

Last week, Lillian and I published the first post in a series of training post studying the “Fisheries Game“, which is a decision making problem within a complex, non-linear, and uncertain ecological context.
In preparing for that post, I learned about the Ipywidgets python library for widget construction. It stood out to me as a tool for highlighting the influence of parametric uncertainty on model performance. More broadly, I think it has great as an educational or data-narrative device.
This blogpost is designed to highlight this potential, and provide a basic introduction to the library. A tutorial demonstration of how an interactive widget is constructed is provided, this time using the HYMOD rainfall-runoff model.
This post is intended to be viewed through a Jupyter Notebook for interaction, which can be accessed through a Binder at this link!
The Binder was built with an internal environment specification, so it should not be necessary to install any packages on your local machine! Because of this, it may take a minute to load the page.
Alternatively, you can pull the source code and run the Jupyter Notebook from your local machine. All of the source code is available in a GitHub repository: Ipywidget_Demo_Interactive_HYMOD.
If using your local machine, you will first need to install the Ipywidget library:
pip install ipywidgets
Let’s begin!
HYMOD Introduction
HYMOD is a conceptual rainfall-runoff model. Given some observed precipitation and evaporation, a parameterized HYMOD model simulates the resulting down-basin runoff.
This post does not focus on specific properties or performance of the HYMOD model, but rather uses the model as a demonstration of the utility of the Ipywidget library.
I chose to use the HYMOD model for this, because the HYMOD model is commonly taught in introductory hydrologic modeling courses. This demonstration shows how an Ipywidget can be used in an educational context. The resulting widget can allow students to interact in real-time with the model behavior, by adjusting parameter values and visualizing the changes in the resulted streamflow.
If you are interested in the technical details of implementing the HYMOD model, you can dig into the source code, available (and throughly commented/descriptive) in the repository for this post: Ipywidget_Demo_Interactive_HYMOD.
HYMOD represents surface flow as a series of several quick-flow reservoirs. Groundwater flow is represented as a single slow-flow reservoir. The reservoirs have constant flow rates, with the quick-flow reservoir rate, Kq, being greater than the slow-flow reservoir rate, Ks.

HYMOD Parameters:
Like any hydrologic model, the performance of HYMOD will be dependent upon the specified parameter values. There are several parameters that can be adjusted:
- Cmax: Max soil moisture storage (mm) [10-2000]
- B: Distribution of soil stores [0.0 – 7.0]
- Alpha: Division between quick/slow routing [0.0 – 1.0]
- Kq: Quick flow reservoir rate constant (day^-1) [0.15 – 1.0]
- Ks: Slow flow reservoir rate constant. (day^-1) [0.0 – 0.15]
- N: The number of quick-flow reservoirs.
Interactive widget demonstration
I’ve constructed an Ipywidets object which allows a user to visualize the impact of the HYMOD model parameters on the resulting simulation timeseries. The user also has the option to select from three different error metrics, which display in the plot, and toggle the observed timeseries plot on and off.
Later in this post, I will give detail on how the widget was created.
Before provided the detail, I want to show the widget in action so that you know the expectation for the final product.
The gif below shows the widget in-use:

Ipywidgets Introduction
The Ipywdiget library allows for highly customized widgets, like the one above. As with any new tool, I’d recommend you check out the documentation here.
Below, I walk through the process of generating the widget shown above.
Lets begin!
Import the library
# Import the library
import ipywidgets as widgets
Basic widget components
Consider an Ipywidget as being an arrangement of modular components.
The tutorial walks through the construction of five key widget components:
- Variable slider
- Drop-down selectors
- Toggle buttons
- Label objects
- Interactive outputs (used to connect the plot to the other three components)
In the last section, I show how all of these components can be arranged together to construct the unified widget.
Sliders
Sliders are one of the most common ipywidet tools. They allow for manual manipulation of a variable value. The slider is an object that can be passed to the interactive widget (more on this further down).
For my HYMOD widget, I would like to be able to manipulate each of the model parameters listed above. I begin by constructing a slider object for each of the variables.
Here is an example, for the C_max variable:
# Construct the slider
Cmax_slider = widgets.FloatSlider(value = 500, min = 10, max = 2000, step = 1.0, description = "C_max",
disabled = False, continuous_update = False, readout = True, readout_format = '0.2f')
# Display the slider
display(Cmax_slider)
Notice that each slider recieves a specified min, max, and step corresponding to the possible values. For the HYMOD demo, I am using the parameter ranges specified in Herman, J.D., P.M. Reed, and T. Wagener (2013), Time-varying sensitivity analysis clarifies the effects of watershed model formulation on model behavior.
I will construct the sliders for the remaining parameters below. Notice that I don’t assign the description parameter in any of these sliders… this is intentional. Later in this tutorial I will show how to arrange the sliders with Label() objects for a cleaner widget design.
# Construct remaining sliders
Cmax_slider = widgets.FloatSlider(value = 100, min = 10, max = 2000, step = 1.0, disabled = False, continuous_update = False, readout = True, readout_format = '0.2f')
B_slider = widgets.FloatSlider(value = 2.0, min = 0.0, max = 7.0, step = 0.1, disabled = False, continuous_update = False, readout = True, readout_format = '0.2f')
Alpha_slider = widgets.FloatSlider(value = 0.30, min = 0.00, max = 1.00, step = 0.01, disabled = False, continuous_update = False, readout = True, readout_format = '0.2f')
Kq_slider = widgets.FloatSlider(value = 0.33, min = 0.15, max = 1.00, step = 0.01, disabled = False, continuous_update = False, readout = True, readout_format = '0.2f')
Ks_slider = widgets.FloatSlider(value = 0.07, min = 0.00, max = 0.15, step = 0.01, disabled = False, continuous_update = False, readout = True, readout_format = '0.2f')
N_slider = widgets.IntSlider(value = 3, min = 2, max = 7, disabled = False, continuous_update = False, readout = True)
# Place all sliders in a list
list_of_sliders = [Kq_slider, Ks_slider, Cmax_slider, B_slider, Alpha_slider, N_slider]
Dropdown
The Dropdown() allows the user to select from a set of discrete variable options. Here, I want to give the user options on which error metric to use when comparing simulated and observed timeseries.
I provide three options:
- RMSE: Root mean square error
- NSE: Nash Sutcliffe efficiency
- ROCE: Runoff coefficient error
See the calculate_error_by_type inside the HYMOD_components.py script to see how these are calculated.
To provide this functionality, I define the Dropdown() object, as below, with a list of options and the initial value:
# Construct the drop-down to select from different error metrics
drop_down = widgets.Dropdown(options=['RMSE','NSE','ROCE'], description='',
value = 'RMSE', disabled = False)
# Display the drop-down
display(drop_down)
ToggleButton
The ToggleButton() allows for a bool variable to be toggled between True and False. For my streamflow plot function, I have an option plot_observed = False which determines if the observed streamflow timeseries is shown in the figure.
# Construct the button to toggle observed data On/Off
plot_button = widgets.ToggleButton(value = False, description = 'Toggle', disabled=False, button_style='', tooltip='Description')
# Display the button
display(plot_button)
Labels
As mentioned above, I choose to not include the description argument within the slider, drop-down, or toggle objects. This is because it is common for these labels to get cut-off when displaying the widget object.
For example, take a look at this slider below, with a long description argument:
# Make a slider with a long label
long_title_slider = widgets.FloatSlider(value = 2.0, min = 0.0, max = 7.0, step = 0.1, description = 'This slider has a long label!', readout = True)
# Display: Notice how the label is cut-off!
display(long_title_slider)
The ipywidgets.Label() function provides a way of avoiding this while allowing for long descriptions. Using Label() will ultimately provide you with a lot more control over your widget layout (last section of the tutorial).
The Label() function generates a separate object. Below, I create a unique Label() object for each HYMOD parameter.
# Import the Label() function
from ipywidgets import Label
# Make a list of label strings
param_labs = ['Kq : Quick flow reservoir rate constant (1/day)',
'Ks : Slow flow reservoir rate constant (1/day)',
'C_max : Maximum soil moisture storage (mm)',
'B : Distribution of soil stores',
'Alpha : Division between quick/slow routing',
'N : Number of quick-flow reservoirs']
# Make a list of Label() objects
list_of_labels = [Label(i) for i in param_labs]
# Display the first label, for example.
list_of_labels[0]
Interactive_output
Now that we have constructed interactive
The interactive_output function takes two inputs, the function to interact with, and a dictionary of variable assignments:
interactive_output( function, {‘variable_name’ : variable_widget, …} )
I have created a custome function plot_HYMOD_results which:
- Loads 1-year of precipitation and evaporation data for the Leaf River catchment.
- Runs the HYMOD simulation using the provided parameter values.
- Calculates the error of the simulated vs. observed data.
- Plots the timeseries of runoff.
The source code for this function can be found in the GitHub repository for this post, or specifically here.
The function receives parameter values for each of the HYMOD parameters discussed above, a bool indicator if observed data should be plotted, and a specified error metric.
plot_HYMOD_results(C_max, B, Alpha, Ks, Kq, N_reservoirs, plot_observed = False, error_type = ‘RMSE’):
I have already generated widget components corresponding to each of these variables! (If you are on the Jupyter Notebook version of this post, make sure to have Run every cell before this, or else the following code wont work.
I can now use the interactive_output function to link the widget components generated earlier with the function inputs:
# Import the interactive_output function
from ipywidgets import interactive_output
# Import my custom plotting function
from HYMOD_plots import plot_HYMOD_results
result_comparison_plot = interactive_output(plot_HYMOD_results, {'C_max' : Cmax_slider, 'B': B_slider, 'Alpha':Alpha_slider,
'Ks':Ks_slider, 'Kq':Kq_slider,'N_reservoirs':N_slider,
'plot_observed' : plot_button,'error_type': drop_down})
# Show the output
result_comparison_plot

