
In this post, we will be performing time-varying sensitivity analysis (TVSA) to assess how the use of information from reservoir storage and downstream city levels change across time when attempting to meet competing objectives in the Red River basin. This exercise is derived from the Quinn et al (2019) paper listed in the references below. You will be able to find all the files needed for this training in this GitHub repository. You can also follow along this tutorial at this Binder here.
Before beginning, here are some preliminary suggested readings to help you better understand TVSA and Radial Basis Functions (RBFs), which will be used in this training:
- Herman, J. D., Reed, P. M., & Wagener, T. (2013). Time-varying sensitivity analysis clarifies the effects of watershed model formulation on model behavior. Water Resources Research, 49(3), 1400–1414. https://doi.org/10.1002/wrcr.20124
- Giuliani, M., Zaniolo, M., Castelletti, A., Davoli, G., & Block, P. (2019). Detecting the state of the climate system via artificial intelligence to improve seasonal forecasts and inform reservoir operations. Water Resources Research, 55(11), 9133–9147. https://doi.org/10.1029/2019wr025035
- Quinn, J. D., Reed, P. M., Giuliani, M., & Castelletti, A. (2019). What is controlling our control rules? opening the black box of multireservoir operating policies using time‐varying sensitivity analysis. Water Resources Research, 55(7), 5962–5984. https://doi.org/10.1029/2018wr024177
- Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
The Red River System
The Red River basin consists of four reservoirs: Son La (SL), Thac Ba (TB), Tuyen Quang (TQ), and Hoa Binh (HB), shown in the figure below. The reservoirs’ operators must make daily decisions on the volume of water to release from each reservoir to achieve the following competing objectives:
- Protect the city of Hanoi (which lies downstream of the four reservoirs) from flooding by managing city water levels.
- Achieve maximum possible hydropower production from each reservoir to serve the energy demands of Hanoi.
- Minimize agricultural water supply deficit to meet irrigation needs for the region.

The reservoir operators use information from the projected storage levels at each reservoir and water level forecasts to make their daily release decisions. These decisions in turn determine if they are able to meet their three objectives. Therefore, it is important to understand how different types of information is used and coordinated throughout the year to make these daily decisions.
This exercise
To complete this exercise, you should have the following subfolders and files within your Binder.
HydroInfo_100_thinned.resultfilethat contains the decision variables and objective values for all sets of optimal decisions. If this file is missing from the main folder structure, you download the original version here.daily/SolnXX/the subfolder that contains text files of each reservoir’s daily decision variables (the columns) across 1,000 years (the rows) for Solution XX.
Most of the daily data folders are large and cannot be stored on the linked GitHub repository. Note that only Soln33 can be found in the daily\ folder. If you would like to perform TVSA on other solutions, please download them separately here.
All in all, there are four selected solutions, named according to the objectives that they prioritize and their tradeoff characteristics:
- The “Best Flood” policy: Solution 33
- The “Best Hydropower” policy: Solution 37
- The “Best Deficit” policy: Solution 52
- The “Compromise” policy: Solution 35
Learning goals
In this exercise, we will:
- Briefly explain RBFs (Giuliani et al., 2016; Quinn et al., 2017; Giuliani et al., 2019).
- Unpack and understand the underlying mechanisms for calculating analytical variance-based first- and second-order sensitivity indices.
- Perform time-varying sensitivity analysis for each of the four listed solutions.
- Analyze the resulting figures to understand how information use changes throughout the year.
Understanding TVSA
Let’s walk through some key equations before we proceed. In this section, you will also find the Equation numbers that link these equations to their origins in the Quinn et al. (2019) paper listed above.
First, let’s look at some of the notation we will be using:
is the number of policy inputs
is the number of policy outputs
is the number of radial basis functions (RBFs) used
is a day within the entire record, while $t\%365$ is a calendar year (day of year, DOY)
is the number of reservoirs
is the policy-prescribed release at reservoir $k$ at time $t$
is the system state, aka the storage at the reservoir
is a vector of system variables for state $a$
and $b_{n,m}$ are the centers and radii of policy input $m \in M$ for RBF function $n \in N$
is the weight of RBF function $n \in N$
Calculating the first-order sensitivity analysis
The following equation is drawn from Eqn.10 of Quinn et al. (2019):

This equation describes the annual first-order contributions of only variable $(x_t)_a$ to the system state at 
Next, from Eqn.11 of Quinn et al. (2019):

