
In contrast to my theoretically oriented previous post on ensemble forecasting, I will attempt, in this post, to provide some practically oriented operational context for ensemble forecasting from the perspective of water management. This and the previous post will serve as a useful background for the planned third post in this series that will focus on the details of ensemble forecast verification. This post is largely a distillation of my experience in working with the formal Forecast Informed Reservoir Operations (FIRO) efforts that are ongoing, primarily in the western US. I use the term ‘formal’ here deliberately to differentiate from the more general notion of FIRO, which has been in the research literature since at least the 90’s. Importantly, ‘formal’ FIRO, as I choose to label it, is an effort to formalize the use of forecast information into the operations of our nation’s portfolio of federally owned or controlled dams, which contain the largest and most important reservoirs in CONUS. This is in stark contrast to the largely informal use of FIRO that has been applied somewhat ‘under the radar’ and scattershot in various ways and for various purposes by dam operators up to this point. While there is a very interesting discussion to be had about the institutional and operational complexities of this effort (perhaps a future post), I’ll leave this brief once-over-the-FIRO-world contextualization at that for now.
For the purposes of this post, I mention the operational context to narrow the window of forecast applications to a tractable space that is a) pertinent to water systems operations and b) is a space that I am intimately familiar with. The world of hydrometeorological forecasting is large and growing, containing both advances in legacy dynamical forecasting techniques as well as emergent machine learning approaches. When it comes to federal agencies, tried/tested/verified is incredibly important, so I anticipate the uptake of the latter ML approaches to be some ways off. Baby steps…the US Army Corp of Engineers (USACE) is still trying to move past the ‘water on the ground’ legacy of water management.
Meteorological forecasting
In discussing the current state of ensemble forecasting, I will progress hierarchically from the meteorological to the hydrologic forecasting space. I will first discuss some aspects of dynamical meteorological forecasting that form the backbone of any hydrological forecasting effort. It is, after all, the weather gods casting their hydrometeors (rain/snow/ice) upon the earth that cause the majority of the hydrologic responses of interest to practical FIRO applications. This is an important point that I’ll note here and come back to later. Meteorological forcings dominate the hydrologic response and by consequence, dominate the hydrologic uncertainties when we start thinking in terms of future predictions (forecasts) where meteorologic uncertainties become large. This is wholly in contrast to efforts to understand hydrologic uncertainty with observational data as forcings (for instance, stochastic watershed modeling, see my post here), where the hydrologic model’s structural inadequacy is the primary driver of hydrologic predictive uncertainty. The observational (input) uncertainties are not inconsequential in these sorts of applications, but they form a less substantial portion of the overall uncertainty and can largely be considered aleatory.
Advances in meteorological forecasting skill
With some sense of the importance of meteorological uncertainty to the hydrologic forecasting problem, I want to turn now to a brief discussion on the advances in dynamical meteorological forecasting and areas for future research and improvement. Most folks have some practical sense of forecast skill (or lack thereof) from their daily lives; you check the smartphone weather before you head out for the day, put on shorts and a t-shirt, then get soaked walking to work due to some unforecast rain event. Despite events like this and the general challenge of dynamical uncertainty in the atmospheric system (see previous post), the reality is that forecast skill has steadily improved over time, to the tune of 1-day of ‘useful’ skill improvement per decade (see Figure 1). Although dependent on the particular skill metric being used, it is common to assess ‘useful’ skill above 60% skill and a ‘high degree of accuracy’ above 80% skill. By some visual extrapolation, one might surmise that we should be approaching ‘useful’ skill out to 10-days by now in the northern hemisphere (NH) for the atmospheric variable in question.

