This post was inspired by the Sankey diagram in Figure 1 of this pre-print led by Dave Gold: “Exploring the Spatially Compounding Multi-sectoral Drought Vulnerabilities in Colorado’s West Slope River Basins” (Gold, Reed & Gupta, In Review) which features a Sankey diagram of flow contributions to Lake Powell. I like the figure, and thought I’d make an effort to produce similar diagrams using USGS gauge data.
To explain the “(?)” in my title: When I started this, I’d realized quickly that I to choose one of two popular plotting packages: matplotlib or plotly.
I am a frequent matplotlib user and definitely appreciate the level of control in the figure generation process. However, it can sometimes be more time- and line-intensive designing highly customized figures using matplotlib. On the other hand, in my experience, plotly tools can often produce appealing graphics with less code. I am also drawn to the fact that the plotly graphics are interactive objects rather than static figures.
I decided to go with plotly to try something new. If you want to hear my complaints and thoughts on use context, you can skip to the conclusions below.
In the sections below, I provide some code which will:
Define a network of USGS gauge stations to include in the plot
Retrieve data from USGS gauge stations
Create a Sankey diagram using plotly showing streamflows across the network
Here, I focus on the Rio Grande river upstream of Albuquerque, NM. However you can plot a different streamflow network by modifying the dictionary of upstream nodes defining the network.
Plotting a Sankey streamflow network with plotly
The code used here requires both plotly and the pygeohydro package (for USGS data retrieval).
from pygeohydro import NWIS
import plotly.graph_objects as go
With that out of the way, we can get started.
Defining the flow network & data retrieval
I start by defining a dictionary called upstream_stations which defines the relationships between different gauges of interest.
This dictionary contains pairs of the form:
{"GAUGE_ID" : ["LIST_OF", "UPSTREAM", "GAUGE_IDs"]}
If there is no upstream site, then include an empty list. For the Rio Grande network, this looks like:
# define relationships between each gauge and upstream sites
upstream_stations = {
'08329918' : ['08319000', '08328950'],
'08319000' : ['08317400', '08317200'],
'08328950' : [],
'08317200' : [],
'08317400' : ['08313000'],
'08313000' : ['08290000', '08279500'],
'08287000' : [],
'08279500' : [],
'08290000' : ['08287000', '08289000'],
'08289000' : [],
}
# Get list of all stations from upstream_stations
all_stations = list(upstream_stations.keys())
for station, upstream in upstream_stations.items():
all_stations += upstream
all_stations = list(set(all_stations))
Using the list of all_stations, I use the following code to pull daily streamflow data for each site from 2015-2020 (or some other specified dates):
def get_usgs_gauge_data(stations, dates):
"""
Get streamflow data from USGS gauge stations using NWIS.
"""
nwis = NWIS()
df = nwis.get_streamflow(stations, dates, mmd=False)
# get rid of USGS- in columns
df.columns = df.columns.str.replace('USGS-', '')
return df
# Get USGS flows
flows = get_usgs_gauge_data(all_stations, ('2015-01-01', '2020-12-31'))
For the Sankey diagram, we need a single flow value for each station. In this case I calculate an average of the annual total flows at each station:
# Get annual mean flows
agg_flows = flows.resample('Y').sum().agg('mean')
Creating the Sankey figure
At it’s core, a Sankey diagram is a visualization of a weighted network (also referred to as a graph) defined by:
Nodes
Links (aka Edges)
Weights
In our case, the nodes are the USGS gauge stations, the links are the connections between upstream and downstream gauges, and the weights are the average volumes of water flowing from one gauge to the next.
Each link is defined by a source and target node and a value. This is where the upstream_stations dictionary comes in. In the code block below, I set up the nodes and links, looping through upstream_stations to define all of the source-target relationships:
## Deinfe nodes and links
# Nodes are station IDs
nodes = all_stations
node_indices = {node: i for i, node in enumerate(nodes)}
# make links based on upstream-downstream relationships
links = {
'source': [],
'target': [],
'value': [],
}
# loop through upstream_stations dict
for station, upstream_list in upstream_stations.items():
for stn in upstream_list:
if stn in agg_flows and station in agg_flows:
links['source'].append(node_indices[stn])
links['target'].append(node_indices[station])
links['value'].append(agg_flows[stn])
Lastly, I define some node labels and assign colors to each node. In this case, I want to make the nodes black if they represent reservoir releases (gauges at reservoir outlets) or blue if they are simple gauge stations.
labels = {
'08329918' : 'Rio Grande at Alameda',
'08319000' : 'San Felipe Gauge',
'08328950' : 'Jemez Canyon Reservoir',
'08317200' : 'Santa Fe River',
'08317400' : 'Cochiti Reservoir',
'08313000' : 'Rio Grande at Otowi Bridge',
'08287000' : 'Abiquiu Reservoir',
'08279500' : 'Rio Grande',
'08290000' : 'Rio Chama',
'08289000' : 'Rio Ojo Caliente',
}
# Create nodes labels and colors lists
node_labels = [labels[node] for node in nodes]
node_colors = ['black' if 'Reservoir' in label else 'dodgerblue' for label in node_labels]
Finally, the function to generate the figure:
def create_sankey_diagram(node_labels, links, node_colors,
orientation='h',
size=(2000, 700)):
"""
Create a Sankey diagram of using Plotly.
Parameters
----------
node_labels : list
List of node labels.
links : dict
Dictionary with keys 'source', 'target', and 'value'.
node_colors : list
List of node colors.
orientation : str
Orientation of the diagram, 'h' for horizontal and 'v' for vertical.
Returns
-------
sankey_fig : plotly.graph_objects.Figure
Plotly figure object.
"""
sankey_fig = go.Figure(go.Sankey(
orientation=orientation,
node=dict(
pad=70,
thickness=45,
line=dict(color='dodgerblue', width=0.5),
label=node_labels,
color=node_colors
),
link=dict(
source=links['source'],
target=links['target'],
value=links['value'],
color='cornflowerblue'
)
))
sankey_fig.update_layout(
title_text="Rio Grande Streamflow ",
font=dict(size=23),
width=size[0],
height=size[1]
)
return sankey_fig
There are some options for manipulating this figure script to better suit your needs. Specifically you may want to modify:
pad=70 : this is the horizontal spacing between nodes
thickness=45 : this is the thickness of the node elements
With our pre-prepped data from above, we can use the function like so:
I’d say it looks… okay. And admittedly this is the appearance after manipulating the node placement using the interactive interface.
It’s a squished vertically (which can be improved by making it a much taller figure). However my biggest issue is with the text being difficult to read.
Changing the orientation to horizontal (orientation='h') results in a slightly better looking figure. Which makes sense, since the Sankey diagram is often shown horizontal. However, this does not preserve the relationship to the actual North-South flow direction in the Rio Grande, so I don’t like it as much.
Conclusions
To answer the question posed by the title, “Sankey diagrams for USGS gauge data in python(?)”:
Yes, sometimes. And sometimes something else.
Plotly complaints:
While working on this post, I developed a few complaints with the plotly Sankey tools. Specifically:
It appears that the label text coloring cannot be modified. I don’t like the white edgecolor/blur effect, but could not get rid of this.
The font is very difficult to read… I had to make the text size very large for it to be reasonably legible.
You can only assign a single node thickness. I had wanted to make the reservoirs thick, and shrink the size of the gauge station nodes. However, it seems this cannot be done.
The diagrams appear low-resolution and I don’t see a way to save a high res version.
