
The goal of this post is to introduce one of the most important topics in Machine Learning, termed the Bias-Variance Tradeoff. In the last two posts of this series, David Gold introduced two popular classification algorithms. This post will discuss how to assess your classifier’s error and improve it.
Decomposition of Error
Let’s assume that we have a dataset, D={(x1,y1)…(xn,yn)}, where xi is a data point and yi is the label associated with that point. We train a classifier, hd , on this dataset and use it to predict the label y associated with a test point x. The classifier outputs a predicted label hd(x). The classifier’s expected test error is defined as the squared difference between the prediction and the actual label y. This error can be decomposed into three different types of error shown in the following equation:

Variance: hd is the classifier that you have trained on dataset D. If you were to build a classifier on a different dataset, you would get a different classifier that could potentially give you different labels. This is unfortunate because multiple large datasets are usually hard to come by. If we had infinite datasets, we could hypothetically find the ideal expected classifier denoted as hbar(x). Therefore, the expected error due to variance is defined as the difference between our classifier and the ideal expected classifier.
Bias: Suppose that you are able to train your model on infinite datasets and are able to achieve the expected classifier hbar(x), but you still have a high test error. Then, your classifier may have error due to bias, which is a measure of how much the expected classifier’s prediction differs from the average label ybar(x). Error due to bias is a limitation of your model. For example, if you are trying to use a linear classifier to separate data which are not linearly separable, then you will never get good results, even with infinite datasets.
Noise: The goal of a classifier is to determine the average label ybar(x) associated with a data point. However, sometimes the actual label associated with the data point differs from the average label. This is termed error due to noise and is intrinsic to your data.
Improving Classification Error
The first step to improving error is to first identify what type of error that your classifier is suffering from. Figure 1 can help you to diagnose this.

Figure 1: Training and test error due to number of training instances
High Variance: If you classify your test set and find that there is a large gap between the test error and training error, then your classifier might have high variance. Another characteristic of this region is that the training error is below the acceptable test error ε, which is ideal, but the test error is still much higher than ε, which is not ideal.
Solutions
- Add more data: As seen from the graph, as more data (training instances) are added, the test error will go down initially. Conversely, the training error will increase, because adding more training data will always make a classification problem more difficult. The ultimate goal is that the two errors lines will converge and level off below the dashed line.
- Reduce Model Complexity: If your model has high variance, then it can be a sign that your classifier is too complex. It is overfit to the training set and therefore won’t generalize well across test sets. One way to fix this is to reduce model complexity by increasing regularization to penalize more complex solutions.
- Bagging: Short for Bootstrapping Aggregation, bagging is a procedure where multiple datasets can be produced by sampling dataset D with replacement. A classifier is trained on each dataset and then averaged to try to obtain the expected classifier. The variance error can be provably reduced using this method. The details to this proof will be explained in the next blog post.
High Bias: If you classify your test set and find that there is a small gap between the test error and training error, but that both error lines have converged above the acceptable error then your classifier might have high bias.
Solutions
A common misconception is that adding more data is the solution to most error woes. However, it’s very important to realize that if your classifier suffers from bias, there exists a fundamental problem with your model. More data will not fix this issue, and in fact will just increase training error.
- Increase Model Complexity: High bias means that your classifier isn’t robust enough to accurately predict labels, so you need to increase the power of the algorithm. If your data require a more complex classification boundary, consider using algorithms that can find a non-linear boundary such as KNN or Logistic Regression. Non-linearities can be incorporated into linear classifiers through kernelization which involves mapping feature vectors into higher dimensional spaces where you can more likely find a linearly separating hyperplane.
- Add Features: Instead of increasing the complexity of the algorithm, an alternative is to add more features to represent each data point. This might increase the separation between classes enough such that simpler algorithms can still be utilized.
- Boosting: In boosting, weak classifiers with high bias (termed as such because they perform only slightly better than random guessing at predicting labels) are ensembled together to generate a strong learner that has a lower bias.
High Noise: If training error and test error are both too high, and perhaps become even higher after more training instances are introduced, then your data may just be very noisy. This can be due to identical training points having different labels. There are very few ways to actually overcome this type of error, but the best way is to try to add more features to characterize your training data that will hopefully offer more separation between seemingly identical points.
This blog post should give you a taste of the different types of error that are prevalent among classifiers and the next few blog posts in the series will go through bagging, boosting, and kernels as some options to help reduce these errors.
References:
All of the material for the post comes from Kilian Weinberger’s CS4780 class notes and lectures found at: http://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote12.html




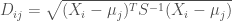 where
where 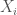 is the vector of attributes for observation
is the vector of attributes for observation  ,
,  is the vector of means for group
is the vector of means for group  , and
, and  is the covariance matrix for the variables. When using the Mahalanobis Distance, points that are equidistant from a group mean are on tilted eclipses:
is the covariance matrix for the variables. When using the Mahalanobis Distance, points that are equidistant from a group mean are on tilted eclipses:

