In this blog post, we will be reviewing how to perform runtime diagnostics using MOEAFramework. This software has been used in prior blog posts by Rohini and Jazmin to perform MOEA diagnostics across multiple MOEA parameterizations. Since then, MOEAFramework has undergone a number of updates and structure changes. This blog post will walk through the updated functionality of running MOEAFramework (version 4.0) via the command line to perform runtime diagnostics across 20 seeds using one set of parameters. We will be using the classic 3-objective DTLZ2 problem optimized using NSGAII, both of which are in-built into MOEAFramework.
Before we begin, some helpful tips and system configuration requirements:
Ensure that you have the latest version of Java installed (as of April 2024, this is Java Version 22). The current version of MOEAFramework was compiled using class file version 61.0, which was made available in Java Version 17 (find the complete list of Java versions and their associated class files here). This is the minimum requirement for being able to run MOEAFramework.
The following commands are written for a Linux interface. Download a Unix terminal emulator like Cygwin if needed.
Another helpful tip: to see all available flags and their corresponding variables, you can use the following structure:
For the a full list of parameter files for each of the in-built MOEAFramework algorithms, please see Jazmin’s post here.
In this example, I have called it NSGAII_Params.txt. Note that maxEvaluations is set to 10,000 on both its lower and upper bounds. This is because we want to fix the number of function evaluations completed by NSGAII. Next, in our command line, we run:
The output NSGAII_Latin file should contain a single-line that can be opened as a text file. It should have six tab-delineated values that correspond to the six parameters in the input file that you have generated. Now that you have your MOEA parameter files, let’s begin running some optimizations!
First, make a new folder in your current directory to store your output data. Here, I am simply calling it data.
mkdir data
Next, optimize the DTLZ2 3-objective problem using NSGAII:
for i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.RuntimeEvaluator --parameterFile NSGAII_Params.txt --input NSGAII_Latin --problem DTLZ2_3 --seed $i --frequency 1000 --algorithm NSGAII --output data/NSGAII_DTLZ2_3_$i.data; done
Here’s what’s going down:
First, you are performing a runtime evaluation of the optimization of the 3-objective DTLZ2 problem using NSGAII
You are obtaining the decision variables and objective values at every 1,000 function evaluations, effectively tracking the progress of NSGAII as it attempts to solve the problem
Finally, you are storing the output in the data/ folder
You then repeat this for 20 seeds (or for as many as you so desire).
Double check your .data file. It should contain information on your decision variables and objective values at every 1,000 NFEs or so, seperated from the next thousand by a “#”.
Generate the reference set
Next, obtain the only the objective values at every 1,000 NFEs by entering the following into your command line:
for i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.ResultFileMerger --problem DTLZ2_3 --output data/NSGAII_DTLZ2_3_$i.set --epsilon 0.01,0.01,0.01 data/NSGAII_DTLZ2_3_$i.data; done
Notice that we have a new flag here – the --epsilon flag tells MOEAFramework that you only want objective values that are at least 0.01 better than other non-dominated objective values for a given objective. This helps to trim down the size of the final reference set (coming up soon) and remove solutions that are only marginally better (and may not be decision-relevant in the real-world context).
On to generating the reference set – let’s combine all objectives across all seeds using the following command line directive:
for i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.ReferenceSetMerger --output data/NSGAII_DTLZ2_3.ref -epsilon 0.01,0.01,0.01 data/NSGAII_DTLZ2_3_$i.set; done
Your final reference set should now be contained within the NSGAII_DTLZ2_3.ref file in the data/ folder.
Generate the runtime metrics
Finally, let’s generate the runtime metrics. To avoid any mix-ups, let’s create a folder to store these files:
mkdir data_metrics
And finally, generate our metrics!
or i in {1..20}; do java -cp MOEAFramework-4.0-Demo.jar org.moeaframework.analysis.tools.ResultFileEvaluator --problem DTLZ2_3 --epsilon 0.01,0.01,0.01 --input data/NSGAII_DTLZ2_3_$i.data --reference data/NSGAII_DTLZ2_3.ref --output data_metrics/NSGAII_DTLZ2_3_$i.metrics; done
If all goes well, you should see 20 files (one each for each seed) similar in structure to the one below in your data_metrics/ folder:
The header values are the names of each of the MOEA performance metrics that MOEAFramework measures. In this blog post, we will proceed with visualizing the hypervolume over time across all 20 seeds.
Visualizing runtime diagnostics
The following Python code first extracts the metric that you would like to view, and saves the plot as a PNG file in the data_metrics/ folder:
If you correctly implemented the code, you should be able to be view the following figure that shows how the hypervolume attained by the NSGAII algorithm improves steadily over time.
In the figure above, the colored inner region spans the hypervolume attained across all 20 seeds, with the dotted line representing the mean hypervolume over time. The solid upper and lower bounding lines are the maximum and minimum hypervolume achieved every 1,000 NFEs respectively. Note that, in this specific instance, NSGAII only achieves about 50% of the total hypervolume of the overall objective space. This implies that a higher NFE (a longer runtime) is required for NSGAII to further increase the hypervolume achieved. Nonetheless, the rate of hypervolume increase is gradually decreasing, indicating that this particular parameterization of NSGAII is fast approaching its maximum possible hypervolume, which additional NFEs only contributing small improvements to performance. It is also worth noting the narrow range of hypervolume values, especially as the number of NFEs grows larger. This is representative of the reliability of the NGSAII algorithm, demonstrating that is can somewhat reliably reproduce results across multiple different seeds.
Summary
This just about brings us to the end of this blog post! We’ve covered how to perform MOEA runtime diagnostics and plot the results. If you are curious, here are some additional things to explore:
Plot different performance metrics against NFE. Please see Joe Kasprzyk’s post here to better understand the plots you generate.
Explore different MOEAs that are built into MOEAFramework to see how they perform across multiple seeds.
Generate multiple MOEA parameter samples using the in-built MOEAFramework Latin Hypercube Sampler to analyze the sensitivity of a given MOEA to its parameterization.
Attempt examining the runtime diagnostics of Borg MOEA using the updated version of MOEAFramework.
On that note, make sure to check back for updates as MOEAFramework is being actively reviewed and improved! You can view the documentation of Version 4.0 here and access its GitHub repository here.
In Parallel Programming Part 1, I introduced a number of basic OpenMP directives and constructs, as well as provided a quick guide to high-performance computing (HPC) terminology. In Part 2 (aka this post), we will apply some of the constructs previously learned to execute a few OpenMP examples. We will also view an example of incorrect use of OpenMP constructs and its implications.
TheCube Cluster Setup
Before we begin, there are a couple of steps to ensure that we will be able to run C++ code on the Cube. First, check the default version of the C++ compiler. This compiler essentially transforms your code into an executable file that can be easily understood and implemented by the Cube. You can do this by entering
g++ --version
into your command line. You should see that the Cube has G++ version 8.3.0 installed, as shown below.
Now, create two files:
openmp-demo-print.cpp this is the file where we will perform a print demo to show how tasks are distributed between threads
openmp-demo-access.cpp this file will demonstrate the importance of synchronization and the implications if proper synchronization is not implemented
Example 1: Hello from Threads
Open the openmp-demo-print.cpp file, and copy and paste the following code into it:
#include <iostream>
#include <omp.h>
#include <stdio.h>
int main() {
int num_threads = omp_get_max_threads(); // get max number of threads available on the Cube
omp_set_num_threads(num_threads);
printf("The CUBE has %d threads.\n", num_threads);
#pragma omp parallel
{
int thread_id = omp_get_thread_num();
printf("Hello from thread num %d\n", thread_id);
}
printf("Thread numbers written to file successfully. \n");
return 0;
}
Here is what the code is doing:
Lines 1 to 3 are the libraries that need to be included in this script to enable the use of OpenMP constructs and printing to the command line.
In main() on Lines 7 and 8, we first get the maximum number of threads that the Cube has available on one node and assign it to the num_threads variable. We then set the number of threads we want to use.
Next, we declare a parallel section using #pragma omp parallel beginning on Line 13. In this section, we are assigning the printf() function to each of the num_threads threads that we have set on Line 8. Here, each thread is now executing the printf() function independently of each other. Note that the threads are under no obligation to you to execute their tasks in ascending order.
Finally, we end the call to main() by returning 0
Be sure to first save this file. Once you have done this, enter the following into your command line:
This tells the system to compile openmp-demo-print.cpp and create an executable object using the same file name. Next, in the command line, enter:
./openmp-demo-print
You should see the following (or some version of it) appear in your command line:
Notice that the threads are all being printed out of order. This demonstrates that each thread takes a different amount of time to complete its task. If you re-run the following script, you will find that the order of threads that are printed out would have changed, showing that there is a degree of uncertainty associated with the amount of time they each require. This has implications for the order in which threads read, write, and access data, which will be demonstrated in the next example.
Example 2: Who’s (seg)Fault Is It?
In this example, we will first execute a script that stores each thread number ID into an array. Each thread then accesses its ID and prints it out into a text file called access-demo.txt. See the implementation below:
#include <iostream>
#include <omp.h>
#include <vector>
using namespace std;
void parallel_access_demo() {
vector<int> data;
int num_threads = omp_get_max_threads();
// Parallel region for appending elements to the vector
#pragma omp parallel for
for (int i = 0; i < num_threads; ++i) {
// Append the thread ID to the vector
data.push_back(omp_get_thread_num()); // Potential race condition here
}
}
int main() {
// Execute parallel access demo
parallel_access_demo();
printf("Code ran successfully. \n");
return 0;
}
As per the usual, here’s what’s going down:
After including the necessary libraries, we use include namespace std on Line 5 so that we can more easily print text without having to used std:: every time we attempt to write a statement to the output file
Starting on Line 7, we write a simple parallel_access_demo() function that does the following:
Initialize a vector of integers very creatively called data
Get the maximum number of threads available per node on the Cube
Declare a parallel for region where we iterate through all threads and push_back the thread ID number into the data vector
Finally, we execute this function in main() beginning Line 19.
If you execute this using a similar process shown in Example 1, you should see the following output in your command line:
Congratulations – you just encountered your first segmentation fault! Not to worry – this is by design. Take a few minutes to review the code above to identify why this might be the case.
Notice Line 15. Where, each thread is attempting to insert a new integer into the data vector. Since push_back() is being called in a parallel region, this means that multiple threads are attempting to modify data simultaneously. This will result in a race condition, where the size of data is changing unpredictably. There is a pretty simple fix to this, where we add a #pragma omp criticalbefore Line 15.
As mentioned in Part 1, #pragma omp critical ensures that each thread executes its task one at a time, and not all at once. It essentially serializes a portion of the parallel for loop and prevents race conditions by ensuring that the size of data changes in a predictable and controlled manner. An alternative would be to declare #pragma omp single in place of #pragma omp parallel foron Line 12. This essentially delegates the following for-loop to a single thread, forcing the loop to be completed in serial. Both of these options will result in the blissful outcome of
Summary
In this post, I introduced two examples to demonstrate the use of OpenMP constructs. In Example 1, I demonstrated a parallel printing task to show that threads do not all complete their tasks at the same time. Example 2 showed how the lack of synchronization can lead to segmentation faults due to race conditions, and two methods to remedy this. In Part 3, I will introduce GPU programming using the Python PyTorch library and Google Colaboratory cloud infrastructure. Until then, happy coding!
In my recent Applied High Performance Computing (HPC) lectures, I have been learning to better utilize OpenMP constructs and functions . If these terms mean little to nothing to you, welcome to the boat – it’ll be a collaborative learning experience. For full disclosure, this blog post assumes some basic knowledge of parallel programming and its related terminology. But just in case, here is a quick glossary:
Node: One computing unit within a supercomputing cluster. Can be thought of as on CPU unit on a traditional desktop/laptop.
Core: The physical processing unit within the CPU that enables computations to be executed. For example, an 11th-Gen Intel i5 CPU has four cores.
Processors/threads: Simple, lightweight “tasks” that can be executed within a core. Using the same example as above, this Intel i5 CPU has eight threads, indicating that each of its cores can run two threads simultaneously.
Shared memoryarchitecture: This means that all cores share the same memory within a CPU, and are controlled by the same operating system. This architecture is commonly found in your run-of-the-mill laptops and desktops.
Distributed memory architecture: Multiple cores run their processes independently of each other. They communicate and exchange information via a network. This architecture is more commonly found in supercomputer clusters.
Serial execution: Tasks and computations are completed one at a time. Typically the safest and most error-resistant form of executing tasks, but is the least efficient.
Parallel execution: Tasks and computations are completed simultaneously. Faster and more efficient than serial execution, but runs the risk of errors where tasks are completed out of order.
Synchronization: The coordination of multiple tasks or computations to ensure that all processes aligns with each other and abide by a certain order of execution. Synchronization takes up more time than computation. AN overly-cautious code execution with too many synchronization points can result in unnecessary slowdown. However, avoiding it altogether can result in erroneous output due to out-of-order computations.
Race condition: A race condition occurs when two threads attempt to access the same location on the shared memory at the same time. This is a common problem when attempting parallelized tasks on shared memory architectures.
Load balance: The distribution of work (tasks, computations, etc) across multiple threads. OpenMP implicitly assumes equal load balance across all its threads within a parallel region – an assumption that may not always hold true.
This is intended to be a two-part post where I will first elaborate on the OpenMP API and how to use basic OpenMP clauses to facilitate parallelization and code speedup. In the second post, I will provide a simple example where I will use OpenMP to delineate my code into serial and parallel regions, force serialization, and synchronize memory accesses and write to prevent errors resulting from writing to the same memory location simultaneously.
What is OpenMP?
OpenMP stands for “Open Specification for Multi-Processing”. It is an application programming interface (API) that enables C/C++ or Fortran code to “talk” (or interface) with multiple threads within and across multiple computing nodes on shared memory architectures, therefore allowing parallelism. It should not be confused with MPI (Message Passing Interface), which is used to develop parallel programs on distributed memory systems (for a detailed comparison, please refer to this set of Princeton University slides here). This means that unlike a standalone coding language like C/C++. Python, R, etc., it depends only on a fixed set of simple implementations using lightweight syntax (#pragma omp [clause 1] [clause 2]) . To begin using OpenMP, you should first understand what it can and cannot do.
Things you can do with OpenMP
Explicit delineation of serial and parallel regions
One of the first tasks that OpenMP excels at is the explicit delineation of your code into serial and parallel regions. For example:
In the code block above, we are delineating an entire parallel region where the task performed by the do_a_parallel_task() function is performed independently by each thread on a single node. The number of tasks that can be completed at any one time depends on the number of threads that are available on a single node.
Hide stack management
In addition, using OpenMP allows you toautomate memory allocation, or “hide stack management”. Most machines are able to read, write, and (de)allocate data to optimize performance, but often some help from the user is required to avoid errors caused by multiple memory access or writes . OpenMP allows the user to automate stack management without explicitly specifying memory reads or writes in certain cache locations via straightforward clauses such as collapse() (we will delve into the details of such clauses in later sections of this blog post).
Allow synchronization
OpenMP also provides synchronization constructs to enforce serial operations or wait times within parallel regionsto avoid conflicting or simultaneous read or write operations where doing so might result in erroneous memory access or segmentation faults. For example, a sequential task (such as a memory write to update the value in a specific location) that is not carefully performed in parallel could result in output errors or unexpected memory accessing behavior. Synchronization ensures that multiple threads have to wait until the last operation on the last thread is completed, or only one thread is allowed to perform an operation at a time. It also protects access to shared data to prevent multiple reads (false sharing). All this can be achieved via the critical, barrier, or single OpenMP clauses.
Creating a specific number of threads
Unless explicitly stated, the system will automatically select the number of threads (or processors) to use for a specific computing task. Note that while you can request for a certain number of threads in your environment using export OMP_NUM_THREADS, the number of threads assigned to a specific task is set by the system unless otherwise specified. OpenMP allows you to control the number of threads you want to use in a specific task in one of two ways: (a) using omp_set_num_threads() and using (b) #pragma omp parallel [insert num threadshere]. The former allows you to enforce an upper limit of the number of threads to be freely assigned to tasks throughout the code, while the latter allows you to specify a set number of threads to perform an operation(s) within a parallel region.
In the next section, we will list some commonly-used and helpful OpenMP constructs and provide examples of their use cases.
OpenMP constructs and their use cases
OMP_NUM_THREADS This is an environment variable that can be set either in the section of your code where you defined your global variables, or in the SLURM submission script you are using to execute your parallel code.
omp_get_num_threads() This function returns the number of threads currently executing the parallel region from which it is called. Use this to gauge how many active threads are being used within a parallel region
omp_set_num_threads() This function specifies the number of threads to use for any following parallel regions. It overrides the OMP_NUM_THREADS environment variable. Be careful to not exceed the maximum number of threads available across all your available cores. You will encounter an error otherwise.
omp_get_max_threads() To avoid potential errors from allocating too many threads, you can use omp_set_num_threads() with omp_get_max_threads(). This returns the maximum number of threads that can be used to form a new “team” of threads in a parallel region.
#pragma omp parallel This directive instructs your compiler to create a parallel region within which it instantiates a set (team) of threads to complete the computations within it. Without any further specifications, the parallelization of the code within this block will be automatically determined by the compiler.
#pragma omp for Use this directive to instruct the compiler to parallelize for-loop iterations within the team of threads that it has instantiated. This directive is often used in combination with #pragma omp parallel to form the #pragma omp parallel for construct which both creates a parallel region and distributes tasks across all threads.
To demonstrate:
#include <stdio.h>
#include <omp.h>
void some_function() {
#pragma omp parallel {
#pragma omp for
for (int i = 0; i < some_num; i++) {
perform_task_here();
}
}
}
is equivalent to
#include <stdio.h>
#include <omp.h>
void some_function() {
#pragma omp parallel for {
for (int i = 0; i < some_num; i++) {
perform_task_here();
}
}
#pragma omp barrier This directive marks the start of a synchronization point. A synchronization point can be thought of as a “gate” at which all threads must wait until all remaining threads have completed their individual computations. The threads in the parallel region beyond omp barrier will not be executed until all threads before is have completed all explicit tasks.
#pragma omp single This is the first of three synchronization directives we will explore in this blog post. This directive identifies a section of code, typically contained within “{ }”, that can only be run with one thread. This directive enforces serial execution, which can improve accuracy but decrease speed. The omp single directive imposes an implicit barrier where all threads after #pragma omp single will not be executed until the single thread running its tasks is done. This barrier can be removed by forming the #pragma omp single nowait construct.
#pragma omp master This directive is similar to that of the #pragma omp single directive, but chooses only the master thread to run the task (the thread responsible creating, managing and discarding all other threads). Unlike #pragma omp single, it does not have an implicit barrier, resulting in faster implementations. Both #pragma omp single and #pragma omp master will result in running only a section of code once, and it useful for controlling sections in code that require printing statements or indicating signals.
#pragma omp critical A section of code immediate following this directive can only be executed by one thread at a time. It should not be confused with #pragma omp single. The former requires that the code be executed by one thread at a time, and will be executed as many times as has been set byomp_set_num_threads(). The latter will ensure that its corresponding section of code be executed only once. Use this directive to prevent race conditions and enforce serial execution where one-at-a-time computations are required.
Things you cannot (and shouldn’t) do with OpenMP
As all good things come to an end, all HPC APIs must also have limitations. In this case, here is a quick rundown in the case of OpenMP:
OpenMP is limited to function on shared memory machines and should not be run on distributed memory architectures.
It also implicitly assumes equal load balance. Incorrectly making this assumption can lead to synchronization delays due to some threads taking significantly longer to complete their tasks compared to others immediately prior to a synchronization directive.
OpenMP may have lower parallel efficiency due to it functioning on shared memory architectures, eventually being limited by Amdahl’s law.
It relies heavily on parallelizable for-loops instead of atomic operations.
Summary
In this post, we introduced OpenMP and a few of its key constructs. We also walked through brief examples of their use cases, as well as limitations of the use of OpenMP. In our next blog post, we will provide a tutorial on how to write, compile, and run a parallel for-loop on Cornell’s Cube Cluster. Until then, feel free to take a tour through the Cornell Virtual Workshop course on OpenMP to get a head start!
In this blog post, we will be discussing the many household uses of citrus aurantiifolio, or the common lime.
Just kidding, we’ll be talking about a completely different type of LIME, namely Local Interpretable Model-Agnostic Explanations (at this point you may be thinking that the former’s scientific name becomes the easier of the two to say). After all, this is the WaterProgramming blog.
On a more serious note though, LIME is one of the two widely-known model agnostic explainable AI (xAI) methods, alongside Shapley Additive Explanations (SHAP). This post is intended to be an introduction to LIME in particular, and we will be setting up the motivation for using xAI methods as well as a brief example application using the North Carolina Research Triangle system.
Before we proceed, here’s a quick graphic to get oriented:
The figure above mainly demonstrates three main concepts: Artificial Intelligence (AI), the methods used to achieve AI (one of which includes Machine Learning, or ML), and the methods to explain how such methods achieved their version of AI (explainable AI, or more catchily known as xAI). For more explanation on the different categories of AI, and their methods, please refer to these posts by IBM’s Data Science and AI team and this SpringerLink book by Sarker (2022) respectively.
Model-agnostic vs model-specific
Model-specific methods
As shown in the figure, model-specific xAI methods are techniques that can only be used on the specific model that it was designed for. Here’s a quick rundown of the type of model and their available selection of xAI methods:
Decision trees
Decision tree visualization (e.g. Classification and Regression Tree (CART) diagrams)
Feature importance rankings
Neural networks (NN), including deep neural networks
Further information on the mathematical formulation for these methods can be found in Holzinger et al (2022). Such methods account for the underlying structure of the model that they are used for, and therefore require some understanding of the model formulation to fully comprehend (e.g. interpreting NN activation visualizations). While less flexible than their agnostic counterparts, model-specific xAI methods provide more granular information on how specific types of information is processed by the model, and therefore how changing input sequences, or model structure, can affect model predictions.
Model-agnostic methods
Model-agnostic xAI (as it’s name suggests) relies solely on analyzing the input-output sets of a model, and therefore can be applied to a wide range of machine learning models regardless of model structure or type. It can be thought of as (very loosely) as sensitivity analysis, but applied to AI methods (for more information on this discussion, please refer to Scholbeck et al. (2023) and Razavi et al. (2021)). SHAP and LIME both fall under this set of methods, and approximately abide by the following process: perturb the input then identify how the output is changed. Note that this set of methods provide little insight as to the specifics of model formulation and how it affects model predictions. Nonetheless, it affords a higher degree of flexibility, and does not bind you to one specific model.
Why does this matter?
Let’s think about this in the context of water resources systems management and planning. Assume you are a water utility responsible for ensuring that you reliably deliver water to 280,000 residents on a daily basis. In addition, you are responsible for planning the next major water supply infrastructure project. Using a machine learning model to inform your short- and long-term management and planning decisions without interrogating how it arrived at its recommendations implicitly assumes that the model will make sensible decisions that balance all stakeholders’ needs while remaining equitable. More often than not, this assumption can be incorrect and may lead to (sometimes funny but mostly) unintentional detrimental cascading implications on the most vulnerable (for some well-narrated examples of how ML went awry, please refer to Brian Christian’s “The Alignment Problem”).
Having said that, using xAI as a next step in the general framework of adopting AI into our decision-making processes can help us better understand why a model makes its predictions, how those predictions came to be, and their degree of usefulness to a decision maker. In this post, I will be demonstrating the use of LIME to answer the following questions.
The next section will establish the three components we will need to apply LIME to our problem:
An input (feature) set and the training dataset
The model predictions
The LIME explainer
A quick example using the North Carolina Research Triangle
The input (feature) set and training dataset
The Research Triangle region in North Carolina consists of six main water utilities that deliver water to their namesake cities: OWASA (Orange County), Durham, Cary, Raleigh, Chatham, and Pittsboro (Gold et al., 2023). All utilities have collaboratively decided that they will each measure their system robustness using a satisficing metric (Starr 1962; Herman et al. 2015), where they satisfy their criteria for robustness if the following criteria are met:
Their reliability meets or exceeds 98%
Their worst-case cost of drought mitigation actions amount to no more than 10% of their annual volumetric revenue
They do not restrict demand more than 20% of the time
If all three criteria are met, then they are considered “successful” (represented as a 1). Otherwise, they have “failed” (represented as a 0). We have 1,000 training data points of success or failure, each representing a state of the world (SOW) in which a utility fails or succeeds to meet their satisficing critieria. This is our training dataset. Each SOW consists of a unique combination of features that include inflow, evaporation and water demand Fourier series coefficients, as well as socioeconomic, policy and infrastructure construction factors. This is our feature set.
Feel free to follow along this portion of the post using the code available in this Google Colab Notebook.
The model prediction
To generate our model prediction, let’s first code up our model. In this example, we will be using Extreme Gradient Boosting, otherwise known as XGBoost (xgboost) as our prediction model, and the LIME package. Let’s first install the both of them:
pip install lime
pip install xgboost
We will also need to import all the needed libraries:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import lime
import lime.lime_tabular
import xgboost as xgb
from copy import deepcopy
Now let’s set up perform XGBoost! We will first need to upload our needed feature and training datasets:
satisficing = pd.read_csv('satisficing_all_utilites.csv')
du_factors = pd.read_csv('RDM_inputs_final_combined_headers.csv')
# get all utility and feature names
utility_names = satisficing.columns[1:]
du_factor_names = du_factors.columns
There should be seven utility names (six, plus one that represents the entire region) and thirteen DU factors (or feature names). In this example, we will be focusing only on Pittsboro.
# select the utility
utility = 'Pittsboro'
# convert to numpy arrays to be passed into xgboost function
du_factors_arr = du_factors.to_numpy()
satisficing_utility_arr = satisficing[utility].values
# initialize the figure object
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
perform_and_plot_xbg(utility, ax, du_factors_arr, satisficing_utility_arr, du_factor_names)
Note the perform_and_plot_xgb function being used – this function is not shown here for brevity, but you can view the full version of this function in this Google Colab Notebook.
The figure above is called a factor map that shows mid-term (Demand2) and long-term (Demand3) demand growth rates on its x- and y-axes respectively. The green denotes the range of demand growth rates where XGBoost has predicted that Pittsboro will successfully meet its satisficing criteria, and brown is otherwise. Each point is a sample from the original training dataset, where the color (white is 1 – success, and red is 0 – failure) denotes whether Pittsboro actually meets its satisficing criteria. In this case we can see that Pittsboro quickly transitions in failure when its mid- and long-term demand are both higher than expected (indicated by the 1.0-value on both axes).
The LIME explainer
Before we perform LIME, let’s first select an interesting point using the figure above.
In the previous section, we can see that the XGBoost algorithm predicts that Pittsboro’s robustness is affected most by mid-term (Demand2) and long-term (Demand3) demand growth. However, there is a point (indicated using the arrow and the brown circle below) where this prediction did not match the actual data point.
To better understand why then, this specific point was predicted to be a “successful” SOW where the true datapoint had it labeled as a “failure” SOW, let’s take a look at how the XGBoost algorithm made its decision.
The following code, if run successfully, should result in the following figure.
Here’s how to interpret it:
The prediction probability bars on the furthest left show the model’s prediction. In this case, the XGBoost model classifies this point as a “failure” SOW with 94% confidence.
The tornado plot in the middle show the feature contributions. In this case, it shows the degree to which each SOW feature influenced the decision. In this case, the model misclassified the data point as a “success” although it was a failure as our trained model only accounts for the top two overall features that influence the entire dataset to plot the factor map, and did not account for short-term demand growth rates (Demand1) and the permitting time required for constructing the water treatment plant (JLWTP permit).
The table on the furthest right is the table of the values of all the features of this specific SOW.
Using LIME has therefore enabled us to identify the cause of XGBoost’s misclassification, allowing us to understand that the model needed information on short-term demand and permitting time to make the correct prediction. From here, it is possible to further dive into the types of SOWs and their specific characteristics that would cause them to be more vulnerable to short-term demand growth and infrastructure permitting time as opposed to mid- and long-term demand growth.
Summary
Okay, so I lied a bit – it wasn’t quite so “brief” after all. Nonetheless, I hope you learned a little about explainable AI, how to use LIME, and how to interpret its outcomes. We also walked through a quick example using the good ol’ Research Triangle case study. Do check out the Google Colab Notebook if you’re interested in how this problem was coded.
With that, thank you for sticking with me – happy learning!
Christian, B. (2020). The alignment problem: Machine Learning and human values. Norton & Company.
Gold, D. F., Reed, P. M., Gorelick, D. E., & Characklis, G. W. (2023). Advancing Regional Water Supply Management and infrastructure investment pathways that are equitable, robust, adaptive, and cooperatively stable. Water Resources Research, 59(9). https://doi.org/10.1029/2022wr033671
Herman, J. D., Reed, P. M., Zeff, H. B., & Characklis, G. W. (2015). How should robustness be defined for water systems planning under change? Journal of Water Resources Planning and Management, 141(10). https://doi.org/10.1061/(asce)wr.1943-5452.0000509
Holzinger, A., Saranti, A., Molnar, C., Biecek, P., & Samek, W. (2022). Explainable AI methods – A brief overview. xxAI – Beyond Explainable AI, 13–38. https://doi.org/10.1007/978-3-031-04083-2_2
Scholbeck, C. A., Moosbauer, J., Casalicchio, G., Gupta, H., Bischl, B., & Heumann, C. (2023, December 20). Position paper: Bridging the gap between machine learning and sensitivity analysis. arXiv.org. http://arxiv.org/abs/2312.13234
Starr, M. K. (1963). Product design and decision theory. Prentice-Hall, Inc.
In this post, we will continue where we left off from Part 1, in which we set up a two-stage stochastic programming problem to identify the optimal decision for the type of water supply infrastructure to build. As a recap, our simple case study involves a small water utility servicing the residents of Helm’s Keep (population 57,000) to identify the following:
The best new water supply infrastructure option to build
Its final built capacity
The total bond payment to be made
The expected daily deliveries that ‘ its final built capacity
The expected daily deliveries that it needs to meet
To identify these values, we will be setting up a two-stage stochastic problem using the Python cvxpy library. In this post, we will first review the formulation of the problem, provide information on the installation and use of the cvxpy library, and finally walk through code to identify the optimal solution to the problem.