Ultimately, the plotly tools are very restrictive in the design of the graphic. However, this is a tradeoff in order to get the benefit of interactive graphics.
Plotly praise:
The plotly Sankey tools have some advantages, specifically:
The plots are interactive
Plots can be saved as HTML and embedded in websites
These advantages make the plotly tools good for anyone who might want to have a dynamic and maybe frequently updated dashboard on a site.
On the other hand, if I wanted to prepare a publication-quality figure, where I had absolute control of the design elements, I’d likely turn to matplotlib. That way it could be saved as an SVG and further manipulated in a vector art program link Inkscape or Illustrator.
Thanks for reading!
References
Chegini, T., Li, H. Y., & Leung, L. R. (2021). HyRiver: Hydroclimate data retriever. Journal of Open Source Software, 6(66), 3175.
Fans of this blog will know that uncertainty is often a focus for our group. When approaching uncertainty, Bayesian methods might be of interest since they explicitly provide uncertainty estimates during the modeling process.
PyMC is the best tool I have come across for Bayesian modeling in Python; this post gives a super brief introduction to this toolkit.
Introduction to PyMC
PyMC, described in their own words: “… is a probabilistic programming library for Python that allows users to build Bayesian models with a simple Python API and fit them using Markov chain Monte Carlo (MCMC) methods.”
In my opinion, the best part of PyMC is the flexibility and breadth of model design features. The space of different model configurations is massive. It allows you to make models ranging from simple linear regressions (shown here), to more complex hierarchical models, copulas, gaussian processes, and more.
Regardless of your model formulation, PyMC let’s you generate posterior estimates of model parameter distributions. These parameter distributions reflect the uncertainty in the model, and can propagate uncertainty into your final predictions.
The posterior estimates of model parameters are generated using Markov chain Monte Carlo (MCMC) methods. A detailed overview of MCMC is outside the scope of this post (maybe in a later post…).
In the simplest terms, MCMC is a method for estimating posterior parameter distributions for a Bayesian model. It generates a sequence of samples from the parameter space (which can be huge and complex), where the probability of each sample is proportional to its likelihood given the observed data. By collecting enough samples, MCMC generates an approximation of the posterior distribution, providing insights into the probable values of the model parameters along with their uncertainties. This is key when the models are very complex and the posterior cannot be directly defined.
When writing drafting this post, I wanted to include a demonstration which is (a) simple enough to cover in a brief post, and (b) relatively easy for others to replicate. I settled on the simple linear regression model described below, since this was able to be done using readily retrievable CAMELS data.
The example attempts to predict mean streamflow as a linear function of basin catchment area (both in log space). As you’ll see, it’s not the worst model, but its far from a good model; there is a lot of uncertainty!
CAMELS Data
For a description of the CAMELS dataset, see Addor, Newman, Mizukami and Clark (2017).
I pulled all of the national CAMELS data using the pygeohydro package from HyRiver which I have previously recommended on this blog. This is a convenient single-line code to get all the data:
import pygeohydro as gh
### Load camels data
camels_basins, camels_qobs = gh.get_camels()
The camels_basins variable is a dataframe with the different catchment attributes, and the camels_qobs is a xarray.Dataset. In this case we will only be using the camels_basins data.
The CAMELS data spans the continental US, but I want to focus on a specific region (since hydrologic patterns will be regional). Before going further, I filter the data to keep only sites in the Northeaster US:
# filter by mean long lat of geometry: NE US
camels_basins['mean_long'] = camels_basins.geometry.centroid.x
camels_basins['mean_lat'] = camels_basins.geometry.centroid.y
camels_basins = camels_basins[(camels_basins['mean_long'] > -80) & (camels_basins['mean_long'] < -70)]
camels_basins = camels_basins[(camels_basins['mean_lat'] > 35) & (camels_basins['mean_lat'] < 45)]
I also convert the mean flow data (q_mean) units from mm/day to cubic meters per day:
# convert q_mean from mm/day to m3/s
camels_basins['q_mean_cms'] = camels_basins['q_mean'] * (1e-3) *(camels_basins['area_gages2']*1000**2) * (1/(60*60*24))
And this is all the data we need for this crude model!
Bayesian linear model
The simple linear regression model (hello my old friend):
Normally you might assume that there is a single, best value corresponding to each of the model parameters (alpha and beta). This is considered a Frequentist perspective and is a common approach. In these cases, the best parameters can be estimated by minimizing the errors corresponding to a particular set of parameters (see least squares, for example.
However, we could take a different approach and assume that the parameters (intercept and slope) are random variables themselves, and have some corresponding distribution. This would constitute a Bayesian perspective.
Keeping with simplicity in this example, I will assume that the intercept and slope each come from a normal distribution with a mean and variance such that:
When it comes time to make inferences or predictions using our model, we can create a large number of predictions by sampling different parameter values from these distributions. Consequently, we will end up with a distribution of uncertain predictions.
NOTE: The MCMC sampler used by PyMC is written in C and will be SIGNIFICANTLY faster if you provide have access to GCC compiler and specify the it’s directory using the the following:
import pymc as pm
import os
os.environ["THEANO_FLAGS"] = "gcc__cxxflags=-C:\mingw-w64\mingw64\bin"
You will get a warning if you don’t have this properly set up.
Now, onto the demo!
I start by retrieving our X and Y data from the CAMELS dataset we created above:
# Pull out X and Y of interest
x_ftr= 'area_gages2'
y_ftr = 'q_mean_cms'
xs = camels_basins[x_ftr]
ys = camels_basins[y_ftr]
# Take log-transform
xs = np.log(xs)
ys = np.log(ys)
At a glance, we see there is a reasonable linear relationship when working in the log space:
Two of the key features when building a model are:
The random variable distribution constructions
The deterministic model formulation
There are lots of different distributions available, and each one simply takes a name and set of parameter values as inputs. For example, the normal distribution defining our intercept parameter is:
The value of the parameter priors that you specify when construction the model may have a big impact depending on the complexity of your model. For simple models you may get away with having uninformative priors (e.g., setting mu=0), however if you have some initial guesses then that can help with getting reliable convergence.
In this case, I used a simple least squares estimate of the linear regression as the parameter priors:
Once we have our random variables defined, then we will need to formulate the deterministic element of our model prediction. This is the functional relationship between the input, parameters, and output. For our linear regression model, this is simply:
y_mu = alpha + beta * xs
In the case of our Bayesian regression, this can be thought of as the mean of the regression outputs. The final estimates are going to be distributed around the y_mu with the uncertainty resulting from the combinations of our different random variables.
Putting it all together now:
### PyMC linear model
with pm.Model() as model:
# Priors
alpha = pm.Normal('alpha', mu=intercept_prior, sigma=10)
beta = pm.Normal('beta', mu=slope_prior, sigma=10)
sigma = pm.HalfNormal('sigma', sigma=1)
# mean/expected value of the model
mu = alpha + beta * xs
# likelihood
y = pm.Normal('y', mu=mu, sigma=sigma, observed=ys)
# sample from the posterior
trace = pm.sample(2000, cores=6)
With our model constructed, we can use the pm.sample() function to begin the MCMC sampling process and estimate the posterior distribution of model parameters. Note that this process can be very computationally intensive for complex models! (Definitely make sure you have the GCC set up correctly if you plan on needing to sample complex models.)