This equation describes the annual second-order contributions for variable 

Calculating the derivatives
We can calculate the derivative by taking the first partial differential of the policy with respect to each of its inputs. This approach is generalizable to all forms of policy formulation, but in this case, we will take the derivative with respect to the RBF function shown in Eqn 8 of Quinn et al. (2019).
![\frac{\delta u_{t}^{k}}{\delta(x_t)_a} = \sum_{n=1}^{N}\Biggl\{\frac{-2w_{n}[(x_{t})_{a}-c_{n,a}]}{b_{n,a}^2}\text{ exp}\Biggl[-\sum_{m=1}^{M}\Bigl(\frac{(x_{t})_{j}-c_{n,m}}{b_{n,m}}\Bigr)^2\Biggr]\Biggr\}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta+u_%7Bt%7D%5E%7Bk%7D%7D%7B%5Cdelta%28x_t%29_a%7D+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7D%5CBiggl%5C%7B%5Cfrac%7B-2w_%7Bn%7D%5B%28x_%7Bt%7D%29_%7Ba%7D-c_%7Bn%2Ca%7D%5D%7D%7Bb_%7Bn%2Ca%7D%5E2%7D%5Ctext%7B+exp%7D%5CBiggl%5B-%5Csum_%7Bm%3D1%7D%5E%7BM%7D%5CBigl%28%5Cfrac%7B%28x_%7Bt%7D%29_%7Bj%7D-c_%7Bn%2Cm%7D%7D%7Bb_%7Bn%2Cm%7D%7D%5CBigr%29%5E2%5CBiggr%5D%5CBiggr%5C%7D&bg=ffffff&fg=444444&s=0&c=20201002)
For reference, here is the original RBF function (Eqn. 8 of Quinn et al. (2019)):
![u_{t}^{k} = \sum_{n=1}^{N}w_{n}^{k}\text{ exp}\Biggr[-\sum_{m=1}^{M}\Biggl(\frac{(x_n)_m - c_{n,m}}{b_{n,m}}\Biggr)^2\Biggr]](https://s0.wp.com/latex.php?latex=u_%7Bt%7D%5E%7Bk%7D+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7Dw_%7Bn%7D%5E%7Bk%7D%5Ctext%7B+exp%7D%5CBiggr%5B-%5Csum_%7Bm%3D1%7D%5E%7BM%7D%5CBiggl%28%5Cfrac%7B%28x_n%29_m+-+c_%7Bn%2Cm%7D%7D%7Bb_%7Bn%2Cm%7D%7D%5CBiggr%29%5E2%5CBiggr%5D&bg=ffffff&fg=444444&s=0&c=20201002)
A quick aside on RBFs
As shown in the equation above, an RBF is characterized by three parameters: centers 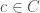

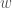
Herein lies the key advantage of using RBFs: instead of identifying the optimal output (the releases) at each timestep, optimizing RBFs finds optimal values of 