Reviewing the infrastructure investment selection problem
In our previous post, we identified that Helm’s Keep would like to minimize their infrastructure net present cost (INPC), giving the following objective function:
where
and are the total number of infrastructure options and potential future scenarios to consider
is the probability of occurrence for scenario
is one year within the entire bond term
is the total bond payment, or bond principal
is the discount rate in scenario for infrastructure option
In achieving this objective, Helm’s Keep also has to abide by the following constraints:
where
is the final built capacity of infrastructure option
is a binary variable indicating if an infrastructure option is built (1) or not (0)
is the daily demand in scenario
is the daily water deliveries from infrastructure option in scenario
is the ratio of non-revenue water (NRW) if infrastructure option is built
is the net revenue from fulfilling demand (after accounting for NRW) using infrastructure option in scenario
For the full formulations of and , please refer to Part 1 of this tutorial.
In this problem, we our first-stage decision variables are the infrastructure option to build and its final built capacity. Our second-stage decision variables are the daily water deliveries made in each scenario .
The CVXPY Python library
To solve this problem, we will be using Python’s cvxpy library for convex optimization. It is one of the many solvers available for performing convex optimization in Python including Pyomo, as demonstrated in Trevor’s earlier blog post. Some other options options include PuLP, scipy.optimize, and Gurobi. For the purposes of our specific application, we will be using cvxpy as it can interpret lists and dictionaries of variables, constraints, or objectives. This allows direct appending and retrieval of said objects. This feature therefore makes it convenient to use with for-loops, which are useful in the case of two- or multi-stage stochastic problems where the decision variable space can exponentially grow with the number of scenarios or options being considered. You can find an introduction to cvxpy, documentation, and examples at the CVXPY website.
If you use pip, you can install cvxpy using the following:
pip install cvxpy
To install specific solver names, you can alternatively install cvxpy using
Once you’ve installed cvxpy, you’re ready to follow along the next part!
Solving the two-stage stochastic programming problem
First, we import the cvxpy library into our file and define the constants and helper functions to calculate the values of and
import cvxpy as cp
# define constants
households = 57000 # number of households
T = 30 # bond term (years) for an infrastructure option
UR = 0.06 # the uniform water rate per MGD
def calculate_pmt(br, C_i, y_i, VCC_i, x_i, T=30):
"""Calculate the annual payment for a loan.
Args:
br (float): The annual interest rate.
C_i (float): capital cost of infrastructure option i
y_i (boolean): 1 if option i is built, 0 if not
VCC_i (float): variable capital cost of infrastructure option i
x_i (float): final built capacity of infrastructure option i
T (const): T=30 years, the bond term in years.
Returns:
float: The annual payment amount.
"""
# calculate p_i, the bond principal (total value of bond borrowed) for
# infrastructure option i
p_i = (C_i*y_i) + (VCC_i * x_i)
# Convert the annual interest rate to a monthly rate.
pmt = p_i*(br*(1+br)**T)/(((1+br)**T)-1)
# Calculate the monthly payment.
return pmt
def calculate_R(D_i, rho_i, VOC_i, households=57000, UR=0.06):
"""
Calculates the potential net revenue from infrastructure option i in a given scenario.
Args:
D_i (float): per-capita daily water demand in MGD
rho_i (float): percentage of water lost during transmission (non-revenue water, NRW) from infrastructure i to the city
VOC_i (float): variable operating cost of i
households (const): households=57000 the number of households in the city
UR (const): UR=0.06/MGD the per-household uniform water rate
Returns:
R_i (float): The potential net revenue from infrastructure option i in a given scenario.
"""
OC_i = VOC_i * (D_i/rho_i)
R_i = ((D_i * UR * households)*(1-rho_i)) - OC_i
return R_i
Then, we define all the variables required. We will first define the first-stage decision variables:
# Infrastructure options as boolean (1, 0) variables
y1 = cp.Variable(boolean = True, name='y1')
y2 = cp.Variable(boolean = True, name='y2')
y3 = cp.Variable(boolean = True, name='y3')
# capacity of each infrastructure option
x1 = cp.Variable(nonneg=True, name = 'x1')
x2 = cp.Variable(nonneg=True, name = 'x2')
x3 = cp.Variable(nonneg=True, name = 'x3')
# infrastructure option parameters
C = [15.6, 11.9, 13.9] # capital cost of each infrastructure option in $mil
VCC = [7.5, 4.7, 5.1] # variable capital cost of each infrastructure option in $mil/MGD capacity
VOC = [0.2, 0.5, 0.9] # variable operating cost of each infrastructure option in $mil/MGD
NRW = [0.2, 0.1, 0.12] # non-revenue water (NRW) for each infrastructure option
Next, we define the second-stage decision variable and the parameter values related to each potential scenario:
# volume of water delivered to the city in each scenario
D = {}
for i in range(3):
D[i] = cp.Variable(nonneg=True)
P = [0.35, 0.41, 0.24] # probability of each scenario
demand_increase = [4.4, 5.2, 3.9] # per-capita daily demand increase in MGD
bond_rate = [0.043, 0.026, 0.052] # bond rate in each scenario
discount_rate = [0.031, 0.026, 0.025] # discount rate in each scenario
Note the for loop in the Lines 2-4 of the code snippet above. The cvxpy enables variables to be added to and accessed via a dictionary that allows access via both explicit and in-line for loop, as we will see below in the objective function code definition:
min_inpc = sum(P[s]*sum((calculate_pmt(bond_rate[s], C[0], y1, VCC[0], x1)/((1+discount_rate[s])**t)) for t in range(1,T+1)B) for s in range(3)) + \
sum(P[s]*sum((calculate_pmt(bond_rate[s], C[0], y2, VCC[1], x2)/((1+discount_rate[s])**t)) for t in range(1,T+1)) for s in range(3)) + \
sum(P[s]*sum((calculate_pmt(bond_rate[s], C[2], y3, VCC[2], x3)/((1+discount_rate[s])**t)) for t in range(1,T+1)) for s in range(3))
Some explanation is required here. Our goal is to find the minimum INPC required to build the supply required to meet potential demand growth. Our objective function formulation therefore is the sum of the INPC of all three potential infrastructure options, each calculated across the three scenarios. As the variable is binary, only the sum across the three scenarios that requires the optimal infrastructure option will be chosen.
To constrain the solution space of our objective function, we define our constraints. Below, we can see the application of the ability of the cvxpy library that allows constraints to be added iteratively to a list:
constraints = []
# set an arbitrarily large value for M
M = 10e12
for s in range(3):
constraints += [D[s] >= demand_increase[s]] # daily water deliveries must be more than or equal to daily demand increase
constraints += [D[s] <= ((x1/0.1) + (x2/0.1) + (x2/0.12))/1.2]
constraints += [calculate_pmt(bond_rate[s], C[0], y1, VCC[0], x1) <= 1.25*calculate_R(demand_increase[s], NRW[0], VOC[0])]
constraints += [calculate_pmt(bond_rate[s], C[1], y2, VCC[1], x2) <= 1.25*calculate_R(demand_increase[s], NRW[1], VOC[1])]
constraints += [calculate_pmt(bond_rate[s], C[2], y3, VCC[2], x3) <= 1.25*calculate_R(demand_increase[s], NRW[2], VOC[2])]
constraints += [y1 + y2 + y3 == 1]
constraints += [x1 <= M * y1]
constraints += [x2 <= M * y2]
constraints += [x3 <= M * y3]
Finally, we solve the problem using the Gurobi solver. This solver is selected as it comes pre-installed with the cvxpy library and does not require additional steps or licensing during installation. We also print the objective value and the solutions to the problem:
# set up the problem as a minimization
problem = cp.Problem(cp.Minimize(min_inpc), constraints)
# solve using Gurobi
problem.solve(solver=cp.GUROBI, verbose=False)
print(f'Optimal INPC: ${problem.value} mil' )
for variable in problem.variables():
print(f"{variable.name()} = {variable.value}")
Obtaining the solutions
If you have closely followed the steps shown above, you would have identified that Helm’s Keep should build Infrastructure Option 3(a new groundwater pumping station), to a total built capacity that allows total expected daily deliveries of 3.27MGD. This will result in a final INPC of USD$35.62 million. There are our first-stage decision variables.
In each scenario, the following daily deliveries (second-stage decision variables) should be expected:
Scenario
Scenario probability (%)
Demand increase (MGD)
Daily deliveries (MGD)
1
35
4.4
5.5
2
41
5.2
6.5
3
24
3.9
4.875
The values from the second and third column can be found in Part 1 of this tutorial. The final daily deliveries account for the maximum possible portion of NRW.
Let’s identify how much Helm’s Keep will require to pay in total annual bond payments and how much their future expected daily deliveries will be:
total_bond_payment = sum(P[s]*calculate_pmt(bond_rate[s], C[1], 1, VCC[1], x2.value) for s in range(3))
expected_daily_deliveries = sum(P[s]*D[s].value for s in range(3))
If you have closely followed the steps shown above, you would have obtained the following values:
Total annual bond payment
USD$1.55 million
Expected total daily water deliveries
5.76 MGD
Conclusion
Congratulations – you just solved a two-stage programming stochastic programming problem! In this post, we reviewed the content of Part 1, and provided a quick introduction to the cvxpy Python library and justified its use for the purpose of this test case. We also walked through the steps required to solve this problem in Python, identified that it should build a new groundwater pumping station with a 3.27MGD capacity. We also identified the total annual amount Helm’s Keep would have to pay annually to fulfill its debt service requirements, and how much it water would, on average, be expected to provide for its constituents.
I hope that both Parts 1 and 2 provided you with some information on what stochastic programming is, when to use it, and some methods that might be useful to approach it. Thank you for sticking around and happy learning!
Stochastic programming (SP) is an approach to decision-making under uncertainty (alongside robust optimization and chance constrained optimization). It is an extension of deterministic optimization techniques such as linear (or non-linear) programming that incorporates stochastic elements (hence the name) in the form of multiple potential future scenarios. Overall, the aim of stochastic programming is to identify optimal solutions to a given problem that perform well under a finite range of possible scenarios. This is done by optimizing the expected value of the objective function over all scenarios. For clarification, a “scenario” in the context of SP is defined as the combined realization (expected outcome) of all future uncertainties.
There are two versions of an SP problem: the two-stage SP problem consists of two decision-making stages, where the first stage decisions represent the decisions taken before the uncertainty (the future scenario, in this case) unfolds and becomes known. The second stage decisions are taken once the future has unfolded and corrective action needs to be taken. Two-stage SP problems are typically used for scenario planning, where a decision-maker’s goal is to identify a solution that will result in good performance across all potential scenarios. Next, the multi-stage SP problem with -stages is an extension of the two-stage SP problem, where the decision at stage is dependent on all decisions made up until . Due to the problem’s high dimensionality, the multi-stage SP problem is typically represented using a scenario tree with each branch associated with a probable outcome and its probability and each level associated with a stage .
In this post, I will provide a two-stage stochastic programming example discuss the pros and cons of its use. In the following post, I will and demonstrate how to approach and solve such a problem using the Python cvxpy library.
The infrastructure selection example
Disclaimer: All values are arbitrary .
A water utility serving the residents of Helm’s Keep (57,000 households) are deciding on a water supply storage expansion project to meet projected increase in demand and wants to identify a suitable yet affordable project to invest in:
Option 1: Water treatment capacity expansion on the distant (but yet untapped) Lake Heleborn
Option 2: The construction of small local reservoir on the outskirts of Helm’s Keep
Option 3: Construction of a new groundwater pumping station
Each of these infrastructure options are associated with the following capital investment costs. The variable capital cost and variable operating cost are functions of the infrastructure options and expected demand (both in MGD).
Fixed capital cost ($mil)
Variable capital cost ($mil/MGD capacity)
Variable operating cost ($mil/MGD demand)
Option 1
15.6
7.5
0.2
Option 2
11.9
4.7
0.5
Option 3
13.9
5.1
0.9
Helm’s Keep’s priority in the selection of its new water supply infrastructure is to minimize its total infrastructure net present cost:
where is the infrastructure net present cost, is bond term for an infrastructure option, and is the discount rate for a given year of debt service payment for an infrastructure option since its bond was issued. The value of is calculated as follows:
where is the bond principal (the total value of the bond), is the bond interest rate to be paid to the creditor throughout the bond term . All payments are discounted to their present value. The value of the bond principal is dependent on the capacity of the infrastructure option and is calculated as a function of the fixed and variable capital costs:
such that is the capital cost of infrastructure option and is a binary variable indicating if option is chosen. is the variable capital cost of infrastructure option , and is the final built capacity of .
In addition, there is some water loss in transporting water from either location due to aging infrastructure, which will result in losses caused by non-revenue water (NRW). The losses associated with option are listed below:
Option 1: 20% water loss
Option 2: 10% water loss
Option 3: 12% water loss
Helm’s Keep must also consider the debt is undertaking relative to its potential annual net revenue , calculated as follows:
where is per-capita daily water delivered, is the per-household uniform water rate, and is the percentage of water lost during transmission given that infrastructure was chosen. is Helm’s Keep’s daily operating costs per capita where
such that is the demand in scenario for infrastructure option , is the variable operating cost of , and is the percentage of NRW.
However, it must also meet the following constraints:
The infrastructure option decision is exclusive (only one option can be selected).
The total capacity of the chosen infrastructure option cannot be less than 1.2 times that of daily demand increase (after accounting for NRW).
Daily deliveries be at least equal to demand (after accounting for NRW).
All water produced (after accounting for NRW) are considered for-revenue water and result in gross revenue.
Annual payments should not exceed 1.25 times that of Helm’s Keep’s annual net revenue .
There are three possible scenarios of water demand increase , Federal Reserve bond interest rate, and discount rate. The probability of each scenario is listed in the table below:
Scenarios
Demand increase (MGD)
Bond rate (%)
Discount rate (%)
Probability (%)
Scenario 1
4.4
4.3
3.1
0.35
Scenario 2
5.2
2.6
2.6
0.41
Scenario 3
3.9
5.2
2.5
0.24
Helm’s Keep faces the following decisions:
Stage 1: Which infrastructure option to build and to what capacity for ?
Stage 2: How much will Helm’s Keep’s corresponding bond principal be how much water is delivered in each scenario?
Formulating the problem
Let the first-stage decision variables be:
Infrastructure option selection where and
Capacity of each infrastructure option
Next, we set up the second stage decision variables. Let , and be the amount of water delivered, bond rate, and discount rate, in scenario . This will result in the following problem setup:
where
with constraints
such that
and is the probability of scenario and .
Some caveats
As we walked through the formulation of this two-stage stochastic programming problem, it quickly becomes apparent that the computational complexity of such an approach can quickly become intractable when the number of uncertain scenarios and the complexity of the model (large number of uncertain parameters) is high. In addition, this approach assumes a priori knowledge of future uncertainty and sufficient underlying expert knowledge to generate 6uncertainty estimates, which cannot guarantee that the theoretical robustness of the identified solution to real world outcomes if the estimated uncertainty does not match the estimated uncertainty. We can see that this method may therefore be best suited for problems where uncertainty can be accurately characterized and modeled as random variables or scenarios. It is nonetheless a useful approach for addressing problems in manufacturing, production line optimization, financial portfolio design, etc, where data is abundant and uncertainty is well-characterized, and then identifying solutions that perform well across a finite number of scenarios.
