
This post is a guest post by Veysel Yildiz from the University of Sheffield. Veysel is a third-year PhD student in Civil Engineering working with Dr. Charles Rouge (website). Veysel’s research contributes to scientific and technical advances in hydropower plant design. If you are interested in contributing a guest post to this blog, please contact Lillian Lau (lbl59@cornell.edu).
Like many engineers with a graduate education, I learned MATLAB first before realising Python could be a better language for code I want to make freely available. But contrary to most, I had already written a 2500-line piece of software in MATLAB before realising other programming languages would be better. My software, the HYPER toolbox is the first to simultaneously optimise plant capacity and turbine design parameters for new run-of-river hydropower plants (for more information, please follow this link). In my PhD, I have been improving this toolbox to also evaluate the financial robustness of hydropower plant design in a changing world, i.e., is a plant still a sensible investment when climate and socio-economic conditions are different? This is a key question in countries such as Turkey, where I am from, that are getting drier. I have also been making my toolbox faster through algorithmic improvements, and want to release this fast version in a license-free language.
While I was proficient in MATLAB, my knowledge of Python was limited. Fortunately, with the help of ChatGPT, I was able to successfully navigate the transition from MATLAB to Python, both for my toolbox and for myself. Indeed, I was not only able to convert the code but also gain valuable insights into Python programming. In this blog post, I will share my ChatGPT experience, its benefits, and offer some practical tips for using ChatGPT effectively in Python coding.
The challenge of transitioning from MATLAB to Python
MATLAB is a sophisticated numerical computing environment known for its ease of use and extensive libraries for a wide range of scientific and engineering applications. Python, on the other hand, has grown in popularity due to its adaptability, open-source nature, and diverse set of libraries and frameworks. Given the changing environment of software development and user demands, it was vital to make the switch from MATLAB to Python. The main challenges I faced during this transition are:
- Syntax Differences: MATLAB and Python have different syntax and conventions, making it challenging to convert code directly.
- Lack of Proficiency: I was not proficient in Python, which added to the complexity of the task.
- Code Size: With 2500 lines of code, the change could take several months.
- Performance: Python can be slower than MATLAB for certain tasks such as matrix computation.
How ChatGPT accelerated the process
ChatGPT, is a flexible large language model that can answer queries, generate code samples, and explain concepts in a variety of programming languages, including Python.
Here’s how ChatGPT helped me through this process:
Code Conversion Guidance
I started asking for basic functions including how to load/read a dataset. Then, I asked for guidance on how to convert specific functions and syntax from MATLAB to Python. ChatGPT provided clear explanations and Python code examples, helping me understand the nuances of Python syntax. For example:

ChatGPT guided me through the conversion process step by step. It assisted me in identifying and addressing syntactic differences, data structure changes, and library replacements needed to make the code run in Python. The conversion was not a one-time event. It involved continuous iterations and refinements. After implementing ChatGPT’s suggestions for one part of the code, I would return with additional questions as I progressed to the next steps. This iterative approach allowed me to build a solid foundation in Python while converting the MATLAB code. Here is an example:



Debugging and Error Handling
During the conversion process, I encountered errors and unexpected behaviour in the Python code. Whenever it happened, I input the error messages to ChatGPT to identify the causes of the errors. ChatGPT described Python’s error messages and traceback information, allowing me to handle difficulties on my own. In other words, it assisted in debugging by offering tricks for error detection and correction. Here is an example:

ValueError: Unable to parse string “EKİM” at position 0

Code Optimization
When I successfully create a script that runs, I often ask ChatGPT to suggest methods to optimize the Python code for performance and readability. Here is an example:


Learning Python Concepts
As I progressed in converting the code with the assistance of ChatGPT, I discovered that the journey was not just about code translation; it was an invaluable opportunity to learn essential Python concepts and best practices. ChatGPT was quite beneficial in taking me through this learning process, providing explanations on Python’s data types, control structures, and how to use libraries efficiently.

A Word of Caution
ChatGPT is a powerful AI language model, but it, like any other, has limits. It might sometimes offer inaccurate or unsatisfactory code suggestions or descriptions. As a user, you should take caution and systematically validate the information given by ChatGPT. Here is an example:


Several Key Takeaway Messages of the Journey
- Use clear instructions: When interacting with ChatGPT, provide clear and concise instructions. Describe the problem you’re trying to solve, the desired outcome, and any constraints or requirements. The more specific you are, the better the model’s response is likely to be.
- Understand its limitations: ChatGPT may not always produce perfect or optimal solutions. It is important to evaluate and verify the code created to ensure it meets your requirements.
- Review and validate generated code: Carefully review the code generated by ChatGPT. Check for accuracy, readability, and efficiency. Debug any issues that arise, and test the code with different inputs to ensure it works as expected.
- Iterative refinement: If the initial code generated by ChatGPT doesn’t meet your requirements, provide feedback and iterate. Ask for specific improvements or clarifications, and guide the model towards a better solution.
Conclusion
Through the guidance and support of ChatGPT, I successfully converted 2500 lines of MATLAB code to Python in 10 days. This accomplishment was a significant milestone in my programming journey. Along the way, I gained proficiency in Python, a skill that opened up new opportunities in data science, and more. This experience demonstrates the power of AI-driven tools in supporting programmers with challenging tasks while supporting continuous learning.
If you find yourself in a similar transition or coding challenge, try using AI-powered language models like ChatGPT to assist facilitate your journey and enrich your programming skills. It is not just about solving issues, but also about learning and growing as a programmer in a dynamic technological environment.
ChatGPT is a powerful tool to assist you with coding tasks, but it does not replace developing your own coding skills and actively engage in the learning process.



 is the frequency at which data for a time series is collected. It is equivalent to the inverse of the time difference between two consecutive data points,
is the frequency at which data for a time series is collected. It is equivalent to the inverse of the time difference between two consecutive data points,  . It has units of Hertz (
. It has units of Hertz (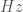 ). Higher values of
). Higher values of  is equal to
is equal to 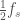 . As a rule of thumb, you should sample your time series at a frequency
. As a rule of thumb, you should sample your time series at a frequency  , as sampling at a higher frequencies will result in the time series signals overlapping. This is a phenomenon called aliasing, where t
, as sampling at a higher frequencies will result in the time series signals overlapping. This is a phenomenon called aliasing, where t . The value of
. The value of 


