Using the sampled parameter values, we can create posterior estimates of the predictions (log mean flow) using the posterior parameter distributions:
Let’s go ahead and plot the range of the posterior distribution, to visualize the uncertainty in the model estimates:
### Plot the posterior predictive interval
fig, ax = plt.subplots(ncols=2, figsize=(8,4))
# log space
az.plot_hdi(xs, ppc['posterior_predictive']['y'],
color='cornflowerblue', ax=ax[0], hdi_prob=0.9)
ax[0].scatter(xs, ys, alpha=0.6, s=20, color='k')
ax[0].set_xlabel('Log ' + x_ftr)
ax[0].set_ylabel('Log Mean Flow (m3/s)')
# original dim space
az.plot_hdi(np.exp(xs), np.exp(ppc['posterior_predictive']['y']),
color='cornflowerblue', ax=ax[1], hdi_prob=0.9)
ax[1].scatter(np.exp(xs), np.exp(ys), alpha=0.6, s=20, color='k')
ax[1].set_xlabel(x_ftr)
ax[1].set_ylabel('Mean Flow (m3/s)')
plt.suptitle('90% Posterior Prediction Interval', fontsize=14)
plt.show()
And there we have it! The figure on the left shows the data and posterior prediction range in log-space, while the figure on the right is in non-log space.
As mentioned earlier, it’s not the best model (wayyy to much uncertainty in the large-basin mean flow estimates), but at least we have the benefit of knowing the uncertainty distribution since we took the Bayesian approach!
That’s all for now; this post was really meant to bring PyMC to your attention. Maybe you have a use case or will be more likely to consider Bayesian approaches in the future.
If you have other Bayesian/probabilistic programming tools that you like, please do comment below. PyMC is one (good) option, but I’m sure other people have their own favorites for different reasons.
Addor, N., Newman, A. J., Mizukami, N. and Clark, M. P. The CAMELS data set: catchment attributes and meteorology for large-sample studies, Hydrol. Earth Syst. Sci., 21, 5293–5313, doi:10.5194/hess-21-5293-2017, 2017.
This is a guest post by David Lafferty from the University of Illinois Urbana-Champaign. David is a fifth-year PhD student in the Department of Climate, Meteorology & Atmospheric Sciences working with Dr. Ryan Sriver. David’s research contributes to advances in climate change risk assessment. Dr. Casey Burleyson, a research scientist at the Pacific Northwest National Laboratory, also contributed text about the MSD-LIVE platform.
Visualization plays a crucial role in the scientific process. From an initial exploratory data analysis to the careful presentation of hard-earned results, data visualization is a powerful tool to generate hypotheses and insights, communicate findings to both scientists and stakeholders, and aid decision-making. Interactive data visualization can enhance each of these use cases and is particularly useful for facilitating collaborations and deepening user engagement. Effective data visualization has been a recurring theme of the Water Programming blog, with several past posts directly addressing the topic, including some that highlight various tools for interactive visualization [1, 2].
In this post, I’d like to highlight Panel, a data exploration and web app framework in Python. I’ll also showcase how we used Panel to construct an interactive dashboard to accompany a recent paper, allowing readers to explore our results in more detail.
An overview of the HoloViz ecosystem, taken from the hvPlot website. Panel provides a high-level interface that allows users to build linked apps across all of these visualization libraries.
Panel is an open-source Python library that allows developers to create interactive web apps and dashboards in Python. It is part of the HoloViz ecosystem, which includes other visualization packages like HoloViews and GeoViews. Panel provides a high-level API for creating rich, interactive visualizations and user interfaces directly from Python code. The library includes an impressive number of features, such as different types of panes for displaying and arranging plots, media, text, or other external objects; a wide range of widgets; and flexible, customizable dashboard layouts. Panel itself does not provide visualization tools but instead relies on (and is designed to work well with) other popular plotting libraries such as Bokeh, Datashader, Folium, Plotly, and Matplotlib. Panel provides several deployment options for your polished apps and dashboards, but also works well within development environments such as Jupyter Notebooks, VS Code, PyCharm, or Spyder.
A simple Panel dashboard
To get a sense of Panel’s capabilities, let’s build a simple dashboard that analyzes global temperature anomalies from different observational datasets. Global mean temperature rise above pre-industrial levels is one of most widely-used indicators of climate change, and 2023 was a record year in this respect – all major monitoring agencies recorded 2023 as the warmest year on record [3] and the exceptional warmth of 2023 fell outside the prediction intervals of many forecasting groups [4].
To visualize this temperature change, we’re going to look at four observational datasets: Berkeley Earth, HadCRUT5, NOAA, and GISTEMPv4. First, we need to import the required Python libraries:
!pip install hvplot
from functools import reduce
import pandas as pd
import hvplot.pandas
import panel as pn
pn.extension(comms='colab')
This notebook is available on Google Colab, which is why I’ve set comms=‘colab' in the Panel configuration settings. Next, we download and merge all observational datasets:
As you can see, each of these datasets measures the global mean temperature anomaly relative to a fixed baseline, and the baselines are not constant across datasets. Climate scientists often define 1850-1900 as the canonical pre-industrial baseline, but choosing this period is a non-trivial exercise [5] and can impact the uncertainty around our estimates of climate change. Let’s explore this phenomenon interactively using Panel and the datasets downloaded above:
def adjust_baseline(obs_name, new_baseline):
# Adjusts given observational dataset to selected new baseline
def plot_timeseries(obs_to_include, new_baseline_start, new_baseline_end):
# Plots timeseries of anomalies for selected datasets and new baseline
def get_2023_anomaly(obs_to_include, new_baseline_start, new_baseline_end):
# Calculates and shows 2023 anomaly for selected datasets and new baseline
The full code for each of these functions is available in the notebook. Briefly, adjust_baseline calculates a new timeseries of global temperature anomalies for a given observational dataset, now relative to a new user-defined baseline. plot_timeseries then plots these new timeseries, and the user can choose which datasets are included via the obs_to_include parameter. As I mentioned above, Panel interfaces nicely with several other plotting libraries – here I elected to use hvPlot with the Bokeh backend to add zooming and panning capabilities to the timeseries plot. Finally, get_2023_anomaly reports the 2023 temperature anomalies relative to the new baseline (where I’ve used Panel’s Number indicator to color-code the anomaly report for some added glitz).
Now, let’s add interactivity to these functions via Panel. First, we define a set of ‘widgets’ that allow the user to enter their chosen baseline, and which observational datasets to include in the plots:
Panel has a large number of widgets available for different use cases, so I encourage you to check those out. Then, we use Panel’s bind functionality to define reactive or bound versions of the functions above:
# Interactivity is generated by pn.bind
interactive_anomaly = pn.bind(get_2023_anomaly, obs_to_include, new_baseline_start, new_baseline_end)
interactive_plot = pn.bind(plot_timeseries, obs_to_include, new_baseline_start, new_baseline_end)
These functions will now be automatically re-run upon a user interaction. Finally, we can construct the dashboard by using a combination of Panel’s row and column layouts:
Et voila! You’ve just built your first Panel dashboard. If you run the code in the Google Colab notebook, it should look something like this:
You can try changing the baseline, zooming and panning around the plot, and toggling the datasets on/off. Notice that using an earlier baseline period typically results in a larger disagreement among the different products, reflecting the large uncertainties in early temperature measurements.
Facilitating a deeper exploration of published results
We relied on Panel to produce a more elaborate dashboard to accompany a recent paper, Downscaling and bias-correction contribute considerable uncertainty to local climate projections in CMIP6, published in npj Climate & Atmospheric Science last year [6]. In brief, the goal of this paper was to understand the relative importance of various sources of uncertainty in local climate projections. In addition to the traditional sources of climate uncertainty, such as model uncertainty (different climate models can simulate different future climates) and internal variability (related to the chaotic nature of the Earth system), we also looked at downscaling and bias-correction uncertainty, which arises from the variety of available post-processing methods that aim to make climate model outputs more actionable (i.e., higher spatial resolution and reduced biases relative to observations). Our results were highly heterogeneous across space, time, and indicators of climate change, so it was challenging to condense everything into a few figures for the paper. As such, we developed a dashboard to allow users to explore our results in more detail by focusing in on specific locations or time periods that might be of more interest to them:
We relied on Panel for this dashboard mainly for its flexibility. Panel allowed us to include several different plot types and user interaction features, along with text boxes and figures to provide additional information. For example, users can explore the uncertainty breakdown at different locations by zooming and panning around a map plot, entering specific latitude and longitude coordinates, or selecting from a drop-down list of almost 900 world cities. As someone not well-versed in HTML or JavaScript, a major advantage provided by Panel was the ability to construct everything in Python.
Our dashboard is publicly available (https://lafferty-sriver-2023-downscaling-uncertainty.msdlive.org/) and we’d love for you to check it out! For deploying the dashboard, we worked with Carina Lansing and Casey Burleyson from PNNL to make it available on MSD-LIVE. MSD-LIVE (the MultiSector Dynamics Living, Intuitive, Value-adding, Environment) is a cloud-based flexible and scalable data and code management system combined with an advanced computing platform that will enable MSD researchers to document and archive their data, run their models and analysis tools, and share their data, software, and multi-model workflows within a robust Community of Practice. For the dashboard, we leveraged MSD-LIVE’s cloud computing capabilities to support the on-demand computing required to generate the plots. When a user clicks on the dashboard link, MSD-LIVE spins up a dedicated computing instance on the Amazon Web Services (AWS) cloud. That computing instance has the required Python packages pre-installed and is directly connected to the dataset that underpins the dashboard. Once the dashboard is closed or after a period of inactivity the dedicated computing instance is spun down. The underlying cloud computing capabilities in MSD-LIVE have also been used to support Jupyter-based interactive tutorials used to teach new people to use MSD models.
Conclusion
I hope this blog post has served as a useful introduction to Panel’s capabilities, and perhaps sparked some new ideas about how to visualize and communicate your scientific data and results. Although the temperature anomaly dashboard we created earlier was very simple, I think it demonstrates the key steps towards constructing more complicated apps: write functions to produce your desired visualizations, add interactivity via pn.bind, then arrange your dashboard using Panel’s plethora of panes, widgets, and layout features. Like any coding project, you will invariably run into unforeseen difficulties – there was definitely some trial-and-error involved in building the more complicated dashboard associated with our paper – but following this ordered approach should allow you to start creating interactive (and hopefully more effective) scientific visualizations. I would also encourage you to check out the Panel component and app galleries for yet more inspiration and demonstrations of what Panel can do.
Hawkins, E., et al., Estimating Changes in Global Temperature since the Preindustrial Period, Bull. Amer. Meteor. Soc., 98, 1841–1856, https://doi.org/10.1175/BAMS-D-16-0007.1
Lafferty, D.C., Sriver, R.L. Downscaling and bias-correction contribute considerable uncertainty to local climate projections in CMIP6. npj Clim Atmos Sci6, 158 (2023). https://doi.org/10.1038/s41612-023-00486-0
In 1962 a group of economists, engineers and political scientists who were involved in the Harvard Water Program published “Design of Water Resource Systems“. In chapter 12 of the book, Thomas and Fiering present the following statistical model which was one of the first, if not the first, formal application of stochastic modelling for synthetic streamflow generation and water resource systems evaluation.
It is an autoregressive model which can simulate monthly streamflow values based on the mean, variance, and correlation of historic observations.
In this blog post, I present the model in it’s original form along with a modified form presented by Stedinger and Taylor (1982). Then, I share a Python implementation of the model which is used to generate an ensemble of synthetic flows. I use plotting tools from the Synthetic Generation Figure Library to plot the results.
The model that Thomas and Fiering proposed took the form:
Where, for each month , is the generated flow, is the mean historic flow, is an autoregression coefficient for predicting that months flow from the prior months flow, is the standard deviation, is the correlation coefficient and is a random standard normal variable.
A modification to this model was proposed by Stedinger and Taylor (1982), which transforms transforms the streamflow values before fitting the model. I refer to this as the “Stedinger transformation” below and in the code.
Given as the observed flows in month , the Stedinger transformation of the observed flows is then:
where is the estimated “lower bound” for each month, calculated as:
The modeled flows are generated from the recursive relationship:
Where:
is the observed average historic monthly series
is the observed variance of the historic monthly series
independent standard-normal random variables
observed between-month correlations of the historic series
The above steps are performed for each month, and the synthetic streamflow sequence is generated by iteratively applying the stochastic process for the desired duration.
Python Implementation
I built this version of the Thomas Fiering model as a Python class with the following structure:
class ThomasFieringGenerator():
def __init__(self, Q, **kwargs):
def preprocessing(self, **kwargs):
# Stedinger normalization
def fit(self, **kwargs):
# Calculate mu, sigma, and rho for each month
def generate(self, n_years, **kwargs):
# Iteratively generate a single timeseries
# Inverse stedinger normalization
return Q_synthetic
def generate_ensemble(self, n_years,
n_realizations = 1,
**kwargs):
# Loop and generate multiple timeseries
return
Rather than posting the entire code here, which would clutter the page, I will refer you to and encourage you to check out the full implementation which is in the linked repository here: ThomasFieringModelDemo/model.py
First we consider the range of historic and synthetic streamflow timeseries:
Generally when working with synthetic ensembles it is good for the distribution of synthetic ensembles “envelope” the historic range while maintaining a similar median. The Thomas Fiering model does a good job at this!
The next figure shows the range of flow-quantile values for both historic and synthetic flows. Again, we see a nice overlapping of the synthetic ensemble:
Conclusions
I personally think it is fun and helpful to look back at the foundational work in a field. Since Thomas and Fiering’s work in the early 1960s, there has been a significant amount of work focused on synthetic hydrology.
The Thomas Fiering model has a nice simplicity while still performing very nicely (with the help of the Stedinger normalization). Sure there are some limitations to the model (e.g., the estimation of distribution and correlation parameters may be inaccurate for short records, and the method does not explicitly prevent the generation of negative streamflows), but the model, and the Harvard Water Program more broadly, was successful in ushering in new approaches for water resource systems analysis.
References
Maass, A., Hufschmidt, M. M., Dorfman, R., Thomas, Jr, H. A., Marglin, S. A., & Fair, G. M. (1962). Design of water-resource systems: New techniques for relating economic objectives, engineering analysis, and governmental planning. Harvard University Press.
Stedinger, J. R., & Taylor, M. R. (1982). Synthetic streamflow generation: 1. Model verification and validation. Water resources research, 18(4), 909-918.
In this post, I will delve into the transformative realm of geocoding, addressing the challenges posed by historical data laden with addresses. Throughout the discussion, I’ll guide you through the intricacies of leveraging the Google API key to seamlessly integrate location information.
Key points include:
- Preparing your digital workspace for geocoding with essential tools.
- Obtaining a Google API key to unlock the power of precise coordinates.
- Applying practical steps to effortlessly transform addresses into valuable spatial insights using Pandas DataFrame.
ArcGIS Developers. (n.d.). ArcGIS API for Python. Retrieved from here.
As we study the realm of data-driven exploration, a significant challenge surfaces—one that personally resonated with me during my recent project. Historical data, often a treasure trove of insights, can be a double-edged sword. The challenge arises when this wealth of information arrives with addresses instead of coordinates, adding a layer of complexity to the analysis. In my own experience, this meant that a substantial portion of the received data was, unfortunately, unusable for my intended analysis without a transformative solution.
This is where geocoding steps in as a crucial ally, reshaping the landscape of historical datasets and making them analysis-ready. The inconsistency in reporting formats and the absence of standardized coordinates pose hurdles that can impede meaningful analysis. Geocoding becomes an indispensable tool, allowing me to bridge this gap, harmonize the data, and unlock its full potential for analysis.
This post focuses on the intricacies of geocoding—a transformative process that transcends mere addresses, providing the geographic insights necessary for a comprehensive understanding of your dataset. Equipped with the Google API key, we’ll delve into the practical steps needed to seamlessly integrate location information. The following sections outline the key stages of this geocoding journey, ensuring your dataset is prepared for advanced analysis.
Preparing your environment
Prepare your digital workspace for this impactful data transformation by ensuring you have all the necessary tools. Seamlessly install GoogleMaps and Pandas using the commands provided below in your terminal.
In the realm of geocoding, the importance of formatting data before initiating the geocoding process cannot be overstated, especially when leveraging the capabilities of the Google API key. The formatting step is a vital prerequisite for several reasons. Firstly, it ensures consistency and standardization in the structure of addresses, aligning them with the expectations of geocoding services. This consistency allows for more accurate interpretation and processing of addresses. Additionally, formatted addresses provide a clear separation of components such as city, state, and ZIP code, facilitating efficient matching during the geocoding algorithm’s execution. The optimization of API usage is another benefit, as well-formatted addresses contribute to accurate results, minimizing unnecessary costs associated with incorrect or ambiguous requests. By addressing these considerations in the formatting stage, one sets the stage for a more reliable and cost-effective geocoding journey, unlocking the full potential of spatial insights. Now, let’s delve into the practical implementation of this formatting process with the following code, which creates a new column containing the consolidated and formatted addresses within your dataset.
# Create new dataframe just with the address
df['ADDRESS'] = df['CITY'] + ',' + \
df['STATE'] + ' ' + \
df['ZIP'].astype(str)
Under the Project drop-down menu, select the project that you want to work on. If one does not already exist, create a new project
Under the Library tab on the side menu, search “geocoding api” and ensure that it is enabled
Under the Credentials tab on the side menu, select “Create Credentials” and create a new API key to generate a new key
Your Google API key will then appear on the screen, save this key for future use
Geocoding with Pandas DataFrame
With your environment set up, your data formatted, and your Google API key in hand, it’s time to wield this powerful tool. Dive into the practical realm of geocoding by seamlessly applying the sample code below to your dataset, effortlessly transforming addresses into precise coordinates. Follow the code through each practical step, and witness your location data evolve into a valuable asset, ready for advanced analysis.
# Import necessary libraries
import googlemaps
import pandas as pd
# Define your API key
# Replace "YOUR_GOOGLE_API_KEY" with your actual Google Maps API key that you saved previously.
gmaps_key = googlemaps.Client(key="YOUR_GOOGLE_API_KEY")
# Extract the last column (ADDRESS) to create a new dataframe (df_address)
df_address = df.iloc[:, -1:]
# Geocoding with Pandas DataFrame
# Define a function to geocode addresses and extract latitude and longitude
def geocode_and_extract(df_address):
# Add empty columns for latitude and longitude
df_address['LATITUDE'] = ""
df_address['LONGITUDE'] = ""
# Loop through each row in the df_address dataframe
for i in range(len(df_address)):
address = df_address['ADDRESS'][i]
# Geocode the address using the Google Maps API
geocode_result = gmaps_key.geocode(address)
# Check if geocoding was successful
if geocode_result:
# Extract latitude and longitude from the geocoding result
df_address['LATITUDE'][i] = geocode_result[0]['geometry']['location']['lat']
df_address['LONGITUDE'][i] = geocode_result[0]['geometry']['location']['lng']
# Apply the geocoding function to your dataframe
geocode_and_extract(df_address)
# Print an example to verify correctness
example_address = df_address['ADDRESS'][0]
example_result = gmaps_key.geocode(example_address)
example_lat = example_result[0]["geometry"]["location"]["lat"]
example_long = example_result[0]["geometry"]["location"]["lng"]
print(f'Example Geocoded Address: {example_address}, Latitude: {example_lat}, Longitude: {example_long}')
# Let's join the coordinates with the original dataset
df['LATITUDE'] = df_address['LATITUDE']
df['LONGITUDE'] = df_address['LONGITUDE']
Replace "YOUR_GOOGLE_API_KEY" with your actual Google Maps API key that you saved previously.
Dealing with incomplete data
In the midst of my geocoding journey, I encountered a common challenge: incomplete data. Some addresses in my dataset were detailed with full street information, while others provided only city and state. The beauty of the Google API key revealed itself as it effortlessly transformed both types of data, allowing for a seamless integration of geographic insights.
This flexibility became especially crucial as I navigated through points where only city and state information existed. While it may seem like a potential hurdle, the Google API key’s ability to interpret varying address formats ensured that no data was left behind. For my specific analysis, the key only needed to fall within a designated radius of interest, and the results proved to be accurate enough for my purposes.
In handling diverse data formats, the Google API key stands as your ally, harmonizing and geocoding all pieces of the puzzle, ensuring that each contributes to the rich narrative your dataset is meant to tell.
Conclusion
Your geocoding journey has now equipped you to handle diverse datasets, turning a potential challenge into a transformative opportunity. As you venture forth, may your analyses unveil fresh perspectives and illuminate the hidden stories within your spatial data. The Google API key has been the linchpin throughout this exploration, ensuring that every piece of information contributes to the bigger picture. From handling varying addresses to pinpointing detailed locations, the key’s flexibility has proven invaluable, providing accurate insights.
Congratulations on mastering the art of geocoding—may your data-driven adventures persist in revealing the intricate layers of time, geography, and the untold stories that lie within.
Previously, in Part 1 I used a very simple reservoir operations scenario to demonstrate some linear programming (LP) concepts.
After some feedback on my initial formulation I went back and revised the formulation to make sure that (1) both reservoir releases and storage levels are optimized simultaneously and (2) the LP handles decisions over multiple timesteps (1,…,N) during optimization. Definitely look back at Part 1 for more context.
The current LP formulation is as follows:
In this post, I show a simple implementation of this LP using the Pyomo package for solving optimization problems in Python.
I have shared the code used in this demo in a repository here: Reservoir-LP-Demo
Constructing the LP model with Pyomo
While Pyomo can help us construct the LP model, you will need access to a separate solver software in order to actually run the optimization. I don’t get into the details here on how to set up these solvers (see their specific installation instructions), but generally you will need this solver to be accessible on you PATH.
Two solvers that I have had good experience with are:
As always, it’s best to consult the Pyomo documentation for any questions you might have. Here, I highlight a few things that are needed for our implementation.
We start by importing the pyomo.environ module:
import pyomo.environ as pyo
From this module we will need to use the following classes to help build our model:
pyo.ConcreteModel()
pyo.RangeSet()
pyo.Var()
pyo.Objective()
pyo.Constraint()
pyo.SolverFactory()
The nice thing about using pyomo rather than trying to manage the LP matrices yourself is that you can specify objectives and constraints as functions.
For example, the objective function is defined as:
# Objective Function
def objective_rule(m):
return -sum((eta_0 * m.R[t]) + (m.S[t]/S_max*100) for t in m.T)
And a constraint used to enforce the lower limit of the storage mass balance can defined as:
Rather than picking the full implementation apart, I present the entire function below, and encourage you to compare the code implementation with the problem definition above.
def pyomo_lp_reservoir(N, S_min, S_max, R_min, R_max,
eta_0, I, D,
initial_storage):
# Model
model = pyo.ConcreteModel()
# Time range
model.T = pyo.RangeSet(0, N-1)
# Decision Variables
model.S = pyo.Var(model.T, bounds=(S_min, S_max)) # Storage
model.R = pyo.Var(model.T, bounds=(R_min, R_max)) # Release
# Objective Function
def objective_rule(m):
return -sum((eta_0 * m.R[t]) + (m.S[t]/S_max*100) for t in m.T)
model.objective = pyo.Objective(rule=objective_rule, sense=pyo.minimize)
# Constraints
def S_balance_lower(m, t):
if t == 0:
return m.S[t] + m.R[t] <= initial_storage + I[t] - D[t]
return m.S[t] + m.R[t] <= m.S[t-1] + I[t] - D[t]
def S_balance_upper(m, t):
if t == 0:
return -(m.S[t] + m.R[t]) <= -(initial_storage + I[t] - D[t])
return -(m.S[t] + m.R[t]) <= -(m.S[t-1] + I[t] - D[t])
model.S_lower = pyo.Constraint(model.T, rule=S_balance_lower)
model.S_upper = pyo.Constraint(model.T, rule=S_balance_upper)
model.S_final = pyo.Constraint(expr=model.S[N-1] == initial_storage)
# Solve
solver = pyo.SolverFactory('scip')
results = solver.solve(model)
if results.solver.status == pyo.SolverStatus.ok:
S_opt = np.array([pyo.value(model.S[t]) for t in model.T])
R_opt = np.array([pyo.value(model.R[t]) for t in model.T])
return S_opt, R_opt
else:
raise ValueError('Not able to solve.')
Note that in this implementation, pyomo will optimize all of the reservoir release and storage decisions simultaneously, returning the vectors of length N which prescribe the next N days of operations.
Usage
Now we are ready to use our LP reservoir simulator. In the code block below, I set some specifications for our operational constraints, generate fake inflow and demand timeseries, run the LP solver, and plot the simulated results:
# spcifications
N_t = 30
S_min = 2500
S_max = 5000
R_min = 10
R_max = 1000
eta = 1.2
# Generate simple inflow and demand data
I, D = generate_data(N_t, correlation_factor = -0.70,
inflow_mean=500, inflow_std=100,
lag_correlation=0.2)
# Run LP operation simulation
S_sim, R_sim = pyomo_lp_reservoir(N_t, S_min, S_max, R_min, R_max, eta, I, D,
initial_storage=S_max)
# Plot results
plot_simulated_reservoir(I, D,
R_sim, S_sim,
S_max, eta=eta)
The operations are shown:
Under this LP formulation, with a perfect inflow forecast, the reservoir operates as a “run of river” with the release rates being very close to the inflow rate.
In practice, operators may need to limit the difference in release volume from day-to-day. I added an optional parameter (R_change_limit) which adds a constraint on the difference subsequent releases from between each day.
The operations, with the daily release change rate limited to 50 is shown below.
Conclusions
The way you formulate the an LP problem dictates the “optimal” decisions that you will generate. The purpose of these past two posts was to make some attempt at giving a practice demo of some basic LP concepts. I hope for some that it might be useful as a starting point.
Stochastic programming (SP) is an approach to decision-making under uncertainty (alongside robust optimization and chance constrained optimization). It is an extension of deterministic optimization techniques such as linear (or non-linear) programming that incorporates stochastic elements (hence the name) in the form of multiple potential future scenarios. Overall, the aim of stochastic programming is to identify optimal solutions to a given problem that perform well under a finite range of possible scenarios. This is done by optimizing the expected value of the objective function over all scenarios. For clarification, a “scenario” in the context of SP is defined as the combined realization (expected outcome) of all future uncertainties.
There are two versions of an SP problem: the two-stage SP problem consists of two decision-making stages, where the first stage decisions represent the decisions taken before the uncertainty (the future scenario, in this case) unfolds and becomes known. The second stage decisions are taken once the future has unfolded and corrective action needs to be taken. Two-stage SP problems are typically used for scenario planning, where a decision-maker’s goal is to identify a solution that will result in good performance across all potential scenarios. Next, the multi-stage SP problem with -stages is an extension of the two-stage SP problem, where the decision at stage is dependent on all decisions made up until . Due to the problem’s high dimensionality, the multi-stage SP problem is typically represented using a scenario tree with each branch associated with a probable outcome and its probability and each level associated with a stage .
In this post, I will provide a two-stage stochastic programming example discuss the pros and cons of its use. In the following post, I will and demonstrate how to approach and solve such a problem using the Python cvxpy library.
The infrastructure selection example
Disclaimer: All values are arbitrary .
A water utility serving the residents of Helm’s Keep (57,000 households) are deciding on a water supply storage expansion project to meet projected increase in demand and wants to identify a suitable yet affordable project to invest in:
Option 1: Water treatment capacity expansion on the distant (but yet untapped) Lake Heleborn
Option 2: The construction of small local reservoir on the outskirts of Helm’s Keep
Option 3: Construction of a new groundwater pumping station
Each of these infrastructure options are associated with the following capital investment costs. The variable capital cost and variable operating cost are functions of the infrastructure options and expected demand (both in MGD).
Fixed capital cost ($mil)
Variable capital cost ($mil/MGD capacity)
Variable operating cost ($mil/MGD demand)
Option 1
15.6
7.5
0.2
Option 2
11.9
4.7
0.5
Option 3
13.9
5.1
0.9
Helm’s Keep’s priority in the selection of its new water supply infrastructure is to minimize its total infrastructure net present cost:
where is the infrastructure net present cost, is bond term for an infrastructure option, and is the discount rate for a given year of debt service payment for an infrastructure option since its bond was issued. The value of is calculated as follows:
where is the bond principal (the total value of the bond), is the bond interest rate to be paid to the creditor throughout the bond term . All payments are discounted to their present value. The value of the bond principal is dependent on the capacity of the infrastructure option and is calculated as a function of the fixed and variable capital costs:
such that is the capital cost of infrastructure option and is a binary variable indicating if option is chosen. is the variable capital cost of infrastructure option , and is the final built capacity of .
In addition, there is some water loss in transporting water from either location due to aging infrastructure, which will result in losses caused by non-revenue water (NRW). The losses associated with option are listed below:
Option 1: 20% water loss
Option 2: 10% water loss
Option 3: 12% water loss
Helm’s Keep must also consider the debt is undertaking relative to its potential annual net revenue , calculated as follows:
where is per-capita daily water delivered, is the per-household uniform water rate, and is the percentage of water lost during transmission given that infrastructure was chosen. is Helm’s Keep’s daily operating costs per capita where
such that is the demand in scenario for infrastructure option , is the variable operating cost of , and is the percentage of NRW.
However, it must also meet the following constraints:
The infrastructure option decision is exclusive (only one option can be selected).
The total capacity of the chosen infrastructure option cannot be less than 1.2 times that of daily demand increase (after accounting for NRW).
Daily deliveries be at least equal to demand (after accounting for NRW).
All water produced (after accounting for NRW) are considered for-revenue water and result in gross revenue.
Annual payments should not exceed 1.25 times that of Helm’s Keep’s annual net revenue .
There are three possible scenarios of water demand increase , Federal Reserve bond interest rate, and discount rate. The probability of each scenario is listed in the table below:
Scenarios
Demand increase (MGD)
Bond rate (%)
Discount rate (%)
Probability (%)
Scenario 1
4.4
4.3
3.1
0.35
Scenario 2
5.2
2.6
2.6
0.41
Scenario 3
3.9
5.2
2.5
0.24
Helm’s Keep faces the following decisions:
Stage 1: Which infrastructure option to build and to what capacity for ?
Stage 2: How much will Helm’s Keep’s corresponding bond principal be how much water is delivered in each scenario?
Formulating the problem
Let the first-stage decision variables be:
Infrastructure option selection where and
Capacity of each infrastructure option
Next, we set up the second stage decision variables. Let , and be the amount of water delivered, bond rate, and discount rate, in scenario . This will result in the following problem setup:
where
with constraints
such that
and is the probability of scenario and .
Some caveats
As we walked through the formulation of this two-stage stochastic programming problem, it quickly becomes apparent that the computational complexity of such an approach can quickly become intractable when the number of uncertain scenarios and the complexity of the model (large number of uncertain parameters) is high. In addition, this approach assumes a priori knowledge of future uncertainty and sufficient underlying expert knowledge to generate 6uncertainty estimates, which cannot guarantee that the theoretical robustness of the identified solution to real world outcomes if the estimated uncertainty does not match the estimated uncertainty. We can see that this method may therefore be best suited for problems where uncertainty can be accurately characterized and modeled as random variables or scenarios. It is nonetheless a useful approach for addressing problems in manufacturing, production line optimization, financial portfolio design, etc, where data is abundant and uncertainty is well-characterized, and then identifying solutions that perform well across a finite number of scenarios.
In this post, we covered an introduction to stochastic programming and provided a 2-stage infrastructure investment selection example to demonstrate the method’s key concepts. In the next post, we will walk through the installation and use of the Python cvxpy library and use it to solve this problem to identify the most suitable infrastructure option to invest in, its final built capacity, and its total demand fulfilled.
If you were like me, you may have been provided an overview of linear programming (LP) methods but craved a more hands-of demonstration, as opposed to the abstract/generic mathematical formulation that is often presented in lectures. This post is for the hydrology enthusiasts out there who want to improve their linear programming understanding by stepping through a contextual example.
In this post, I provide a very brief intro to linear programming then go through the process of applying a linear programming approach to a simple hydroelectric reservoir problem focused on determining a release rate that will consider both storage targets and energy generation. In a later post, I will come back to show how the formulation generated here can be implemented within simulation code.
Content:
An introduction to linear programming
Formulating an LP
Solving LP problems: Simplex
Relevance for water resource managers
A toy reservoir demonstration
The problem formulation
Constraints
Objective
Conclusions and what’s next
An introduction to linear programming
Linear programming (LP) is a mathematical optimization technique for making decisions under constraints. The aim of an LP problem is to find the best outcome (either maximizing or minimizing) given a set of linear constraints and a linear objective function.
Formulating an LP
The quality of an LP solution is only as good as the formulation used to generate it.
An LP formulation consists of three main components:
1. Decision Variables: These are the variables that you have control over. The goal here is to find the specific decision variable values that produce optimal outcomes. There are two decision variables shown in the figure below, x1 and x2.
2. Constraints: These are the restrictions which limit what decisions are allowed. (For our reservoir problem, we will use constraints to make sure total mass is conserved, storage levels stay within limits, etc.) The constraints functions are required to be linear, and are expressed as inequality relationships.
3. Objective Function: This is the (single) metric used to measure outcome performance. This function is required to be linear and it’s value is denoted Z in the figure below, where it depends on two decision variables (x1, and x2).
In practice, the list of constraints on the system can get very large. Fortunately matrix operations can be used to solve these problems quickly, although this requires that the problem is formatted in “standard form” shown above. The standard form arranges the coefficient values for the constraints within matrices A and b.
Solving LP problems: keep it Simplex
Often the number of potential solutions that satisfy your constraints will be very large (infinitely large for continuous variables), and you will want to find the one solution in this region that maximizes/minimizes your objective of interest (the “optimal solution”).
The set of all potential solutions is referred to as the “feasible space” (see the graphic below), with the constraint functions forming the boundary edges of this region. Note that by changing the constraints, you are inherently changing the feasible space and thus are changing the set of solutions that you are or are not considering when solving the problem.
Recognizing this, George Dantzig proposed the Simplex algorithm which strategically moves between vertices on the boundary feasible region, testing for optimality until the best solution is identified.
A detailed review of the Simplex algorithm warrants it’s own blog post, and wont be explained here. Fortunately there are various open LP solvers. For example, one option in Python is scipy.optimize.linprog().
Relevance for water resource managers
Why should you keep read this post?
If you work in water resource systems, you will likely need to make decisions in highly constrained settings. In these cases, LP methods can be helpful. In fact there are many scenarios in water resource management in which LP methods can (and historically have) been useful. Some general application contexts include:
Resource allocation problems: LP can be used to allocate water efficiently among different users like agriculture, industry, and municipalities.
Operations optimization: LP can guide the operations decisions of water reservoirs, deciding on storage levels, releases, and energy production to maximize objectives like water availability or energy generation from hydropower (the topic of this demonstration below).
Toy Reservoir Demonstration: Problem Formulation
The following demo aims to provide a concrete example of applying linear programming (LP) in the realm of water resource management. We will focus on a very simple reservoir problem, which, despite its simplicity, captures the essence of many real-world challenges.
Imagine you are managing a small hydroelectric reservoir that provides water and energy to a nearby town. Your goal is to operate the reservoir, choosing how much water to release each day such that the (1) the water level stays near a specific target and (2) you maximize energy generation. Additionally, there is a legally mandated minimum flow requirement downstream to sustain local ecosystems
Here, I will translate this problem context into formal LP notation, then in a later post I will provide Python code to implement the LP decision making process within a simulation model.
Problem formulation
We want to translate our problem context into formal mathematical notation that will allow us to use an LP solver. In order to help us get there, I’ve outlines the following table with all the variables being considered here.
Decision variables
In this case the things we are controlling at the reservoir releases (Rt), and the storage level (St) at each timestep.
Constraints:
Constraints are the backbone of any LP problem, defining the feasible space which ultimately dictates the optimal solution. Without constraints, an LP problem would have infinite solutions, rendering it practically meaningless. Constraints are meant to represent any sort of physical limitations, legal requirements, or specific conditions that must be satisfied by your decision. In the context of water resource management, constraints could signify capacity limits of a reservoir, minimum environmental flow requirements, or regulatory water diversion limits.
Mass balance requirement:
Naturally you want to make sure that mass is conserved through the reservoir, by balancing all of the inflows, outflows and storage states, for each timestep (t):
Although we need to separate this into two separate inequalities in order to meet the “standard form” for an LP formulation. I am also going to move the decision variables (Rt and St) to the left side of the inequalities.
Storage limitations:
The most obvious constraints are that we don’t want the reservoir to overflow or runout of water. We do this by requiring the storage to be between some minimum (Smin) and maximum (Smax) values specified by the operator.