In this post, we covered an introduction to stochastic programming and provided a 2-stage infrastructure investment selection example to demonstrate the method’s key concepts. In the next post, we will walk through the installation and use of the Python cvxpy library and use it to solve this problem to identify the most suitable infrastructure option to invest in, its final built capacity, and its total demand fulfilled.
In this post, we will be performing time-varying sensitivity analysis (TVSA) to assess how the use of information from reservoir storage and downstream city levels change across time when attempting to meet competing objectives in the Red River basin. This exercise is derived from the Quinn et al (2019) paper listed in the references below. You will be able to find all the files needed for this training in this GitHub repository. You can also follow along this tutorial at this Binder here.
Before beginning, here are some preliminary suggested readings to help you better understand TVSA and Radial Basis Functions (RBFs), which will be used in this training:
Herman, J. D., Reed, P. M., & Wagener, T. (2013). Time-varying sensitivity analysis clarifies the effects of watershed model formulation on model behavior. Water Resources Research, 49(3), 1400–1414. https://doi.org/10.1002/wrcr.20124
Giuliani, M., Zaniolo, M., Castelletti, A., Davoli, G., & Block, P. (2019). Detecting the state of the climate system via artificial intelligence to improve seasonal forecasts and inform reservoir operations. Water Resources Research, 55(11), 9133–9147. https://doi.org/10.1029/2019wr025035
Quinn, J. D., Reed, P. M., Giuliani, M., & Castelletti, A. (2019). What is controlling our control rules? opening the black box of multireservoir operating policies using time‐varying sensitivity analysis. Water Resources Research, 55(7), 5962–5984. https://doi.org/10.1029/2018wr024177
Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
The Red River System
The Red River basin consists of four reservoirs: Son La (SL), Thac Ba (TB), Tuyen Quang (TQ), and Hoa Binh (HB), shown in the figure below. The reservoirs’ operators must make daily decisions on the volume of water to release from each reservoir to achieve the following competing objectives:
Protect the city of Hanoi (which lies downstream of the four reservoirs) from flooding by managing city water levels.
Achieve maximum possible hydropower production from each reservoir to serve the energy demands of Hanoi.
Minimize agricultural water supply deficit to meet irrigation needs for the region.
Figure 1: (a) The Red River Basin relative to Vietnam, Laos, and China, and (b) the model abstracting key components of the reservoir system that manages it.
The reservoir operators use information from the projected storage levels at each reservoir and water level forecasts to make their daily release decisions. These decisions in turn determine if they are able to meet their three objectives. Therefore, it is important to understand how different types of information is used and coordinated throughout the year to make these daily decisions.
This exercise
To complete this exercise, you should have the following subfolders and files within your Binder.
HydroInfo_100_thinned.resultfile that contains the decision variables and objective values for all sets of optimal decisions. If this file is missing from the main folder structure, you download the original version here.
daily/SolnXX/ the subfolder that contains text files of each reservoir’s daily decision variables (the columns) across 1,000 years (the rows) for Solution XX.
Most of the daily data folders are large and cannot be stored on the linked GitHub repository. Note that only Soln33 can be found in the daily\ folder. If you would like to perform TVSA on other solutions, please download them separately here.
All in all, there are four selected solutions, named according to the objectives that they prioritize and their tradeoff characteristics:
The “Best Flood” policy: Solution 33
The “Best Hydropower” policy: Solution 37
The “Best Deficit” policy: Solution 52
The “Compromise” policy: Solution 35
Learning goals
In this exercise, we will:
Briefly explain RBFs (Giuliani et al., 2016; Quinn et al., 2017; Giuliani et al., 2019).
Unpack and understand the underlying mechanisms for calculating analytical variance-based first- and second-order sensitivity indices.
Perform time-varying sensitivity analysis for each of the four listed solutions.
Analyze the resulting figures to understand how information use changes throughout the year.
Understanding TVSA
Let’s walk through some key equations before we proceed. In this section, you will also find the Equation numbers that link these equations to their origins in the Quinn et al. (2019) paper listed above.
First, let’s look at some of the notation we will be using:
is the number of policy inputs
is the number of policy outputs
is the number of radial basis functions (RBFs) used
is a day within the entire record, while $t\%365$ is a calendar year (day of year, DOY)
is the number of reservoirs
is the policy-prescribed release at reservoir $k$ at time $t$
is the system state, aka the storage at the reservoir
is a vector of system variables for state $a$
and $b_{n,m}$ are the centers and radii of policy input $m \in M$ for RBF function $n \in N$
is the weight of RBF function $n \in N$
Calculating the first-order sensitivity analysis
The following equation is drawn from Eqn.10 of Quinn et al. (2019):
This equation describes the annual first-order contributions of only variable $(x_t)_a$ to the system state at .
Next, from Eqn.11 of Quinn et al. (2019):
This equation describes the annual second-order contributions for variable to the system states at and . But how do we calculate the derivatives of the policy with respect to its inputs?
Calculating the derivatives
We can calculate the derivative by taking the first partial differential of the policy with respect to each of its inputs. This approach is generalizable to all forms of policy formulation, but in this case, we will take the derivative with respect to the RBF function shown in Eqn 8 of Quinn et al. (2019).
For reference, here is the original RBF function (Eqn. 8 of Quinn et al. (2019)):
A quick aside on RBFs
As shown in the equation above, an RBF is characterized by three parameters: centers and radii for each input variable, and a weight . It is a type of Gaussian process kernel that informs the model (in our case, the Red River model) of the degree of similarity between two input points (Natsume, 2022). Each input is shifted by its distance from its respective “optimal” center point, and scaled by its “optimal” radius. The overall influence of an RBF function on the final release decision is then weighted by an “optimal” constant, where the sum of all should be equal to one.
Herein lies the key advantage of using RBFs: instead of identifying the optimal output (the releases) at each timestep, optimizing RBFs finds optimal values of , , and associated with each input. This limits the number of computations and storage space required to estimate the best-release policy. This is done by eliminating the need to compute future outcomes across all following timesteps, and avoiding the storage of information on prior releases .
General steps
Time-varying sensitivity analysis in general is conducted as follows:
Calculate the variance and covariance of each input variable for each timestep over all years. In this case, the timestep is in daily increments.
Calculate the partial first and second derivatives of each release policy for each day with respect to the input variables at each location.
Compute the first- and second-order contributions of each input variable across all timesteps by:
Multiplying the variances with the first-order derivatives
Multiplying the covariances with their respective second-order derivatives
Plot the contribution of each input variable to daily release policies (i.e. what kind of information is being used to make a decision on releases from reservoir ).
Setting up the problem
To follow along with this tutorial, ensure that all files are located in their appropriate directories, open up the Jupyter notebook named tvsa_exercise.ipynb. Now, let’s import all the required libraries and set some constant parameters. We will be setting the values for the number of input parameters, , the number of RBF functions , and the number of outputs, .
# import the libraries
import numpy as np
import math
import matplotlib.pyplot as plt
import seaborn as sns
from calc_SI import *
from plot_SI import *
sns.set_style("dark")
# set the parameters
M = 5 # Storage at the four reservoirs and the forecasted water levels in Hanoi
N = 12 # Number of RBFs to parameterize. Set a minimum of M+K
K = 4 # Number of outputs (release decisions at the four reservoirs)
num_years = 1000 # Number of years to simulate
We will also need to define our input and output names. These are the column names that will appear in the output .txt files needed to plot our figures later in this exercise. Let’s also set the solution that we would like to analyze.
inputNames = ['sSL', 'sHB', 'sTQ', 'sTB', 'HNwater'] # the storage at Son La, Hoa Bing, Tuyen Quang, Thac Ba, and the water level at Hanoi
outputNames = ['rSL', 'rHB', 'rTQ', 'rTB'] # the release at Son La, Hoa Bing, Tuyen Quang, Thac Ba
policy_file = 'HydroInfo_100_thinned.resultfile'
soln_num = 33
Performing TVSA
The main calculations that output the sensitivity index for each day of the year across 1,000 years is performed by the function called calc_analytical_SI. This function can be found in the calc_SI.py file within this folder. It it highly recommended that you take the time to go through and understand the mechanisms of time-varying sensitivity analysis after completing this exercise. This step can take anywhere from 30-50 minutes, depending on your computing hardware. Feel free to comment out the line of code below if you would only like to plot the TVSA figures.
calc_analytical_SI(M, N, K, policy_file, soln_num, num_years, inputNames, outputNames)
If you are successful in running this function, you should see two new folders in daily/Soln_XX/ called release_decisions and Figures. The latter will become important in a while, when we begin to generate our TVSA figures. For now, open release_decisions to check if the files containing the sensitivity of each reservoir’s release decisions (e.g. rHB.txt) have populated the folder.
Are they there? Great! Let’s move on to generating the figures.
Plot the results
Now that we have the sensitivity indices of each reservoir’s release decision over time, let’s visualize how they use storage and water level forecast information. You can do this by using the plot_tvsa_policy function found in the plot_SI.py file. As before, you’re advised to attempt understand the script once you have completed this exercise.
To begin, let’s specify the name of the inputs that you would like to see in the legends of the figure. For this exercise, we will re-use the inputNames list defined prior to this. We will also need to add one more to this list, called interactions, which quantify the influence of input variable interactions on release decisions. In general, the list of input names and their associated colors should have length $M+1$.
Feel free to replace this with a list of other names that is more intuitive for you. We will also specify the colors they will be shown in. Since there are six inputs, we will have to specify six colors.
# specify the legend labels for each input and their respective colors
input_list = inputNames + ['interactions']
# for Son La, Hoa Binh, Tuyen Quang, Thac Ba, Hanoi, and their interactions respectively
input_colors = ['#FFBF00', '#E83F6F', '#2274A5', '#E3D7FF', '#92BFB1', '#F7A072']
For now, let’s see how this information affect’s Son La’s release decisions over time for the “Best Flood” solution. This is the solution that minimizes the “worst first-percentile of the amount by which the maximum water level in Hanoi exceed 11.25m” (Quinn et al., 2019).
plot_tvsa_policy(num_years, 33, input_list, input_colors, 'rSL', 'Sensitivity of Son La releases')
If all the steps have been completed, you should be able to view the following image:
Figure 2: Average contributions of each input across all simulation years and their interactions to Son La’s release decision variance. The vertical axis represents the relative contributions of each input variable to variance. The horizontal axis shows the months in a year.
If you’d like to see and automatically save the plots for all four reservoirs, you can opt for a for loop:
res_names = ['Son La', 'Hoa Binh', 'Tuyen Quang', 'Thac Ba']
for r in range(len(outputNames)):
plot_name = res_names[r] + ' releases'
plot_tvsa_policy(num_years, 33, input_list, input_colors,
outputNames[r], plot_name + ' releases')
At the end of this, you should be able to locate all the figure in the daily/Soln_XX/Figures folder, where XX is the solution number of your choice.
Analyze the results
The figure below shows the time-varying sensitivity of the release decisions at all four reservoirs to the input variables. As a quick reminder, we are looking at Solution 33, which is the “Best Flood” solution.
Figure 3: Average contributions of each input across all simulation years and their interactions to (clockwise) Son La, Hoa Binh, Tuyen Quang, and Thac Ba. The vertical axis represents the relative contributions of each input variable to variance. The horizontal axis shows the months in a year.
In Figure 3 above, note the visual similarity between both Hoa Binh and Son La’s components’ contributions to their respective variance. The similarities between the pair of reservoirs could potentially be attributed to the geographic characteristics of the Red River basin (although further analysis is required here). In Figure 1, both Son La and Hoa Binh belong to the same Red River tributary, with the former preceding the latter. Their release decisions dominantly use information from Hanoi’s water level forecasts, particularly during the five months that correspond to Vietnam’s May-September monsoon season.
During the same period, the variance in Thac Ba and Tuyen Quang’s release decision have relatively-even contributions from Son La’s storage levels, Hanoi’s water level forecast, and interactions between different types of information. This indicates that it is crucial for the reservoir managers at Thac Ba and Tuyen Quang to carefully monitor these three main information sources during the monsoon period. Higher resolution data, and more frequent monitoring may be valuable during this time.
Interestingly, storage information from Hoa Binh appears to contribute most to the release decision variances of each reservoir before at and at the beginning of the monsoon. Hoa Binh’s storage information is particularly important during the first half of the year at all four reservoirs, which happens to be immediately before and during the monsoon season. During the same period of time, interactions between information from all other reservoirs also plays an important role in regulating release decisions.
Post-monsoon, the implications of interactions on release decisions becomes negligible, and each reservoir’s releases become dominantly driven by storage levels at Hoa Binh and Hanoi’s water levels once more, approximately mirroring the distribution of information contributions during the pre-monsoon period. However, storage levels at Thac Ba and Tuyen Quang play a more important role at determining release decisions during this time, and their contributions to release decisions is greater for their own reservoirs. Notably, information on storage at Thac Ba has the least influence for all reservoirs’ release decisions (including its own) throughout the entire year. This is likely due to it being the smallest reservoir in the system (Table 1; Quinn et al., 2019).
These observations can lead us to hypothesize that:
For a policy that prioritizes minimizing flooding in Hanoi, information on storage levels at the Hoa Binh reservoir is vital.
Storage levels at Hoa Binh should therefore be closely monitored and recorded at high resolution.
During the monsoon, water levels in Hanoi are also key to release decisions and should be recorded at regular intervals.
Interactions between difference sources of information is also a significant contributor to the variance across all reservoirs’ release decisions; treating decisions and conditions at each reservoir as independent of others can result in under-estimating the risk of flooding.
Summary
Overall, TVSA is a useful method to help decision-makers identify what information is useful, and when it is best used. This information is valuable when determining the resolution at which observations should be taken, or if downscaling is appropriate. Note that this method of calculating sensitivity relies on variance-based global sensitivity analysis method. This is where the sensitivity of an output to a provided input (or a combination thereof) is quantified as the contribution of total variance in the output by that input (or a combination of inputs). However, such methods may be biased by heavy-tailed distributions or outliers and therefore should be used only where appropriate (e.g. when the output distributions have analyzed, or when outputs are not multimodal; Reed et al., 2022). As you may have noticed, TVSA is also a computationally expensive process that requires a significant amount of time. This requirement grows exponentially with the number of simulations/years that you are calculating variance across, or as the number of inputs and outputs increase.
In this exercise, we performed time varying sensitivity analysis to understand how each reservoir within the Red River system in Vietnam uses storage and water level information on a day-to-day basis, and how this use of information changes over time. Similar methods have also been used to better understand how the formulation of hydrological processes affect watershed model behavior (Herman et al., 2013; Medina and Muñoz, 2020; Basijokaite and Kelleher, 2021), and asses information use in microgrid energy management (Liu et al., 2023). Post-exercise, do take some time to peruse these papers (linked before in the References section).
That said, thank you for sticking around and hope you learned a little something here!