Displaying the interactive_output reveals only the plot, but does not include any of the widget functionality…
Despite this, the plot is still linked to the widget components generated earlier. If you don’t believe me (and are reading the Jupyter Notebook version of this post), scroll up and click the ToggleButton a few cells up, then come back and look at the plot again.
Using the interactive_output() function, rather than other variations of the interact() functions available, allows for cleaner widgets to be produced, because now the arrangment of the widget components can be entirely customizable.
Keep reading for more detail on this!
Arranging widget components
Rather than using widget features one-at-a-time, Ipywidgets allow for several widgets to be arranged in a unified layout. Think of everything that has been generated previously as being a cell within the a gridded widget; the best part is that each cell is linked with one another.
Once the individual widget features (e.g., sliders, buttons, drop-downs, and output plots) are defined, they can be grouped using the VBox() (vertical box) and HBox() (horizontal box) functions.
I’ve constructed a visual representation of my intended widget layout, shown below. The dashed orange boxes show those components grouped by the HBox() function, and the blue boxes show those grouped by the VBox() function.

Before getting started, import some of the basic layout functions:
# Import the various
from ipywidgets import HBox, VBox, Layout
Before constructing the entire widget, it is good to get familiar with the basic HBox() and VBox() functionality.
Remember the list of sliders and list of labels that we created earlier?
# Stack the list of label objects vertically:
VBox(list_of_labels)
# Try the same thing with the sliders (remove comment #):
#VBox(list_of_sliders)
In the final widget, I want the column of labels to be located on the left of the column of sliders. HBox() allows for these two columns to be arrange next to one another:
# Putting the columns side-by-side
HBox([VBox(list_of_labels), VBox(list_of_sliders)])

Generating the final widget
Using the basic HBox() and VBox() functions shown above, I arrange all of the widget components I’ve defined previously. I first define each row of the widget using HBox(), and finally stack the rows using VBox().
The script below will complete the arrangement, and call the final widget!
# Define secifications for the widgets: center and wrap
box_layout = widgets.Layout(display='flex', flex_flow = 'row', align_items ='center', justify_content = 'center')
# Create the rows of the widets
title_row = Label('Select parameter values for the HYMOD model:')
slider_row = HBox([VBox(list_of_labels), VBox(list_of_sliders)], layout = box_layout)
error_menu_row = HBox([Label('Choose error metric:'), drop_down], layout = box_layout)
observed_toggle_row = HBox([Label('Click to show observed flow'), plot_button], layout = box_layout)
plot_row = HBox([result_comparison_plot], layout = box_layout)
# Combine label and slider box (row_one) with plot for the final widget
HYMOD_widget = VBox([title_row, slider_row, plot_row, error_menu_row, observed_toggle_row])
# Call the widget and have fun!
HYMOD_widget
Concluding remarks
If you’ve made it this far, thank you for reading!
I hope that you are able to find some fun/interesting/educational use for the Ipywidget skills learned in this post.




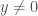 , and
, and  ).
). 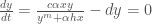
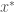 ) which satisfies this equation. Re-arrangement of the above equation yields:
) which satisfies this equation. Re-arrangement of the above equation yields: 

 yields the predator zero-isocline:
yields the predator zero-isocline: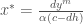
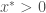 . From the zero-isocline stability equation above, it is clear that this is only true if:
. From the zero-isocline stability equation above, it is clear that this is only true if: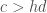
 ) must be greater than the death rate (
) must be greater than the death rate (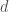 ) scaled by the time it needs to consume prey (
) scaled by the time it needs to consume prey (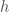 ).
). 

 , predator interference,
, predator interference,  , and the carrying capacity,
, and the carrying capacity,  ), unique species characteristics (e.g., the prey growth rate,
), unique species characteristics (e.g., the prey growth rate,  , and predation efficiency parameters
, and predation efficiency parameters 




