General steps
Time-varying sensitivity analysis in general is conducted as follows:
- Calculate the variance and covariance of each input variable for each timestep
over all years. In this case, the timestep is in daily increments.
- Calculate the partial first and second derivatives of each release policy for each day with respect to the input variables at each location.
- Compute the first- and second-order contributions of each input variable across all timesteps by:
- Multiplying the variances with the first-order derivatives
- Multiplying the covariances with their respective second-order derivatives
- Plot the contribution of each input variable to daily release policies (i.e. what kind of information is being used to make a decision on releases from reservoir
).
Setting up the problem
To follow along with this tutorial, ensure that all files are located in their appropriate directories, open up the Jupyter notebook named tvsa_exercise.ipynb. Now, let’s import all the required libraries and set some constant parameters. We will be setting the values for the number of input parameters,
# import the libraries
import numpy as np
import math
import matplotlib.pyplot as plt
import seaborn as sns
from calc_SI import *
from plot_SI import *
sns.set_style("dark")
# set the parameters
M = 5 # Storage at the four reservoirs and the forecasted water levels in Hanoi
N = 12 # Number of RBFs to parameterize. Set a minimum of M+K
K = 4 # Number of outputs (release decisions at the four reservoirs)
num_years = 1000 # Number of years to simulate
We will also need to define our input and output names. These are the column names that will appear in the output .txt files needed to plot our figures later in this exercise. Let’s also set the solution that we would like to analyze.
inputNames = ['sSL', 'sHB', 'sTQ', 'sTB', 'HNwater'] # the storage at Son La, Hoa Bing, Tuyen Quang, Thac Ba, and the water level at Hanoi
outputNames = ['rSL', 'rHB', 'rTQ', 'rTB'] # the release at Son La, Hoa Bing, Tuyen Quang, Thac Ba
policy_file = 'HydroInfo_100_thinned.resultfile'
soln_num = 33
Performing TVSA
The main calculations that output the sensitivity index for each day of the year across 1,000 years is performed by the function called calc_analytical_SI. This function can be found in the calc_SI.py file within this folder. It it highly recommended that you take the time to go through and understand the mechanisms of time-varying sensitivity analysis after completing this exercise. This step can take anywhere from 30-50 minutes, depending on your computing hardware. Feel free to comment out the line of code below if you would only like to plot the TVSA figures.
calc_analytical_SI(M, N, K, policy_file, soln_num, num_years, inputNames, outputNames)
If you are successful in running this function, you should see two new folders in daily/Soln_XX/ called release_decisions and Figures. The latter will become important in a while, when we begin to generate our TVSA figures. For now, open release_decisions to check if the files containing the sensitivity of each reservoir’s release decisions (e.g. rHB.txt) have populated the folder.
Are they there? Great! Let’s move on to generating the figures.
Plot the results
Now that we have the sensitivity indices of each reservoir’s release decision over time, let’s visualize how they use storage and water level forecast information. You can do this by using the plot_tvsa_policy function found in the plot_SI.py file. As before, you’re advised to attempt understand the script once you have completed this exercise.
To begin, let’s specify the name of the inputs that you would like to see in the legends of the figure. For this exercise, we will re-use the inputNames list defined prior to this. We will also need to add one more to this list, called interactions, which quantify the influence of input variable interactions on release decisions. In general, the list of input names and their associated colors should have length $M+1$.
Feel free to replace this with a list of other names that is more intuitive for you. We will also specify the colors they will be shown in. Since there are six inputs, we will have to specify six colors.
# specify the legend labels for each input and their respective colors
input_list = inputNames + ['interactions']
# for Son La, Hoa Binh, Tuyen Quang, Thac Ba, Hanoi, and their interactions respectively
input_colors = ['#FFBF00', '#E83F6F', '#2274A5', '#E3D7FF', '#92BFB1', '#F7A072']
For now, let’s see how this information affect’s Son La’s release decisions over time for the “Best Flood” solution. This is the solution that minimizes the “worst first-percentile of the amount by which the maximum water level in Hanoi exceed 11.25m” (Quinn et al., 2019).
plot_tvsa_policy(num_years, 33, input_list, input_colors, 'rSL', 'Sensitivity of Son La releases')
If all the steps have been completed, you should be able to view the following image:

If you’d like to see and automatically save the plots for all four reservoirs, you can opt for a for loop:
res_names = ['Son La', 'Hoa Binh', 'Tuyen Quang', 'Thac Ba']
for r in range(len(outputNames)):
plot_name = res_names[r] + ' releases'
plot_tvsa_policy(num_years, 33, input_list, input_colors,
outputNames[r], plot_name + ' releases')
At the end of this, you should be able to locate all the figure in the daily/Soln_XX/Figures folder, where XX is the solution number of your choice.
Analyze the results
The figure below shows the time-varying sensitivity of the release decisions at all four reservoirs to the input variables. As a quick reminder, we are looking at Solution 33, which is the “Best Flood” solution.