References
Basijokaite, R., & Kelleher, C. (2021). Time‐varying sensitivity analysis reveals relationships between watershed climate and variations in annual parameter importance in regions with strong interannual variability. Water Resources Research, 57(1). https://doi.org/10.1029/2020wr028544
Giuliani, M., Castelletti, A., Pianosi, F., Mason, E., & Reed, P. M. (2016). Curses, tradeoffs, and scalable management: Advancing Evolutionary Multiobjective Direct Policy search to improve water reservoir operations. Journal of Water Resources Planning and Management, 142(2). https://doi.org/10.1061/(asce)wr.1943-5452.0000570
Herman, J. D., Reed, P. M., & Wagener, T. (2013a). Time-varying sensitivity analysis clarifies the effects of watershed model formulation on model behavior. Water Resources Research, 49(3), 1400–1414. https://doi.org/10.1002/wrcr.20124
Liu, M.V., Reed, P.M., Gold, D.F., Quist, G., Anderson, C.L. (2023). A Multiobjective Reinforcement Learning Framework for Microgrid Energy Management. arXiv. https://doi.org/10.48550/arXiv.2307.08692
Medina, Y., & Muñoz, E. (2020). A simple time-varying sensitivity analysis (TVSA) for assessment of temporal variability of hydrological processes. Water, 12(9), 2463. https://doi.org/10.3390/w12092463
Quinn, J. D., Reed, P. M., Giuliani, M., & Castelletti, A. (2019). What is controlling our control rules? opening the black box of multireservoir operating policies using time‐varying sensitivity analysis. Water Resources Research, 55(7), 5962–5984. https://doi.org/10.1029/2018wr024177
Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
I recently completed a course Final Project in which I attempted to implement a Hidden Markov Model (HMM) parameterized using the Markov Chain Monte Carlo method. In this post, I will briefly introduce HMM models as well as the MCMC method. I will then walk you through an exercise implementing a HMM in the Julia programming language and share some preliminary results from my exploration in combining both these methods. All the code found in this exercise can be located in this GitHub repository.
Note: The exercise in this post will require some familiarity with Julia. For a quick introduction to this relatively recent newcomer to the programming languages scene, please refer to Peter Storm’s blog post here.
Hidden Markov Models
A Hidden Markov Model (HMM) is a statistical tool used to model different types of time series data ranging from signal processing, hydrology, financial statistics, speech recognition, and econometrics (Rabiner, 1990; Rydén, 2008), where the underlying process is assumed to be Markovian. Specifically, it has been found to be effectively at modeling systems with long-term persistence, where past events have effects on current and future events at a multi-year scale (Akintug and Rasmussen, 2005; Bracken et al., 2014). Recent studies have also found that it is possible to use HMMs to model the dynamics of streamflow, where the HMM state space represents the different hydrological conditions (e.g. dry vs. wet) and the observation space represents the streamflow data (Hadjimichael et al., 2020; 2020a). These synthetic streamflows are computationally generated with the aid of packages such as hmmlearn in Python and HMMBase in Julia. An example implementation of hmmlearn can be found in Julie Quinn’s blog post here. She also wrote the prequel to the implementation post, where she dives into the background of HMMs and applying Expectation-Maximization (EM) to parameterize the model.
Markov Chain Monte Carlo
The EM approach of parameterizing HMMs reflects a frequentist approach that assumes the existence of one “true” value for each HMM parameter. In this exercise, I will instead use a Bayesian approach via the Markov Chain Monte Carlo method to generate and randomly sample potential parameter (model prior) values from a Markov chain, which are statistical models that approximate Markovian time series. In these time series, the probability of being in any given state st at current time t is dependent only on states prior to st. Using the MCMC approach, a Markov Chain is constructed for each HMM parameter such that its stationary distribution (distribution of the parameters at equilibrium) is the distribution of its associated model posterior (the likelihood of a model structure after, or a posteriori, obtaining system observed data). The model priors (assumed model structure prior to having any knowledge about the system) are randomly sampled from their respective chains — hence the term “Monte Carlo”. These samples are then used to estimate the statistical properties of the distribution of each parameter.
Overall, MCMC is a powerful method to estimate the statistical properties of high-dimensional problems with many parameters. Nonetheless, it is beholden to its own set of limitations that include high computational expense and the inability to guarantee convergence. Figure 1 below summarize some of the benefits and drawbacks of using MCMC parameterization:
Figure 1: The pros and cons of using MCMC parameterization.
Setting up the parameters
In this exercise, I will be using the HMM to approximate the statistical properties of streamflow data found in the annualQ.csv file previously used also by Rohini in her post on creating HMMs to generate synthetic streamflow seriesand by the MSD UC Ebook HMM training Jupyter Notebook. This streamflow time series originated from a USGS outlet gauge in the Upper Colorado River Basin. It records 105 years’ worth of streamflow from 1909 and 2013 (inclusive). It was previously found that it was best described using two states (wet and dry; Bracken et al, 2014). In this exercise, I also assume that this time series is best approximated by a first-order HMM where the state at current time t (st) is only affected by the state at the timestep immediately prior to it (st-1).
In this exercise, I will be using MCMC to parameterize the following HMM parameters:
Parameter
Description
The initial state distribution a for wet (1) and dry (2) states
The transition matrix A from a wet (1) to a dry (2) state
The probability distributions for the vector of observations x for a given state where Wet: 1 and Dry: 2
Table 1: Summary of all HMM parameters to be adjusted using the MCMC approach.
From Table 1 above:
P(ai) is the initial state probability for state i
P(Aij) is the transition probability from state i to state j
μiand σi are the mean and standard deviation for the vector of streamflow observations x for a given state i
Now that the dataset and model parameters have been introduced, we will proceed with demonstrating the code required to implement the HMM model with MCMC parameterization.
Implementing the streamflow HMM with using MCMC parameterization
Before begin, I recommend downloading and installing Julia 1.8.5. Please find the Windows and Mac 64-bit installer here. Once Julia is set up, we can download and install all required packages. In Julia, this can be done as follows:
# make sure all required packages are installed
import Pkg
Pkg.activate(@__DIR__);
Pkg.instantiate();
Once this is done, we can load all the required packages. In Julia, this is done using the using key word, which can be thought of as the Python import parallel. Note that I placed a semicolon after the using CSV line. This is to prevent the automatic printing of output messages that Julia automatically displays when loading packages.
# load all packages
using Random
using CSVFiles # load CSV data
using DataFrames # data storage and presentation
using Plots # plotting library
using StatsPlots # statistical plotting
using Distributions # statistical distribution interface
using Turing # probabilistic programming and MCMC
using Optim # optimization library
using StatsBase
using LaTeXStrings
using HMMBase
using DelimitedFiles
using CSV;
Now, let’s load the data and identify the number of years and number of states inherent to time streamflow time series.
# load data
# source: https://github.com/IMMM-SFA/msd_uncertainty_ebook/tree/main/notebooks/data
Q = CSV.File("annualQ.csv", header=[:Inflow]) |> DataFrame
Q = Q[2:end,:]
Q[!,:Inflow] = parse.(Float64, Q[!, :Inflow])
Q[!, :Year] = 1909:2013;
Q[!, :logQ] = log.(Q[!, :Inflow]);
# Assume first-order HMM where only the immediate prior step influences the next step
n_states = 2
logQ = Q[!,:logQ];
n_years = size(logQ)[1];
Next, we should set a random seed to ensure that our following results are consistent. This is because the package that we are using in this exercise called “Distributions” performs random sampling. Without setting the seed (shown below), the outcomes of the exercise may be wildly different each time the MCMC parameterization algorithm is run.
# Set the random seed
Random.seed!(1)
Next, we define the HMM model with MCMC sampling. The sampling is performed using methods and syntax built into the Turing.jl package. In the code below, also note lines 32 to 38. Within those lines, the observations’ states are enforced where observations with log-streamflows below the input mean are assigned to a dry state, while the opposite is implemented for log-streamflows above the wet state. This step is important to prevent mode collapse, where the HMM model cannot distinguish between the wet and dry state distributions due to the random sampling of the MCMC parameterization.
@model function HMM_mcmc(logQ, n_states, n_years)
# Source: https://chat.openai.com/c/d81ef577-9a2f-40b2-be9d-c19bf89f9980
# Prompt example: Please suggest how you would parameterize Hidden Markov Model with the Markov Chain Monte Carlo method
# Uses the Turing.jl package in Julia. The input to this model will be an inflow timeseries with two hidden states.
mean_logQ = mean(logQ)
# Define the prior distributions for the parameters
μ₁ ~ Normal(15.7, 0.25) # wet state
μ₂ ~ Normal(15.2, 0.25) # dry state
σ₁ ~ truncated(Normal(0.24, 0.1), 0, Inf)
σ₂ ~ truncated(Normal(0.24, 0.1), 0, Inf)
a11 ~ Dirichlet(ones(n_states))
A ~ filldist(Dirichlet(ones(n_states)), n_states)
s = tzeros(Int, n_years) # Define the vector of hidden states
# Define intial state probability distribution
a = [a11[1], 1-a11[1]] # [wet state, dry state]
# Define the observation distributions
B = [Normal(μ₁, σ₁), Normal(μ₂, σ₂)]
# Sample the initial hidden state and observation variables
s[1] ~ Categorical(a)
# Loop over time steps and sample the hidden+observed variables
for t in 2:n_years
s[t] ~ Categorical(A[:,s[t-1]])
end
for t in 1:n_years
logQ[t] ~ B[s[t]]
# if the logQ is greater than the input mean, force the state to be a wet state
if logQ[t] > mean_logQ
s[t] ~ Categorical(A[:,1])
# if the logQ is smaller than the input mean, force the state to be a dry state
elseif logQ[t] < mean_logQ
s[t] ~ Categorical(A[:,2])
end
end
end
We then have to run the model for at least 3,000 iterations before the sample values for each parameter converge to stable values. The code to perform this is as follows:
# run for 3000 iterations; usually enough
# run using >3 chains to double check convergence if desired
hmm_model = HMM_mcmc(logQ, n_states, n_years)
g = Gibbs(HMC(0.05, 10, :μ₁, :μ₂, :σ₁, :σ₂, :a11, :A), PG(10, :s))
chains = sample(hmm_model, g, MCMCThreads(), 3000, 1, drop_warmup=true)
To check for convergence, you can attempt to run plot(chains) to check for convergence, and corner(chains) to examine the parameters for dependencies. In this post, we will not discuss MCMC convergence in detail, but some things to look out for would be r_hat values in the output of the code shown above that are close to 1, as well as chains that are similar to each other. Refer to Table 2 and Figure 2 for some quick statistics that can be used as a baseline to determine if your model has converged.
Table 2: The mean converged values for some of the HMM parameters.
Figure 2: The mean converged values of the transition matrix components.
Now, let’s use the model to generate 1,000 samples of streamflow. First, we define the streamflow prediction function:
function predict_inflow(chain, logQ)
μ₁ = Array(group(chain, :μ₁))
μ₂ = Array(group(chain, :μ₂))
σ₁ = Array(group(chain, :σ₁))
σ₂ = Array(group(chain, :σ₂))
a11 = Array(group(chain, "a11[1]"))
a22 = Array(group(chain, "a11[2]"))
A11 = Array(group(chain, "A[1,1]"))
A12 = Array(group(chain, "A[1,2]"))
A21 = Array(group(chain, "A[2,1]"))
A22 = Array(group(chain, "A[2,2]"))
n_samples = 1000
μ1_sample = sample(μ₁, n_samples, replace=true);
μ2_sample = sample(μ₂, n_samples, replace=true);
σ1_sample = sample(σ₁, n_samples, replace=true);
σ2_sample = sample(σ₂, n_samples, replace=true);
a11_sample = sample(a11, n_samples, replace=true);
a22_sample = sample(a22, n_samples, replace=true);
A11_sample = sample(A11, n_samples, replace=true);
A12_sample = sample(A12, n_samples, replace=true);
A21_sample = sample(A21, n_samples, replace=true);
A22_sample = sample(A22, n_samples, replace=true);
Q_predict = zeros(length(logQ), n_samples)
#residuals_ar = zeros(length(temp_data), n_samples)
s_matrix = zeros(length(logQ), n_samples)
logQ_matrix = zeros(length(logQ), n_samples)
meanQ = mean(logQ)
for n = 1:n_samples
s_sample = tzeros(Int, n_years)
Q_sample = zeros(n_years)
μ1 = μ1_sample[n]
μ2 = μ2_sample[n]
σ1 = σ1_sample[n]
σ2 = σ2_sample[n]
a11 = a11_sample[n]
a22 = a22_sample[n]
A11 = A11_sample[n]
A21 = 1 - A11_sample[n]
A12 = 1 - A22_sample[n]
A22 = A22_sample[n]
#println(A)
A = [A11 A12; A21 A22]
A = transpose(A)
#println(A)
#a = [1-a22, a22]
a = [a11, 1-a11]
print(a)
B = [Normal(μ1, σ1), Normal(μ2, σ2)]
# Sample the initial hidden state and observation variables
s_sample[1] = rand(Categorical(a))
# Loop over time steps and sample the hidden+observed variables
for t in 2:n_years
s_sample[t] = rand(Categorical(A[s_sample[t-1], :]))
end
for t in 1:n_years
Q_sample[t] = rand(B[s_sample[t]])
if Q_sample[t] < meanQ
s_sample[t] = 1
elseif Q_sample[t] > meanQ
s_sample[t] = 2
end
end
s_matrix[:, n] = s_sample
Q_predict[:, n] = Q_sample
end
return s_matrix, Q_predict
end
From this function, we obtain the state and log-inflow matrix with dimensions 105 × 1000 each.
We randomly select a timeseries out of the 1,000 timeseries output by the prediction function and plot the wet and dry states identified:
# create the dry and wet masks
q = Q[!,:Inflow]
y = Q[!,:Year]
# select a random sample timeseries to plot
idx = 7
Q_wet_mcmc = q[s_matrix[:,idx] .== 1]
Q_dry_mcmc = q[s_matrix[:,idx] .== 2]
y_wet_mcmc = y[s_matrix[:,idx] .== 1]
y_dry_mcmc = y[s_matrix[:,idx] .== 2];
# plot the figure
plot(y, Q.Inflow, c=:grey, label="Inflow", xlabel="Year", ylabel="Annual inflow (cubic ft/yr)")
scatter!(y_dry_mcmc, Q_dry_mcmc, c=:salmon, label="Dry state (MCMC)", xlabel="Year", ylabel="Annual inflow (cubic ft/yr)")
scatter!(y_wet_mcmc, Q_wet_mcmc, c=:lightblue, label="Wet state (MCMC)", xlabel="Year", ylabel="Annual inflow (cubic ft/yr)")
The output figure should look similar to this:
Figure 2: Wet (pink) and dry (blue) states identified within the streamflow timeseries.
From this figure, we can see that the HMM can identify streamflow extreme as wet and dry states (albeit with some inconsistencies) where historically high streamflows are identified as a “wet state” and low streamflows are correspondingly identified as “dry”.
To make sure that the model can distinguish the observation distributions for wet and dry states, we plot their probability distribution functions. Before we plot anything, though, let’s define a function that will help us plot the distributions themselves. For this function, we first need to load the LinearAlgebra package.