Figure 1. Improvements in forecast skill of 500 hPa geopotential height anomaly over time (Bauer et al., 2015)
Notably, Figure 1 shows the skill improvements for a large, synoptic scale variable at a moderate altitude in the atmosphere (500 hPa ~ 15,000’ above sea level). Skill varies greatly across atmospheric variables and is particularly challenging for variables that are highly dependent on sub-grid scale processes (i.e. processes that occur below the native resolution of the forecast model); one of these, as luck would have it, is the aforementioned hydrometeor (precipitation) generating process of such interest to hydrologic applications. As I will loosely paraphrase, something I heard from F. Martin Ralph, the current director of the Center for Western Weather and Water extremes (CW3E) at Scripps, is that ‘our skill in predicting upper atmospheric variables at large scales has increased enormously, whereas our skill in predicting local scale precipitation has barely budged’. This basic notion is a Pandora’s box of sorts in terms of thinking how we might use the information that is available in forecast models (i.e. the highly accurate synoptic scale variables) differently to more directly forecast key variables of interests at the local scale; many of these emerging techniques rely on ML techniques applied across wide spatial scales that can more precisely target key hydrometeorological attributes of interest to water management like the probability of exceeding some rainfall threshold (Zhang et al., 2022) or mapping directly to streamflow itself and skipping the whole precipitation part (Nearing et al., 2021). These are certainly highly promising avenues for research, but we’ll return to some practical advancements in dynamical forecasting for now.
Areas for improving meteorological forecasting
One could spend an entire blog post (or many posts really) on this subject. I want to touch on just a few key areas where much research effort is currently dedicated to advancing meteorological forecasting. The first of these is improving the spatiotemporal resolution of the forecast models. To take a quick step back, it is useful to compare a ‘forecast’ model to a Global Circulation/Climate Model (GCM) or Earth System Model (ESM). In a broad sense, these models are all constructed in the same basic way. They start with a dynamical representation of the atmosphere based on the Navier-Stokes fluid dynamics equations that are discretized and solved across ‘grids’ of some horizontal and vertical dimensions across the globe. In climate science speak, this part of the model is often referred to as the ‘dynamical core’ (or ‘dy-core’ if you want to sound cool). For the most part, things that happen below this native grid resolution are parameterized (e.g. cloud formation), which means that they are modeled based on fitted statistical relationships between grid scale atmospheric states and sub-grid scale process outcomes. These parameterizations are often referred to as the model’s ‘physics’. Intuitively, the smaller the scale we can represent the atmospheric processes, then the better we might be able to capture these local behaviors. Advances in computational power have enable much higher resolutions for forecast models/GCM/ESM over time and will likely continue to do so.
Where these models primarily differ is in all the other stuff needed to run a simulation of earth’s atmosphere, namely the land/ocean/ice surfaces and their couplings with the atmosphere. Forecast models must be computationally tractable at operational relevant timescales to be useful. In the space we are discussing, this means that the model must be able to reinitialize and produce a forecast at least daily. Moreover, the forecast temporal resolution must be much higher to capture evolution of the climate system at operationally relevant scales, typically 6-hourly with current technology. To overcome this complexity tradeoff (see Figure 2), forecast models have traditionally relied on extremely simplified representations of the land/ocean/ice surface boundary conditions that are assumed to be constant across the forecast period. Conversely, the development of GCM/ESMs has continually increased the complexity of the land/ocean/ice modeling and their atmospheric coupling while retaining sufficient atmospheric spatiotemporal resolution for long term simulations. GCM/ESM must also provide provable closure of things like energy and carbon fluxes across long time scales; this is not really a primary concern for forecast models, they can be ‘leaky’. Increasingly, however, computational advances have enabled forecast models to look more like GCM/ESM, with state-of-the-science forecast models now modeling and coupling land/ocean interactions along with the atmospheric evolution.

Figure 2. Tradeoff between model complexity and resolution in modeling the earth system (Bauer et al., 2015)
The second key area that I’ll highlight is data assimilation. Data assimilation is the process of constraining forecast trajectories based on some intermediate assessment of the actual evolution of the climate system (i.e. an observation). In meteorological forecasting, this is typically done in a relatively short window after the forecast has been generated, for instance the 12-hour assimilation window in Figure 3 below. Importantly, for the issuance of forecasts, this assimilation period is happening ‘under the hood’, so that the user of forecasts would only see the forecast as being issued at 21:00, not the 09:00 time when the actual forecast model was initialized. While the details of data assimilation are complex and well outside the scope of this post, it is an incredibly important area of continued research for dynamical forecasting. To put this into context, another loose paraphrase I heard from Vijay Tallapragada, senior scientist for NOAA’s Environmental Modeling Center, is ‘if you want long-term job security in the weather forecasting, get into data assimilation’.