In Figure 3 above, note the visual similarity between both Hoa Binh and Son La’s components’ contributions to their respective variance. The similarities between the pair of reservoirs could potentially be attributed to the geographic characteristics of the Red River basin (although further analysis is required here). In Figure 1, both Son La and Hoa Binh belong to the same Red River tributary, with the former preceding the latter. Their release decisions dominantly use information from Hanoi’s water level forecasts, particularly during the five months that correspond to Vietnam’s May-September monsoon season.
During the same period, the variance in Thac Ba and Tuyen Quang’s release decision have relatively-even contributions from Son La’s storage levels, Hanoi’s water level forecast, and interactions between different types of information. This indicates that it is crucial for the reservoir managers at Thac Ba and Tuyen Quang to carefully monitor these three main information sources during the monsoon period. Higher resolution data, and more frequent monitoring may be valuable during this time.
Interestingly, storage information from Hoa Binh appears to contribute most to the release decision variances of each reservoir before at and at the beginning of the monsoon. Hoa Binh’s storage information is particularly important during the first half of the year at all four reservoirs, which happens to be immediately before and during the monsoon season. During the same period of time, interactions between information from all other reservoirs also plays an important role in regulating release decisions.
Post-monsoon, the implications of interactions on release decisions becomes negligible, and each reservoir’s releases become dominantly driven by storage levels at Hoa Binh and Hanoi’s water levels once more, approximately mirroring the distribution of information contributions during the pre-monsoon period. However, storage levels at Thac Ba and Tuyen Quang play a more important role at determining release decisions during this time, and their contributions to release decisions is greater for their own reservoirs. Notably, information on storage at Thac Ba has the least influence for all reservoirs’ release decisions (including its own) throughout the entire year. This is likely due to it being the smallest reservoir in the system (Table 1; Quinn et al., 2019).
These observations can lead us to hypothesize that:
- For a policy that prioritizes minimizing flooding in Hanoi, information on storage levels at the Hoa Binh reservoir is vital.
- Storage levels at Hoa Binh should therefore be closely monitored and recorded at high resolution.
- During the monsoon, water levels in Hanoi are also key to release decisions and should be recorded at regular intervals.
- Interactions between difference sources of information is also a significant contributor to the variance across all reservoirs’ release decisions; treating decisions and conditions at each reservoir as independent of others can result in under-estimating the risk of flooding.
Summary
Overall, TVSA is a useful method to help decision-makers identify what information is useful, and when it is best used. This information is valuable when determining the resolution at which observations should be taken, or if downscaling is appropriate. Note that this method of calculating sensitivity relies on variance-based global sensitivity analysis method. This is where the sensitivity of an output to a provided input (or a combination thereof) is quantified as the contribution of total variance in the output by that input (or a combination of inputs). However, such methods may be biased by heavy-tailed distributions or outliers and therefore should be used only where appropriate (e.g. when the output distributions have analyzed, or when outputs are not multimodal; Reed et al., 2022). As you may have noticed, TVSA is also a computationally expensive process that requires a significant amount of time. This requirement grows exponentially with the number of simulations/years that you are calculating variance across, or as the number of inputs and outputs increase.
In this exercise, we performed time varying sensitivity analysis to understand how each reservoir within the Red River system in Vietnam uses storage and water level information on a day-to-day basis, and how this use of information changes over time. Similar methods have also been used to better understand how the formulation of hydrological processes affect watershed model behavior (Herman et al., 2013; Medina and Muñoz, 2020; Basijokaite and Kelleher, 2021), and asses information use in microgrid energy management (Liu et al., 2023). Post-exercise, do take some time to peruse these papers (linked before in the References section).
That said, thank you for sticking around and hope you learned a little something here!
References
- Basijokaite, R., & Kelleher, C. (2021). Time‐varying sensitivity analysis reveals relationships between watershed climate and variations in annual parameter importance in regions with strong interannual variability. Water Resources Research, 57(1). https://doi.org/10.1029/2020wr028544
- Giuliani, M., Castelletti, A., Pianosi, F., Mason, E., & Reed, P. M. (2016). Curses, tradeoffs, and scalable management: Advancing Evolutionary Multiobjective Direct Policy search to improve water reservoir operations. Journal of Water Resources Planning and Management, 142(2). https://doi.org/10.1061/(asce)wr.1943-5452.0000570
- Herman, J. D., Reed, P. M., & Wagener, T. (2013a). Time-varying sensitivity analysis clarifies the effects of watershed model formulation on model behavior. Water Resources Research, 49(3), 1400–1414. https://doi.org/10.1002/wrcr.20124
- Liu, M.V., Reed, P.M., Gold, D.F., Quist, G., Anderson, C.L. (2023). A Multiobjective Reinforcement Learning Framework for Microgrid Energy Management. arXiv.
https://doi.org/10.48550/arXiv.2307.08692 - Medina, Y., & Muñoz, E. (2020). A simple time-varying sensitivity analysis (TVSA) for assessment of temporal variability of hydrological processes. Water, 12(9), 2463. https://doi.org/10.3390/w12092463
- Natsume, Y. (2022, August 23). Gaussian process kernels. Medium. https://towardsdatascience.com/gaussian-process-kernels-96bafb4dd63e.
- Quinn, J. D., Reed, P. M., Giuliani, M., & Castelletti, A. (2019). What is controlling our control rules? opening the black box of multireservoir operating policies using time‐varying sensitivity analysis. Water Resources Research, 55(7), 5962–5984. https://doi.org/10.1029/2018wr024177
- Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623

