# load the LinearAlgebra package
using LinearAlgebra
# function to plot the distribution of the wet and dry states
function plot_dist(Q, μ, σ, A)
evals, evecs = eigen(A).values, eigen(A).vectors
one_eval = argmin(abs.(evals.-1))
π = evecs[:, one_eval] / sum(evecs[:, one_eval])
x_0 = LinRange(μ[1] - 4*σ[1], μ[1] + 4*σ[1], 10000)
norm0 = Normal(μ[1], σ[1])
fx_0 = π[1].*pdf.(norm0, x_0)
x_1 = LinRange(μ[2] - 4*σ[2], μ[2] + 4*σ[2], 10000)
norm1 = Normal(μ[2], σ[2])
fx_1 = π[2].*pdf.(norm1, x_1)
x = LinRange(μ[1] - 4*σ[1], μ[2] + 4*σ[2], 10000)
fx = π[1].*pdf.(norm0, x) .+ π[2].*pdf.(norm1, x)
#fig, ax = plt.subplots(1, 1, figsize=(12, 8))
b = range(μ[1] - 4*σ[1], μ[2] + 4*σ[2], length=100)
histogram(log.(Q), c=:lightgrey, normalize=:pdf, label="Log-Inflow")
plot!(x_0, fx_0, c=:red, linewidth=3, label="Dry State Distr", xlabel="x", ylabel="P(x)")
plot!(x_1, fx_1, c=:blue, linewidth=2, label="Wet State Distr")
plot!(x, fx, c=:black, linewidth=2, label="Combined State Distr")
end
Great! Now let’s use this function to plot the distributions themselves.
# get the model parameter value means
μ₁_mean = mean(chains, :μ₁)
μ₂_mean = mean(chains, :μ₂)
σ₁_mean = mean(chains, :σ₁)
σ₂_mean = mean(chains, :σ₂)
a11_mean = mean(chains, "a11[2]")
A11_mean = mean(chains, "A[1,1]")
A12_mean = mean(chains, "A[1,2]")
A21_mean = mean(chains, "A[2,1]")
A22_mean = mean(chains, "A[2,2]")
# obtained from model above
μ = [μ₂_mean, μ₁_mean]
σ = [σ₂_mean, σ₁_mean]
A_mcmc = [A11_mean 1-A11_mean; 1-A22_mean A22_mean]
# plot the distributions
plot_dist(Q[!,:Inflow], μ, σ, A_mcmc)
This code block will output the following figure:
Figure 3: The overall (black), wet (blue) and dry (red) streamflow probability distributions.
From Figure 3, we can observe that the dry state streamflow distribution is different from that of the wet state. The HMM model correctly estimates a lower mean for the dry state, and a higher one for the dry state. Based on visual analysis, the states have similar standard deviations, but this is likely an artifact of the prior parameterization of the initial HMM model that we set up earlier. The step we took earlier to force the wet/dry state distributions given a sampled log-streamflow value also likely prevented mode collapse and enabled the identification of two distinct distributions.
Now, let’s see if our HMM can be used to generate synthetic streamflow. We do this using the following lines of code:
# plot the FDC of the sampled inflow around the historical
sampled_obs_mcmc = zeros(1000, n_years)
Q_predict_mcmc = transpose(logQ_predict)
for i in 1:1000
sampled_obs_mcmc[i,:] = exp.(Q_predict_mcmc[i, :])
sampled_obs_mcmc[i,:] = sort!(sampled_obs_mcmc[i, :], rev=true)
end
hist_obs = copy(Q[!,:Inflow])
hist_obs = sort!(hist_obs, rev=true)
probs = (1:n_years)/n_years
plot(probs, hist_obs, c=:grey, linewidth=2, label="Historical inflow",
xlabel="Exceedance prob.", ylabel="Annual inflow (cubic ft/yr)")
for i in 1:1000
if i == 1
plot!(probs, sampled_obs_mcmc[i,:], c=:lightgreen, linewidth=2,
label="Sampled inflow (MCMC)", xlabel="Exceedance prob.", ylabel="Annual inflow (cubic ft/yr)")
end
plot!(probs, sampled_obs_mcmc[i,:], c=:lightgreen, linewidth=2, legend=false,
xlabel="Exceedance prob.", ylabel="Annual inflow (cubic ft/yr)")
end
plot!(probs, hist_obs, c=:grey, linewidth=2, legend=false,
xlabel="Exceedance prob.", ylabel="Annual inflow (cubic ft/yr)")
Once implemented, the following figure should be output:
Figure 4: The original historical streamflow timeseries (grey) and the synthetic streamflow generated by the HMM (green).
This demonstrates that the HMM model is capable of generating synthetic streamflow that approximates the statistical properties of the historical timeseries, while expanding upon the range of uncertainty in streamflow scenarios. This has implications for applications such as exploratory modeling of different streamflow scenarios, where such approaches can be used to generate a wetter- or dryer-than-historical streamflows.
Summary
While using MCMC to parameterize a HMM is a useful method to generate synthetic streamflow, one significant drawback is the long runtime and the large number of iterations that the MCMC algorithm takes to converge (Table 3).
Table 3: MCMC parameterization and runtime.
This is likely due to the HMM sampling setup. Notice that in lines 27 and 33-27 in the HMM_mcmc function: we are essentially fitting an additional probability distribution at each st essentially turning them into tunable parameters themselves. Since there are 105 elements in the streamflow timeseries, this introduces an additional 105 parameters for the MCMC to fit distributions to. This is the likely cause for the lengthy runtime. While we will not explore alternative HMM-MCMC parameterization approaches, more efficient alternatives definitely exist, and you are highly encouraged to check it out!
Overall, we began this post with a quick introduction to HMM and MCMC sampling. We then compared the pros and cons of using the MCMC approach to parameterize a HMM. Once we understood its benefits and drawbacks, we formulated a HMM for a 105-year long timeseries of annual streamflow and examined the performance of the model by analyzing its converged parameter values, observation probability distributions, as well as its ability to detect wet/dry states in the historical time series. We also used the HMM to generate 1,000 synthetic streamflow scenarios. Finally, we diagnosed the cause for the long time to convergence of the MCMC sampling approach.
This brings us to the end of the post! I hope you now have a slightly better understanding of HMMs, how they can be parameterized using the MCMC approach, as well as issues you might run into when you implement the latter.
Happy coding!
References
Akintug, B., & Rasmussen, P. F. (2005). A Markov switching model for annual hydrologic time series. Water Resources Research, 41(9). https://doi.org/10.1029/2004wr003605
Bracken, C., Rajagopalan, B., & Zagona, E. (2014). A hidden markov model combined with climate indices for Multidecadal Streamflow Simulation. Water Resources Research, 50(10), 7836–7846. https://doi.org/10.1002/2014wr015567
Hadjimichael, A., Quinn, J., & Reed, P. (2020). Advancing diagnostic model evaluation to better understand water shortage mechanisms in institutionally complex river basins. Water Resources Research, 56(10), e2020WR028079.
Hadjimichael, A., Quinn, J., Wilson, E., Reed, P., Basdekas, L., Yates, D., & Garrison, M. (2020a). Defining robustness, vulnerabilities, and consequential scenarios for diverse stakeholder interests in institutionally complex river basins. Earth’s Future, 8(7), e2020EF001503.
Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
Rydén, T. (2008). Em versus markov chain Monte Carlo for estimation of Hidden Markov models: A computational perspective. Bayesian Analysis, 3(4). https://doi.org/10.1214/08-ba326
Turek, D., de Valpine, P. and Paciorek, C.J. (2016) Efficient Markov Chain Monte Carlo Sampling for Hierarchical Hidden Markov Models, arXiv.org. Available at: https://arxiv.org/abs/1601.02698.
As the name *may* have implied, today’s blog post will be about proximal policy optimization (PPO), which is a deep reinforcement learning (DRL) algorithm introduced by OpenAI in 2017. Before we proceed, though, let’s set a few terms straight:
State: An abstraction of the current environment that the agent inhabits. An agent observes the current state of the environment, and makes a decision on the next action to take.
Action: The mechanism that the agent uses to transition between one state to another.
Agent: The decision-maker and learner that takes actions based on its consequent rewards or penalties.
Environment: The dynamic system defined by a set of rules that the agent interacts with. The environment changes based on the decisions made and actions taken by the agent.
Reward/Penalty: The feedback received by the agent. Often in reinforcement learning, the agent’s objective is to maximize its reward or minimize its penalty. In this post, we will proceed under the assumption of a reward-maximization objective.
Policy: A model that maps the states to the probability distribution of actions. The policy can then be used to tell the agent to select actions that are most likely to result in the lowest penalty/highest reward for a given state.
Continuous control: The states, actions, and rewards take on analog continuous values (e.g. move the cart forward by 1.774 inches).
Discrete control: The states, actions, and rewards take on binary values (e.g. true/false, 1/0, left/right).
As per the last definition, the PPO is policy-based DRL algorithm that consists of two main steps:
The agent interacts with the environment by taking a limited number of actions, and samples data from the reward it receives.
The agent then makes multiple optimizations (policy updates) for an estimate (or “surrogate” as Schulman et al. 2017 calls it) of the reward-maximizing objective function using stochastic gradient ascent (SGA). This is where the weights of the loss function (the difference between actual and observed reward) are incrementally tuned as more data is obtained to result in the highest possible reward.
Note: If you are wondering what SGA is, look up Stochastic Gradient Descent — it’s the same thing, but reversed.
These steps address a couple of issues that other policy-based methods such as policy gradient optimization (PGO) and trust region policy optimization (TRPO) face. Standard PGO requires that the objective function be updated only once per data sample, which is computationally expensive given the number of updates that are typically required of such problems. PGO is also susceptible to potentially destructive policy updates where one round of optimization could result in the policy’s premature convergence, or failure to converge to the true maximum reward. On the other hand, the TRPO is complicated to implement and requires prior computations to optimize (and re-optimize) a secondary constraint function that defines the policy’s trust region (and hence the name). It is therefore difficult to implement, and lacks explainability.
PPO Plug
Unlike both standard PGO and TRPO, PPO serves to carefully balance the tradeoffs between ease of implementation, stable and reliable reward trajectories, and speed. It is particularly useful for training agents in continuous control environments, and achieves this in one of two ways:
PPO with adaptive penalty: The penalty coefficient used to optimize the function defining the trust region is updated every time the policy changes to better to adapt the penalty coefficient so that we achieve an update that is both significant but does not overshoot from the true maximum reward.
PPO with a clipped surrogate objective: This method is currently the more widely used version of PPO as it has been found to perform better than the former (Schulman et al, 2017; van Heeswijk, 2022). This PPO variant restricts – clips – the possible range within which the policy can be updated by penalizing any update where the ratio of the probability of a new action being taken given a state to that of the prior action exceeds a threshold.
The latest version of PPO, called PPO2 (screams creativity, no?) is GPU- and multiprocessor-enabled. In other words, its a more efficiently-parallelized version of PPO that enables the training over multiple environments at the same time. This is the algorithm we will be demonstrating next.
PPO Demo
As always, we first need to load some libraries. Assuming that you already have the usual suspects (NumPy, MatPlotlib, Pandas, etc), you will require the Gym and Stable-Baselines3 libraries. The former is a collection of environments that reference general RL problems, while the latter contains stable implementations of most RL algorithms written in PyTorch. To install both Gym and Stable-Baselines3 on your local machine, enter the following command into your command line:
pip install gym stable-baselines3
Once that it completed, create a Python file and follow along the code. This was adapted from a similar PPO demo that can be found here.
In the Python file, we first import the necessary libraries to run and record the training process. We will directly import the PPO algorithm from Stable-Baselines3. Note that this version of the PPO algorithm is in fact the more recent PPO2 algorithm.
# import libraries to train the mountain car
import gym
from stable_baselines3 import PPO
# import libraries to record the training
import numpy as np
import imageio
Next, let’s create the gym environment. For the purpose of this post, we will use the Mountain Car environment from the Gym library. The Mountain Car problem describes a deterministic Markov Decision Process (MDP) with a known reward function (and hence the name). In this problem, a car is placed at the bottom of a sinusoidal valley (Figure 1) and can take three discrete deterministic actions – accelerate to the right, accelerate to the left, or don’t accelerate – to gain enough momentum to push the car up to the flag on top of the mountain. In this environment, the goal of the agent is to learn a policy that will consistently accelerate the mountain car to reach the flag at the top of the hill in less than 200 episodes. This is where the agent completes a full training sequence within the pre-allocated number of time steps, and is otherwise known as an epoch in general machine learning.
Figure 1: Episode 1 (untrained) of the Mountain Cart.
Aite, so let’s create this environment!
# make the gym environment
env_mtcar = gym.make('MountainCar-v0')
Next, we setup an actor-critic multi-layer perceptron model and apply the PPO2 algorithm to train the mountain cart. Here, we want to view the information output by the model, we we will set verbose = 1. We will then allow the model learn for over 100,000 timesteps per episode.
# setup the model
# Implement actor critic, using a multi-layer perceptron (2 layers of 64) in the pre-specified environment
model = PPO("MlpPolicy", env_cartpole, verbose=1)
# return a trained model that is trained over 10,000 timesteps
model.learn(total_timesteps=10_000)
Let’s take a look at the starting point of the environment. In general, it’s good practice to use the .reset() function to return the environment to it’s starting state after every episode. Here, we also initialize an array of images that we will later combine using the imageIO library to form a GIF.
# get the environment
vec_env = model.get_env()
# reset the environment and return an array of observations whenever a new episode is started
obs = vec_env.reset()
# initialize the GIF to record
images = []
img = model.env.render(mode='rgb_array')
For the Mountain Car environment, the obs variable is a 2-element array where the first element describes the position of the car along the x-axis, and the second element describes the velocity of the car. After a reset, the obs variable should print to look something like [[-0.52558255 0. ]] where the velocity is zero (stationary).
Next, we take 1,000 random actions just to see how things look like. Before each action is taken, we take a snapshot of the prior action and append it to the list of images we initialized earlier. Next, we predict what the next action and hidden state (denoted by the “_” at the beginning of the variable name) is given the current state, provided that its actions are deterministic. We then use this new action to take a step to return the resulting observation and reward. The reward variable will return a value of -1 if an additional action was taken which did not result in reaching the flag. The done variable is a boolean that indicates if the car successfully reached the flag. If done=TRUE, reset the environment to its starting state. Otherwise, continue learning from the environment. We also create a new snapshot of this current action and render it as an image to be later added to the image list.
# train the car
for i in range(1000):
# append a snapshot of the current episode to the array
images.append(img)
# get the policy action from an observation and the optional hidden state
# return the deterministic actions
action, _states = model.predict(obs, deterministic=True)
# step the environment with the given action
obs, reward, done, info = vec_env.step(action)
if (i%500) == 0:
print("i=", i)
print("Observation=", obs)
print("Reward=", reward)
print("Done?", done)
print("Info=", info)
if done:
obs = env.reset()
img = model.env.render(mode='rgb_array')
vec_env.render()
Finally, we convert the list of images to a GIF and close the environment:
imageio.mimsave('mtcart.gif', [np.array(img) for i, img in enumerate(images) if i%2 == 0], fps=29)
You should see the mtcart.gif file saved in the same directory that you have your code file in. This GIF should look similar to Figure 2:
Figure 2: The mountain car environment progress for a 10,000 timestep training environment.
Conclusion
Overall, PPO is relatively simple but powerful reinforcement learning algorithm to implement, with recent applications in video games, autonomous driving, and continuous control problems in general. This post provided you with a brief but thorough overview of the algorithm and a simple example application to the Mountain Cars environment, and I hope that it motivates you to further check it out and explore other environments as well!
Schulman, J. et al. (2017) Proximal policy optimization algorithms, arXiv.org. Available at: https://arxiv.org/abs/1707.06347 (Accessed: April 11, 2023).
The name of this post speaks for itself – this will be a soft introduction to causality, and is intended to increase familiarity with the ideas, methods, applications and limitations of causal theory. Specifically, we will walk through a brief introduction of causality and compare it with correlation. We will also distinguish causal discovery from causal inference, the types of datasets commonly encountered and provide a (very) brief overview of the methods that can be applied towards both. This post also includes a list of commonly-encountered terms within the literature, as well as prior posts written on this topic.
Proceed if you’d like to be less of a causality dummy!
Introducing Causality
Note: The terms “event” and “variable” will be used interchangeably in this post.
Causality has roots and applications in a diverse set of field: philosophy, economics, mathematics, neuroscience – just to name a few. The earliest formalization for causality can be attributed to Aristotle, while modern causality as we understand it stem from David Hume, an 18th-century philosopher (Kleinberg, 2012). Hume argued that causal relationships can be inferred from observations and is conditional upon the observer’s beliefs and perceptions. Formally, however, causation can be defined as the contribution of an event to the production of other events. Causal links between events can be uni- or bi-directional – that is
Event X causes event Y where the reverse is false, or
Event X causes event Y where the reverse is true.
Such causal links have to be first detected and and then quantified to confirm the existence of a causal relationship between two events or variables, where the strength of these relationships have been measured using some form of a score-based strength measure (where the score has to exceed a specific threshold for it to be “counted” as a causal link), or using statistical models to calculate conditional independence.
Before we get down into the details on the methods that enable aforementioned quantification, let’s confront the elephant in the room:
Correlation vs Causation
The distinction between correlation and causation is often-muddled. Fortunately, there exists a plethora of analogies as to why correlation is not causation. My favorite so far is the global warming and pirates analogy, where increasing global mean temperature was found to be negatively correlated with a consistent decrease in the number of pirates. To demonstrate my point:
This plot is trying to tell you something that will save the Earth. (source: Baker, 2020)
…so does this mean that I should halt my PhD and join the dwindling ranks of pirates to save planet Earth?
Well, no (alas). This example demonstrates why relationships between such highly-correlated variables can be purely coincidental, with no causal links. Instead, there are external factors that may have actually the number of pirates to decrease, and independently, the global mean temperature to rise. Dave’s, Rohini’s and Andrew’s blog posts, as well as this website provide more examples that further demonstrate this point. Conversely, two variables that are causally linked may not be correlated. This can happen when there is a lack of change in variables being measured, sometimes caused by insufficient or manipulated sampling (Penn, 2018).
Correlation is limited by its requirement that the relationship between two variables be linear. It also does not factor time-ordering and time-lags of the variables’ time series. As a result, depending on correlation to assess a system may cause you to overlook the many relationships that might exist within it. Correlation is therefore a useful in makingpredictions, where trends in one variable can be used to predict the trends of another. Causation, on the other hand, can be used in making decisions, as it can help to develop a better understanding of the cause-and-effects of changes made to system variables.
Now that we’ve distinguished causation from its close (but troublesome) cousin, let’s begin to get into the meat of causality with some commons terms you might encounter as you being exploring the literature.
A quick glossary
The information from this section is largely drawn from Alber (2022), Nogueira et al. (2022), Runge et al. (2019), and Weinberger (2018). It should not be considered exhaustive, by any measure, and should only be used to get your bearings as you begin to explore causality.
Causal faithfulness (“faithfulness”): The assumption that causally-connected events be probabistically dependent on each other.
Causal Markov condition: The assumption that, in a graphical model, Event Y is independent of every other event, conditional on Y’s direct causes.
Causal precedence: The assumption that Event A causes Event B if A happens before B. That is, events in the present cannot have caused events in the past.
Causal sufficiency: The assumption that all possible direct common causes of an event, or changes to a variable, have been observed.
Conditional independence: Two events or variables X and Y are conditionally independent (it is known that X does not cause Y, and vice versa) given information on an additional event or variable Z.
Confounders: “Interfering” variables that influence both the dependent and independent variables, therefore making it more challenging, or confounding, to verify to presence of a causal relationship.
Contemporaneous links: A causal relationship that exists between variables in the same time step, therefore being “con” (with, the same time as) and “temporary”. The existence of such links is one instance in which the causal precedence assumption is broken.
Directed acyclic graphs (DAGs): A graphical representation of the causal relationships between a set of variables or events. These relationships are known to be, or assumed to be, true.
Edges: The graphical representation of the links connecting two variables or events in a causal network or graph. These edges may or may not represent causal links.
Granger causality: Event X Granger-causes Event Y if predicting Y based on its own past observations and past observations of X performs better than predicting Y solely on its own past observations.
Markov equivalence class: A set of graphs that represent the same patterns of conditional independence between variables.
Nodes: The graphical representation of two events (or changes to variables).
Causality: Discovery, Inference, Data and Metrics
Causality and its related methods are typically used for two purposes: causal discovery and causal inference. Explanations for both are provided below.
Causal Discovery
Also known as causal structural learning (Tibau et al., 2022), the goal of causal discovery is to obtain causal information directly from observed or historical data. Methods used for causal discovery do not assume implicit causal links between the variables within a dataset. Instead, they begin with the assumption of a “clean slate” and attempts to generate (then analyze) models to illustrate the inter-variable links inherent to the dataset thus preserving them. The end goal of causal discovery is to approximate a graph that represents the presence or absence of causal relationships between a set of two or more nodes.
Causal Inference
Causal inference uses (and does not generate) causal graphs, focusing on thoroughly testing the truth of a the causal relationship between two variables. Unlike causal discover, it assumes that a causal relationship already exists between two variables. Following this assumption, it tests and quantifies the actual relationships between variables in the available data. It is useful for assessing the impact of one event, or a change in one variable, on another and can be applied towards studying the possible effects of altering a given system. Here, causal inference should not be confused with sensitivity analysis. The intended use of sensitivity analysis is to map changes in model output to changes in its underlying assumptions, parameterizations, and biases. Causal inference is focused on assessing the cause-and-effect relationships between variables or events in a system or model.
Data used in causal discovery and causal inference
There are two forms of data that are typically encountered in literature that use causal methods:
Comparing cross-sectional data and longitudinal data (source: Scribbr).
Cross-sectional data
Data in this form is non-temporal. Put simply, all variables available in cross-sectional data represents a single point in time. It may contain observations of multiple individuals, where each observation represents one individual and each variable contains information on a different aspect of the individual. The assumption of causal precedence does not hold for such datasets, and therefore requires additional processing to develop causal links between variables. Such datasets are handled using methods that measure causality using advanced variations of conditional independence tests (more on this later). An example of a cross-sectional dataset is the census data collected by the U.S. Census Bureau once every decade.
Longitudinal data
This form of data is a general category that also contains time-series data, which consists of a series of observations about a single (usually) subject across some time period. Such datasets are relatively easy to handle compared to cross-sectional data as the causal precedence assumption is (often) met. Therefore, most causality methods can be used to handle longitudinal data, but some common methods include the basic forms of Granger causality, cross-convergent mapping (CCM), and fast conditional independence (FCI). An example of longitudinal data would be historical rainfall gauge records of precipitation over time.
Causality Methods
The information from this section largely originates from Runge et al. (2019), Noguiera et al. (2022), and Ombadi et al. (2020).
There are several methods can can be used to discover or infer causality from the aforementioned datasets. In general, these methods are used to identify and extract causal interactions between observed data. The outcomes of these methods facilitate the filtering of relevant drivers (or variables that cause observed outcomes) from the larger set of potential ones and clarify inter-variable relationships that are often muddied with correlations. These methods measure causality in one of two ways:
Score-based methods: Such methods assign a “relevance score” to rank each proposed causal graph based on the likelihood that they accurately represent the conditional (in)dependencies between variables in a dataset. Without additional phases to refine their algorithms, these methods are computationally expensive as all potential graph configurations have to be ranked.
Constraint-based methods: These methods employ a number of statistical tests to identify “necessary” causal graph edges, and their corresponding directions. While less computationally expensive than basic score-based methods, constraint-based causality methods are limited to evaluating causal links for one node (that represents a variable) at a time. Therefore, it cannot evaluate multiple variables and potential multivariate causal relationships. It’s computational expense is also proportional to the number of variables in the dataset.
Now that we have a general idea of what causality methods can help us do, and what , let’s dive into a few general classes of causality methods.
Granger Causality
Often cited as one of the earliest mathematical representations of causality, Granger causality is a statistical hypothesis test to determine if one time series is useful in forecasting another time series based in prediction. It was introduced by Clive Granger in the 1960s and has widely been used in economics since, and more recently has found applications in neuroscience and climate science (see Runge et al. 2018, 2019). Granger causality can be used to characterize predictive causal relationships and to measure the influence of system or model drivers on variables’ time series. These relationships and influences can be uni-directional (where X Granger-causes Y, but not Y G.C. X) or bi-directional (X G.C. Y, and Y G.C. X).
A time series demonstration on how variable X G.C. Y (source: Google).
Due to its measuring predictive causality, Granger causality is thus limited to systems with independent driving variables. It cannot be used to assess multivariate systems or systems in which conditional dependencies exist, both of which are characteristic of real-world stochastic and linear processes. It is also requires separability where the causal variable (the cause) has to be independent of the influenced variable (the effect), and assumes causal precedence. It is nonetheless a useful preliminary tool for causal discovery.
Nonlinear state-space methods
An alternative to Granger causality are non-linear state-space methods, which includes methods such as convergent cross mapping (CCM). Such methods assumes that variable interactions occur in an underlying deterministic dynamical system, and then attempts to uncover causal relationships based on Takens’ theorem (see Dave’s blog posthere for an example) by reconstructing the nonlinear state-space. The key idea here is this: if event X can be predicted using time-delayed information from event Y, then X had a causal effect on Y.
Visualization on how nonlinear state-space methods reconstruct the dynamic system and identify causal relationships (source: Time Series Analysis Handbook, Chapter 6)
Convergent Cross Mapping (CCM)
Convergent Cross Mapping (Sugihara et al., 2012; Ye et al., 2015) tests the reliability of a variable Y as an estimate or predictor of variable X, revealing weak non-linear interactions between time series which might otherwise have been missed (Delforge et al, 2022). The CCM algorithm involves generating the system manifold M, the X-variable shadow manifold MX, and the Y-variable shadow manifold MY. The algorithm then samples an arbitrary set of nearest-neighbor (NN) points from MX, then determines if they correspond to neighboring points in MY. If X and Y are causally linked, they should share M as a common “attractor” manifold (a system state that can be sustained in the short-term). Variable X can therefore be said to inform variable Y .but not vice versa (unidirectionally lined). CCM can also be used to detect causality due to external forcings, where X and Y do not interact by may be driven by a common external variable Z. It is therefore best suited for causal discovery.
While CCM does not rely on conditional independence, it assumes the existence of a deterministic (but unknown) underlying system (i.e. a computer program, physics-based model) which can be represented using M. Therefore, it does not work well for stochastic time series (i.e. streamflow, coin tosses, bacteria population growth). The predictive ability of CCMs are also vulnerable to noise in data. Furthermore, it requires a long time series to de a reliable measure of causality between two variables, as a longer series decreases the NN-distance on each manifold thus improving the ability of the CCM to predict causality.
Causal network learning algorithms
On the flipside of CCMs, causal network learning algorithms assume that the underlying system in which the variables arise to be purely stochastic. These class of algorithms add or remove edges to causal graphs using criteria based in conditional or mutual independence, and assumes that both the causal Markov and faithfulness conditions holds true for all proposed graph structures. They are therefore best used for causal inference, and can be applied to cross-sectional data, as well as linear and non-linear time series.
These algorithms result in a “best estimate” graphs where all edges have the associated optimal conditional independences that best reflect observed data. They employ two stages: the skeleton discovery phase where non-essential links are eliminated, and the orientation phase where the directionality of the causal links are finalized. Because of this, these algorithms can be used to reconstruct large-scale, high-dimensional systems with interacting variables. Some of the algorithms in this class are also capable of identifying the direction of contemporaneous links, thus not being beholden to the causal precedence assumption. However, such methods can only estimate graphs up to a Markov equivalence class, and require a longer time series to provide a better prediction of causal relationships between variables.
General framework of all causal network learning algorithms (source: Runge et al., 2019).
Let’s go over a few examples of causal network learning algorithms:
The PC (Peter-Clark) algorithm
The PC algorithm begins will a fully connected graph in its skeleton phase an iteratively removes edges where conditional independences exists. It then orients the remaining edges in its orientation phase. It its earliest form, the PC algorithm was limited due to assumptions on causal sufficiency, and the lack of contemporaneous dependency handling. It also did not scale well to high-dimensional data.
Later variations attempted to overcome these limitations. For example, the momentary conditional independence PC (PCMCI) and the PCMCI+ algorithms added a further step to determine causal between variables in different timesteps and to find lagged and contemporaneous relationships separately, therefore handling contemporaneity. The PC-select variation introduced the ability to apply conditional independence tests on target variables, allowing it to process high-dimensional data. These variations can also eliminate spurious causal links. However, the PC algorithm and its variables still depend on the causal Markov, faithfulness, and sufficiency assumptions. The causal links that it detects are also relative to the feature space (Ureyen et al, 2022). This means that the directionality (or existence) of these links may change if new information is introduced to the system.
Full conditional independence (FCI)
Unlike the PC-based algorithms, FCI does not require that causal sufficiency be met although it, too, is based on iterative conditional independence tests and begins will a complete graph. Another differentiating feature between PC and FCI is the lack of the assumption of causal links directionality in the latter. Instead of a uni- or bi-directional orientation that the PC algorithm eventually assigns to its causal graph edges, the FCI has four edge implementations to account for the possibility of spurious links. Given variables X and Y, FCI’s edge implementations are as follows:
X causes Y
X causes Y or Y causes X
X causes Y or there are unmeasured confounding variables
X causes Y, Y causes X, there are unmeasured confounding variables, or some combination of both
There are also several FCI variations that allow improved handling of large datasets, high dimensionality, and contemporaneous variables. For example, the Anytime and the Adaptive Anytime FCI restricts the maximum number of variables to be considered as drivers, and the time series FCI (TsFCI) uses sliding windows to transform the original, long time series into a set of “independent” subsamples that can be treated as cross-sectional. To effectively use FCI, however, the data should be carefully prepared using Joint Causal Inference (JCI) to allow the generated graph to include both variable information and system information, to account for system background knowledge (Mooij et al., 2016).