Figure 3. Data assimilation example in ensemble forecasting (Bauer et al., 2015)
Lastly, as alluded to in my previous post, the methods to sample initial condition uncertainty and propagate it through the dynamical forecast model are also a very important area of advancement in meteorological ensemble forecasting. The mathematical challenge of adequately sampling initial condition uncertainty at global scales across highly correlated initialization variables is huge, as is the computational burden of running multiple perturbed members of the forecasts to produce an ensemble. The latter challenge has particular significance to the hydrological forecasting enterprise and may, at least partially, explain certain design choices in the hydrologic forecast systems discussed in the following section.
Hydrologic ensemble forecasting
To turn the meteorologic outputs of precipitation and temperature to streamflow, we need a streamflow generating process model. Moreover, if we want an ensemble of streamflow predictions, we need a way to generate some uncertainty in the streamflows to reflect the dominant meteorological uncertainties in the forecasts. With this modeling chain of meteorologic forecast model à streamflow process model, one could envision many possible ways to attempt to capture this uncertainty. Perhaps the most intuitive would be to take each ensemble output from the meteorologic forecast model and run it through the streamflow process model; voila! ensemble streamflow forecasts!
The Hydrologic Ensemble Forecast Service (HEFS)
This is, however, not how it’s done in the Hydrologic Ensemble Forecast Service (HEFS) that is the current operational model used by NOAA/NWS river forecast centers (RFC) and the model being primarily used for formal FIRO efforts (see Figure 4 below). Instead, HEFS has its own internal Meteorological Ensemble Forecast Processor (MEFP) that ingests an ensemble mean of temperature and precipitation inputs from the meteorological ensemble forecast (global ensemble forecast system, GEFS) and then creates its own internal ensemble of meteorologic forecasts. These internally generated traces of forecasted temperature/precipitation are each used to force a single, watershed calibrated version of the SAC-SMA hydrologic model to produce an ensemble of streamflow forecasts (Demargne et al., 2014). Why use this implementation instead of the seemingly more straightforward approach with the meteorological ensemble? I don’t have a definitive answer for that, but my understanding is that, from a statistical verification perspective, the current HEFS approach is more reliable.

Figure 4. Conceptual diagram of HEFS model (Demargne et al., 2014)
Another possible reason stems from the computational complexity challenge of meteorological ensemble forecasting mentioned in the previous section, particularly as it relates to hindcasting. Hindcasts are forecasts that are generated with a modern day forecast model (and their modern day skill) against historical observations of the appropriate quality (post satellite era generally speaking, ~1979 – present). In meteorological spheres, hindcasts are important in documenting the performance of forecast model across a much larger dataset. For the purposes of advancing operational water management with forecasts, hindcasts are more than important…they are indispensable. Hindcasts form the basis for the design and testing of forecast informed water management procedures; there is no workaround for this. To generate a meteorological hindcast, the NWS has to carve out time to dedicate its warehouse sized forecast model computational platform to generating 20 -30 years of forecasts and archiving the data. This time must be balanced with the operational necessity of producing real time forecasts for things like: not getting wet going to work or maybe, I don’t know, aviation? This challenge means that hindcasts must typically be produced at reduced resolution compared to the operational forecasts. For example, the current NOAA Global Ensemble Forecast System (GEFSv12) produces operational forecasts with 31 ensemble members, but only 5 ensemble members in the hindcasts (Guan et al., 2019).This limitation is significant. 5 ensemble members is sufficient to produce a relatively good approximation of the ensemble-mean, but grossly undersized for producing an adequate probabilistic streamflow ensemble. In this hindcast context, then, the construction of HEFS makes sense and enables more flexibility for generating historical forecast ensembles for development of forecast informed water management policies.
Practical HEFS limitations
The current implementations of HEFS typically generate ~40 ensemble members. The MEFP is conditioned on a historical period of reference using a Schaake shuffle type procedure, so this ensemble size is actually the length (in years) of that historical conditioning period. As with meteorological forecasting, the production of HEFS hindcasts is also challenging, in that it requires the same carving out of time on an operational computational architecture to produce the hindcasts. This limitation substantiates one of the core interests from folks within the formal FIRO implementation efforts into synthetic forecasting methods to expand the length and availability of simulated hindcasts for operational policy development. In general, HEFS is reliable, but it suffers from systemic ‘Type-II conditional bias’, which in layman’s terms is the tendency to underpredict extreme events. I will dig into some of these attributes of HEFS forecasts in a future post on ensemble verification.
Outside of questions of statistical reliability, there are other more challenging to quantify concerns about the implementation of HEFS. The ensemble-mean forecasts from the NOAA GEFS model that force HEFS are bound to be more ‘skillful’ than, for instance, the ensemble control forecast. (Note: the control forecast is the forecast trajectory initialized from the ‘best guess’ at the initial condition state of the atmosphere). This is a well-documented property of ensemble-mean predictions. However, ensemble-mean forecasts are not dynamically consistent representations of the atmosphere (Wilks, 2019). As I noted in my previous post, an ideal forecast ensemble would include all possible trajectories of the forecasts, which might diverge substantially at some future time. Where forecast trajectories have diverged, an average of those trajectories will produce a value that is not in the space of plausible dynamic trajectories. In practical terms, this leads to ensemble-mean forecasts collapsing to climatology at longer leads and systematic reductions in the range of magnitudes of key variables as lead time increases. In short, this reliance on the meteorological ensemble-mean forecast does incur some risk (in my opinion) of missing high impact extremes due to, for example, even relatively small spatial errors in the landfall locations of atmospheric river storms.
Final thoughts
The intent of this post was to provide some current operational context for the types of forecasts being considered for formal implementation of forecast informed water management operations. The ensemble forecasting space is large and exciting from both research and operational perspectives, but it’s challenging to navigate and understand what is actually being considered for use, and what is simply novel and interesting. In my next post, I’ll discuss some of the primary verification techniques used for ensemble forecasts with a focus on the performance of HEFS in an example watershed and some associated practical implementation.
Reference
Bauer, P., Thorpe, A., & Brunet, G. (2015). The quiet revolution of numerical weather prediction. Nature, 525(7567), 47–55. https://doi.org/10.1038/nature14956
Demargne, J., Wu, L., Regonda, S. K., Brown, J. D., Lee, H., He, M., … Zhu, Y. (2014). The science of NOAA’s operational hydrologic ensemble forecast service. Bulletin of the American Meteorological Society, 95(1), 79–98. https://doi.org/10.1175/BAMS-D-12-00081.1
Guan, H., Zhu, Y., Sinsky, E., Fu, B., Zhou, X., Li, W., et al. (2019). The NCEP GEFS-v12 Reforecasts to Support Subseasonal and Hydrometeorological Applications. 44th NOAA Annual Climate Diagnostics and Prediction Workshop, (October), 78–81.
Nearing, G. S., Kratzert, F., Sampson, A. K., Pelissier, C. S., Klotz, D., Frame, J. M., … Gupta, H. V. (2021). What Role Does Hydrological Science Play in the Age of Machine Learning? Water Resources Research, 57(3). https://doi.org/10.1029/2020WR028091
Wilks, D. S., (2019). Statistical Methods in the Atmospheric Sciences, 4th ed. Cambridge, MA: Elsevier.
Zhang, C., Brodeur, Z. P., Steinschneider, S., & Herman, J. D. (2022). Leveraging Spatial Patterns in Precipitation Forecasts Using Deep Learning to Support Regional Water Management. Water Resources Research, 58(9), 1–18. https://doi.org/10.1029/2021WR031910



























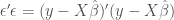



 , is the orthogonal distance between y and
, is the orthogonal distance between y and 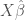 . (Image source: Wikipedia commons)
. (Image source: Wikipedia commons) terms should be independent of the value of the explanatory variables, X. Put in equation form, this assumption requires:
terms should be independent of the value of the explanatory variables, X. Put in equation form, this assumption requires:


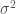 is a constant value.
is a constant value.
 as:
as:
