re presenting on might be distracting (e.g. a PowerPoint’s background overlaps with the animation)
- Consistent sizing and coloring
- Ensure labels are readable and are in the same location through all of the images. Having labels twitching between locations is distracting
- Framing of the edges of objects should not drift. If making a transition between different sizing (e.g. zooming out), ensure it is incremental and not shocking
- Customize components of a graphic to avoid bland experiences
- Effective colors
- Unless you’re artistically talents (i.e. not me), stick to generated color palates. ColorBrewer is a good resource
- Consider what your image might look like when printed out—try to make sure it converts well to grayscale. Note that generally the first image of a GIF’s sequence is what will be printed
- Watch out for colorblind individuals. They are people too and are worth catering to (use this website to ensure your images are compatible)
- The fewer, the better: selection of individual colors to make certain messages “pop” is worthwhile
- Fonts and Labels
- Give credit to yourself within the graphic
- Make sure that all words can be read at a glance
- If you plan to post the gif online, make sure individuals can get a decent idea of what’s going on before they blow it up
- Assume your image will be posted on twitter: consider making a dummy (private) account to make sure everything important is readable from the preview along with the actual gif being readable from a regular smartphone
- If distributing online, ensure the animation can be linked to a central website for citations/narratives/methods
- Resolution and Size
- Bigger is rarely better. Try to limit your size to around 1 MB max
- Size your GIF based on your platform. The size is not nearly as important if you’re using it in a presentation you keep on a jump drive compared to if you’re going to upload it online.
- Test your visual on multiple platforms (i.e. PowerPoint on another computer after moving the .ppt file) prior to use.
- If posting something that will be shared on Twitter, ensure the narrative of the GIF can be transferred when consumed on a mobile device. (~80% of all Twitter interactions come from a mobile devices)
- Creating the GIF
- Make sure your images aren’t too high of a resolution going into GIMP. It turns out that bigger isn’t always better
- I have run into issues with Python-based libraries creating GIFs with artifacts.
- I am a firm believer in spending a bit of extra time to follow this tutorial using GIMP to create your GIF
- Photoshop is the standard (tutorial), but it is not open source
- This post does a good job on showing how to make animated GIFs in R
Crop-Coverage Animation Critique
As mentioned above, I created a GIF to show changes in perennial crop coverage in Kern County, CA alongside changes in drought intensity. Each frame of the map was created in ArcGIS (which will eventually be migrated over to Python using Julie’s tutorial) and exported as a PNG while the graph along the bottom is a screenshot from the U.S. Drought Monitor. These individual images were combined, a black rectangle overlaying the graph was added, and then saved as a single image for each given year. I then used GIMP to combine, order, and create a GIF (tutorial link).
 The Good:
The Good:
- The timing of the picture sequence (~650 ms between frames) makes for easy reading
- The box highlighting the given year’s drought conditions along the bottom graphic is effective at pointing out current conditions
- Coupling the moving box with a clear title indicating the current year shows a natural progression through time
- It is relatively straightforward to see where in California Kern County is located
- The map includes a scale and north arrow to assist with orientation
- The pop-out box for California isn’t very intrusive
- The title is large and easy to read, with the given year being clearly indicated
- The data for the drought monitor is labeled as required by the source
The Bad:
- The title shifts a few pixels in a couple of frames
- The graph does not stretch to match the size of the entire GIF, making the graphic feel unbalanced
- There is too much white space in random locations
- The map itself could have been zoomed in a bit closer to leave out a lot of the white space in the eastern part of the county
- Having too much white space on the right side of the map makes the graphic feel even further imbalanced
- There is not a website on the GIF to indicate the author/creator (me)
The Ugly:
- The choice in color schemes on the map jump out in a bad way
- The districts drawn on the background map cannot be easily differentiated
- Using red as a plotted color can be a bit jarring and is not colorblind friendly
- The labels in the legend hop around and are not consistent for three (3) of the years
- The “master” or initial blank slide only has three categories while the rest of the slides have four
- The labeling for the graph is not clear (title, axes labels)
- The axis labels are blurry and small
Code showing how to make the drought monitor graphic graphic (with updates) is posted at this GitHub link. Note that the images were compiled into a GIF using GIMP. The revised graphic is shown below.

High definition images can be found on imgur here.

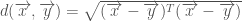 (1)
(1)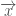 represents the attributes of our car and
represents the attributes of our car and  represents the attributes of another car.
represents the attributes of another car.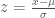 (2)
(2) and
and  are the mean and standard deviation of the observation variable, respectively.
are the mean and standard deviation of the observation variable, respectively.

 (3)
(3) is the covariance matrix of
is the covariance matrix of 