Structural causal models (SCMs)
Similar to causal network learning algorithms, SCMs assumes a purely stochastic underlying system and uses DAGs to model the flow of information. It also can detect causal graphs to within a Markov equivalence class. Unlike causal network learning algorithms, SCMs structure DAGs that consist of a set of endogenous (Y) and exogenous (X) variables that are connected by a set of functions (F) that determine the values of Y based on the values of X. Within this context, a node represents the a variable x and y in X and Y, while an edge represents a function f within F. By doing so, SCMs enable the discovery of causal directions in cases where the causal direction cannot be inferred with conditional independence-based methods. SCMs can also handle a wide range of systems (linear, non linear, various noise probability distributions). This last advantage is one of the limitations of SCMs: it requires that some information on underlying structure of the system is known a priori (e.g. the system is assumed to be linear with at least one of the noise terms being drawn from a Gaussian distribution). SCMs are best used for causal inference, as causal links between variables have to be assumed during the generation of SCMs.
Information-theoretic algorithms
Finally, we have information-theoretic (IT) algorithms, which are considered an extension of the GC methods and allows the verification of nonlinear relationships between system variables, and therefore is best used for causal inference. IT algorithms measure transfer entropy (TE), which is defined as the amount of shared information between variables X and Y when both are conditioned on external variable Z. The magnitude of TE reflects the Shannon Entropy reduction in Y when, given Z, information on X is added to the system. For further information on IT and TE, Andrew’s blog post and Keyvan’s May 2020 and June 2020 posts further expand on the theory and application of both concepts.
There are a couple of assumptions that come along with the use of IT algorithms. First, like both SCMs and causal learning network algorithms, it assumes that the underlying system is purely stochastic. It is also bound to causal precedence, and asssumes that the causal variable X provides all useful information for the prediction of the effect Y, given Z. In addition, IT algorithms benefit from longer time series to improve predictions of causal links between variables. On the other hand, it does not make assumptions about the underlying structure of the data and can detect both linear and nonlinear causal relationships.
Prior WaterProgramming blog posts
That was a lot! But if you would like a more detailed dive into causality and/or explore some toy problems, there are a number of solid blog posts written that focus on the underlying math and concepts central to the approaches used in causal discovery and/or inference:
In this blog post, we introduced causality and compared it to correlation. We listed a glossary of commonly-used terms in causality literature, as well as distinguished causal discovery from causal inference. Next, we explored a number of commonly-used causality methods: Granger causality, CCM, conditional independence-based causal learning network algorithms, SCMs, and information-theoretic algorithms.
From this overview, it can be concluded that methods to discovery and infer causal relationships are powerful tool that enable us to identify cause-and-effect links between seemingly unrelated system variables. Improvements to these methods are pivotal to improve climate models, increase AI explainability, and aid in better, more transparent decision-making. Nevertheless, these methods face challenges (Tibau et al. 2022) that include, but are not limited to:
Handling gridded or spatio-temporally aggregated data
Representing nonlinear processes that may interact across time scales
Handling non-Gaussian variable distributions and data non-stationarity
Handling partial observability where only a subset of system variables is observed, thus challenging the causal sufficiency assumption
Dealing with mixed data types (discriete vs continuous)
Lack of benchmarking approaches due to lack of ground truth data
This brings us to the end of the post – do take a look at the References for a list of key literature and online articles that will be helpful as you begin learning about causality. Thank you for sticking with me and happy exploring!
Delforge, D., de Viron, O., Vanclooster, M., Van Camp, M., & Watlet, A. (2022). Detecting hydrological connectivity using causal inference from time series: Synthetic and real Karstic case studies. Hydrology and Earth System Sciences, 26(8), 2181–2199. https://doi.org/10.5194/hess-26-2181-2022
Nogueira, A. R., Pugnana, A., Ruggieri, S., Pedreschi, D., & Gama, J. (2022). Methods and tools for causal discovery and causal inference. WIREs Data Mining and Knowledge Discovery, 12(2). https://doi.org/10.1002/widm.1449
Ombadi, M., Nguyen, P., Sorooshian, S., & Hsu, K. (2020). Evaluation of methods for causal discovery in hydrometeorological systems. Water Resources Research, 56(7). https://doi.org/10.1029/2020wr027251
Runge, J. (2018). Causal network reconstruction from time series: From theoretical assumptions to practical estimation. Chaos: An Interdisciplinary Journal of Nonlinear Science, 28(7), 075310. https://doi.org/10.1063/1.5025050
Runge, J., Bathiany, S., Bollt, E., Camps-Valls, G., Coumou, D., Deyle, E., Glymour, C., Kretschmer, M., Mahecha, M. D., Muñoz-Marí, J., van Nes, E. H., Peters, J., Quax, R., Reichstein, M., Scheffer, M., Schölkopf, B., Spirtes, P., Sugihara, G., Sun, J., Zscheischler, J. (2019). Inferring causation from time series in Earth System Sciences. Nature Communications, 10(1). https://doi.org/10.1038/s41467-019-10105-3
Sugihara, G., May, R., Ye, H., Hsieh, C.-hao, Deyle, E., Fogarty, M., & Munch, S. (2012). Detecting causality in complex ecosystems. Science, 338(6106), 496–500. https://doi.org/10.1126/science.1227079
Tibau, X.-A., Reimers, C., Gerhardus, A., Denzler, J., Eyring, V., & Runge, J. (2022). A spatiotemporal stochastic climate model for benchmarking causal discovery methods for teleconnections. Environmental Data Science, 1. https://doi.org/10.1017/eds.2022.11
Uereyen, S., Bachofer, F., & Kuenzer, C. (2022). A framework for multivariate analysis of land surface dynamics and driving variables—a case study for Indo-Gangetic River basins. Remote Sensing, 14(1), 197. https://doi.org/10.3390/rs14010197
Ye, H., Deyle, E. R., Gilarranz, L. J., & Sugihara, G. (2015). Distinguishing time-delayed causal interactions using convergent cross mapping. Scientific Reports, 5(1). https://doi.org/10.1038/srep14750














 and
and  are the total number of infrastructure options and potential future scenarios to consider
are the total number of infrastructure options and potential future scenarios to consider is the probability of occurrence for scenario
is the probability of occurrence for scenario 
 is one year within the entire bond term
is one year within the entire bond term ![T =[1,30]](https://s0.wp.com/latex.php?latex=T+%3D%5B1%2C30%5D&bg=ffffff&fg=444444&s=0&c=20201002)
 is the total bond payment, or bond principal
is the total bond payment, or bond principal  is the discount rate in scenario
is the discount rate in scenario  for infrastructure option
for infrastructure option 






 is the final built capacity of infrastructure option
is the final built capacity of infrastructure option 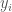 is a binary
is a binary ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002) variable indicating if an infrastructure option is built (1) or not (0)
variable indicating if an infrastructure option is built (1) or not (0) is the daily demand in scenario
is the daily demand in scenario  is the daily water deliveries from infrastructure option
is the daily water deliveries from infrastructure option  is the ratio of non-revenue water (NRW) if infrastructure option
is the ratio of non-revenue water (NRW) if infrastructure option  is the net revenue from fulfilling demand (after accounting for NRW) using infrastructure option
is the net revenue from fulfilling demand (after accounting for NRW) using infrastructure option  , please refer to
, please refer to 
 is the infrastructure net present cost,
is the infrastructure net present cost,  is bond term for an infrastructure option, and is the discount rate for a given year
is bond term for an infrastructure option, and is the discount rate for a given year 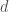 for an infrastructure option since its bond was issued. The value of
for an infrastructure option since its bond was issued. The value of ![\frac{P[BR(1+BR)^T]}{(1+BR)^{T}-1}](https://s0.wp.com/latex.php?latex=%5Cfrac%7BP%5BBR%281%2BBR%29%5ET%5D%7D%7B%281%2BBR%29%5E%7BT%7D-1%7D&bg=ffffff&fg=444444&s=0&c=20201002)
 is the bond principal (the total value of the bond),
is the bond principal (the total value of the bond),  is the bond interest rate to be paid to the creditor throughout the bond term
is the bond interest rate to be paid to the creditor throughout the bond term  . All payments are discounted to their present value. The value of the bond principal is dependent on the capacity of the infrastructure option and is calculated as a function of the fixed and variable capital costs:
. All payments are discounted to their present value. The value of the bond principal is dependent on the capacity of the infrastructure option and is calculated as a function of the fixed and variable capital costs:
 is the capital cost of infrastructure option
is the capital cost of infrastructure option  variable indicating if option
variable indicating if option  is the variable capital cost of infrastructure option
is the variable capital cost of infrastructure option ![R_{s,i}=[(D_{s,i}\times UR \times \text{households})(1-\rho_{i})] - OC_{s,i}](https://s0.wp.com/latex.php?latex=R_%7Bs%2Ci%7D%3D%5B%28D_%7Bs%2Ci%7D%5Ctimes+UR+%5Ctimes+%5Ctext%7Bhouseholds%7D%29%281-%5Crho_%7Bi%7D%29%5D+-+OC_%7Bs%2Ci%7D&bg=ffffff&fg=444444&s=0&c=20201002)
 is the per-household uniform water rate, and
is the per-household uniform water rate, and  is the percentage of water lost during transmission given that infrastructure
is the percentage of water lost during transmission given that infrastructure  is Helm’s Keep’s daily operating costs per capita where
is Helm’s Keep’s daily operating costs per capita where
 is the variable operating cost of
is the variable operating cost of  should not exceed 1.25 times that of Helm’s Keep’s annual net revenue
should not exceed 1.25 times that of Helm’s Keep’s annual net revenue  of water demand increase
of water demand increase  , Federal Reserve bond interest rate, and discount rate. The probability of each scenario is listed in the table below:
, Federal Reserve bond interest rate, and discount rate. The probability of each scenario is listed in the table below: ?
?![y_i \in {0,1} \forall i=[1,2,3]](https://s0.wp.com/latex.php?latex=y_i+%5Cin+%7B0%2C1%7D+%5Cforall+i%3D%5B1%2C2%2C3%5D&bg=ffffff&fg=444444&s=0&c=20201002)

 ,
,  and
and  be the amount of water delivered, bond rate, and discount rate, in scenario
be the amount of water delivered, bond rate, and discount rate, in scenario ![PMT_{s,i}=(C_i y_i + VCC_i x_i) \frac{[BR_{s,i}(1+BR_{s,i})^{30}]}{(1+BR_{s,i})^{30} -1}](https://s0.wp.com/latex.php?latex=PMT_%7Bs%2Ci%7D%3D%28C_i+y_i+%2B+VCC_i+x_i%29+%5Cfrac%7B%5BBR_%7Bs%2Ci%7D%281%2BBR_%7Bs%2Ci%7D%29%5E%7B30%7D%5D%7D%7B%281%2BBR_%7Bs%2Ci%7D%29%5E%7B30%7D+-1%7D&bg=ffffff&fg=444444&s=0&c=20201002)


![R_{s,i} = [(3420D_{s,i})(1-\rho_i)] - (VOC_i\frac{D_{s,i}}{\rho_s})](https://s0.wp.com/latex.php?latex=R_%7Bs%2Ci%7D+%3D+%5B%283420D_%7Bs%2Ci%7D%29%281-%5Crho_i%29%5D+-+%28VOC_i%5Cfrac%7BD_%7Bs%2Ci%7D%7D%7B%5Crho_s%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)
 .
.
 is the number of policy inputs
is the number of policy inputs is the number of policy outputs
is the number of policy outputs is the number of radial basis functions (RBFs) used
is the number of radial basis functions (RBFs) used is a day within the entire record, while $t\%365$ is a calendar year (day of year, DOY)
is a day within the entire record, while $t\%365$ is a calendar year (day of year, DOY) is the number of reservoirs
is the number of reservoirs is the policy-prescribed release at reservoir $k$ at time $t$
is the policy-prescribed release at reservoir $k$ at time $t$ is the system state, aka the storage at the reservoir
is the system state, aka the storage at the reservoir is a vector of system variables for state $a$
is a vector of system variables for state $a$ and $b_{n,m}$ are the centers and radii of policy input $m \in M$ for RBF function $n \in N$
and $b_{n,m}$ are the centers and radii of policy input $m \in M$ for RBF function $n \in N$ is the weight of RBF function $n \in N$
is the weight of RBF function $n \in N$
 .
.
 to the system states at
to the system states at  . But how do we calculate the derivatives of the policy
. But how do we calculate the derivatives of the policy ![\frac{\delta u_{t}^{k}}{\delta(x_t)_a} = \sum_{n=1}^{N}\Biggl\{\frac{-2w_{n}[(x_{t})_{a}-c_{n,a}]}{b_{n,a}^2}\text{ exp}\Biggl[-\sum_{m=1}^{M}\Bigl(\frac{(x_{t})_{j}-c_{n,m}}{b_{n,m}}\Bigr)^2\Biggr]\Biggr\}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta+u_%7Bt%7D%5E%7Bk%7D%7D%7B%5Cdelta%28x_t%29_a%7D+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7D%5CBiggl%5C%7B%5Cfrac%7B-2w_%7Bn%7D%5B%28x_%7Bt%7D%29_%7Ba%7D-c_%7Bn%2Ca%7D%5D%7D%7Bb_%7Bn%2Ca%7D%5E2%7D%5Ctext%7B+exp%7D%5CBiggl%5B-%5Csum_%7Bm%3D1%7D%5E%7BM%7D%5CBigl%28%5Cfrac%7B%28x_%7Bt%7D%29_%7Bj%7D-c_%7Bn%2Cm%7D%7D%7Bb_%7Bn%2Cm%7D%7D%5CBigr%29%5E2%5CBiggr%5D%5CBiggr%5C%7D&bg=ffffff&fg=444444&s=0&c=20201002)
![u_{t}^{k} = \sum_{n=1}^{N}w_{n}^{k}\text{ exp}\Biggr[-\sum_{m=1}^{M}\Biggl(\frac{(x_n)_m - c_{n,m}}{b_{n,m}}\Biggr)^2\Biggr]](https://s0.wp.com/latex.php?latex=u_%7Bt%7D%5E%7Bk%7D+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7Dw_%7Bn%7D%5E%7Bk%7D%5Ctext%7B+exp%7D%5CBiggr%5B-%5Csum_%7Bm%3D1%7D%5E%7BM%7D%5CBiggl%28%5Cfrac%7B%28x_n%29_m+-+c_%7Bn%2Cm%7D%7D%7Bb_%7Bn%2Cm%7D%7D%5CBiggr%29%5E2%5CBiggr%5D&bg=ffffff&fg=444444&s=0&c=20201002)
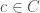 and radii
and radii  for each input variable, and a weight
for each input variable, and a weight  . It is a type of Gaussian process kernel that informs the model (in our case, the Red River model) of the degree of similarity between two input points (Natsume, 2022). Each input is shifted by its distance from its respective “optimal” center point, and scaled by its “optimal” radius. The overall influence of an RBF function on the final release decision is then weighted by an “optimal” constant, where the sum of all
. It is a type of Gaussian process kernel that informs the model (in our case, the Red River model) of the degree of similarity between two input points (Natsume, 2022). Each input is shifted by its distance from its respective “optimal” center point, and scaled by its “optimal” radius. The overall influence of an RBF function on the final release decision is then weighted by an “optimal” constant, where the sum of all  ,
,  across all following timesteps, and avoiding the storage of information on prior releases
across all following timesteps, and avoiding the storage of information on prior releases  .
. over all years. In this case, the timestep is in daily increments.
over all years. In this case, the timestep is in daily increments. ).
). 


