Again we need to separate this into two separate inequalities:
Maximum and minimum release limitations:
The last two constraints represent the physical limit of how much water can be discharged out of the reservoir at any given time (Rmax) and the minimum release requirement that is needed to maintain ecosystem quality downstream of the reservoir (Rmin).
Objective:
The objective function in an LP represents your goals. In the case of our toy reservoir, we have two goals:
Maximize water storage
Maximize energy production.
Initially when I was setting this demonstration up, there was no hydroelectric component. However, I chose to add the energy generation because it introduces more complexity in the actions (as we will see). This is because the two objectives conflict with one another. When generating energy, the LP is encouraged to release a lot of water and maximize energy generation, however it must balance this with the goal of raising the storage to the target level. This tension between the two objectives makes for much more interesting decision dynamics.
1. Objective #1: Maximize storage
Since our reservoir managers want to make sure the Town’s water supply is reliable, they want to maximize the storage. This demo scenario assumes that flood is not a concern for this reservoir. We can define objective one simply as:
Again, we can replace the unknown value (St) with the mass-balance equation described above to generate a form of the objective function which includes the decision variable (Rt):
We can also drop the non-decision variables (all except Rt) since these cannot influence our solution:
2. Objective #2: Maximize energy generation:
Here I introduce a second component of the objective function associated with the amount of hydroelectric energy being generated by releases. Whereas the minimize-storage-deviation component of the objective function will encourage minimizing releases, the energy generation component of the objective function will incentivize maximizing releases to generate as much energy each day as possible.
I will define the energy generated during each timestep as:
(1+2). Aggregate minimization objective: Lastly, LP problems are only able to solve for a single objective function. With that said, we need to aggregate the storage and energy generation objectives described above. In this case I take a simple sum of the two different objective scores. Of course this is not always appropriate, and the weighting should reflect the priorities of the decision makers and stakeholders.
In this case, this requires a priori specification of objective preferences, which will determine the solution to the optimization. In later posts I plan on showing an alternative method which allows for posterior interpretation of objective tradeoffs. But for now, we stay limited with the basic LP with equal objective weighting.
Also, we want to formulate the optimization as a minimization problem. Since we are trying to maximize both of our objectives, we will make them negative in the final objective function.
The final aggregate objective is calculated as the sum of objectives of the N days of operation:
Final formulation:
As we prepare to solve the LP problem, it is best to lay out the complete formulation in a way that will easily allow us to transform the information into the form needed for the solver:
Conclusions and what’s next
If you’ve made it this far, good on you, and I hope you found some benefit to the process of formulating a reservoir LP problem from scratch.
This post was meant to include simulated reservoir dynamics which implement the LP solutions in simulation. However, the post has grown quite long at this point and so I will save the code for another post. In the meantime, you may find it helpful to try to code the reservoir simulator yourself and try to identify some weaknesses with the proposed operational LP formulation.
Thanks for reading, and see you here next time where we will use this formulation to implement release decisions in a reservoir simulation.
In this post on the Water Programming Blog, we continue to explore the application of the stochastic weather generator (available on GitHub) for climate-change scenario developments. This is the second installment of a two-part series of blog posts, and readers are strongly encouraged to familiarize themselves with different components of the stochastic weather generator, as explained in Part 1 by Rohini Gupta (The Reed Research Group).
Here, we will begin by offering a concise overview of developing climate change scenarios and how these scenarios are integrated into the weather generation model. Following this, we will proceed to interpret the impact of these climatic change conditions on key statistical insights concerning occurrences of floods and droughts. Through these examples, the implications of these climatic shifts on water resources management and flood risk analysis will become evident.
Climate Change Perturbations
In this stochastic weather generator, we specifically focus on two aspects of climate change scenario developments, including 1) thermodynamic and 2) dynamic perturbations.
1) Thermodynamic Change
Thermodynamic climate change, often referred to as temperature-driven change, is primarily driven by changes in the Earth’s energy balance and temperature distribution. This warming affects various aspects of the climate system, such as intensifying precipitation extremes, melting snowpacks and ice sheets, rising sea levels, altered weather patterns, and shifts in ecosystems. The primary driver of temperature-driven climate change is the increase in regional-to-global average temperatures due to the enhanced greenhouse effect. As temperatures rise due to natural and anthropogenic forcings, they trigger a cascade of interconnected impacts throughout the climate system.
In the stochastic weather generator, scenarios of temperature change are treated simply by adding trends to simulated temperature data for each location across the spatial domain. However, scenarios of thermodynamic precipitation intensification are modeled using a quantile mapping technique through scaling the distribution of daily precipitation in a way that replicates the effects of warming temperatures on precipitation as the moisture holding capacity of the atmosphere increases. In the context of California, previous studies have demonstrated that as temperatures rise, the most severe precipitation events (often associated with Atmospheric Rivers landfalling) are projected to increase in frequency, while the intensity of smaller precipitation events is expected to decrease (Gershunov et al., 2019). This alteration effectively stretches the distribution of daily precipitation, causing extreme events to become more pronounced while reducing the occurrence and strength of lighter precipitation events. We replicate this phenomenon by making adjustments to the statistical characteristics and distribution percentiles of precipitation (e.g., Pendergrass and Hartmann, 2014). To further elaborate on this, we select a scaling factor for the 99th percentile of nonzero precipitation and then modify the gamma-GPD mixed distribution to enforce this chosen scaling factor. For instance, in a scenario with a 3°C temperature warming and a 7% increase in extreme precipitation per °C (matching the theoretical Clausius-Clapeyron rate of increase in atmospheric water holding capacity due to warming; Najibi and Steinschneider (2023)), the most extreme precipitation events are projected to increase by approximately 22.5% (1.073). We adjust the gamma-GPD models fitted to all locations to ensure this percentage increase in the upper tail of the distribution. Assuming that mean precipitation remains constant at baseline levels, this adjustment will cause smaller precipitation values in the gamma-GPD model to decrease, compensating for the increase in extreme events through stretching the distribution of nonzero precipitation.
Lines 33-40 from ‘config.simulations.R’ show the user-defined changes to implement the thermodynamic scenarios based on temperature in Celsius (tc: e.g. 1 °C), percent change in extreme precipitation quantile (pccc: e.g. 7% per °C), and percent change in average precipitation (pmuc: e.g. 12.5% decrease) inputs. Needless to say that the stochastic weather generator runs at baseline mode if tc=0 and pmuc=0.
Dynamic climate change, also known as circulation-driven change, is driven by shifts in atmospheric and oceanic circulation patterns. These circulation patterns are influenced by a variety of factors, including temperature gradients, differences in air pressure, and Earth’s rotation. Changes in these patterns can lead to alterations in weather patterns, precipitation distribution, and regional climate characteristics. One well-known example of dynamic climate change is the phenomenon of El Niño and La Niña, which involve changes in ocean temperatures and atmospheric pressure in the Pacific Ocean. These events can significantly impact local-to-global weather patterns, causing droughts, heavy rainfall, and other extreme weather events (Pfahl et al., 2017).
Dynamic changes impact the evolution of weather patterns and can modify the occurrence frequency of these patterns. This influence can occur through direct adjustments to the transition probabilities between different weather regimes, or indirectly by modifying the covariates that govern the progression of these weather regimes. In Steinschneider et al. (2019), a Niño 3.4 index is used to force weather regime evolution and is systematically adjusted to create more frequent El Niño and La Niña events. In Gupta et al. (in review), a 600-year long sequence of tree-ring reconstructed principal components of weather regime occurrence are used as an alternative covariate to better capture natural variability inherent in the weather regimes.
In the most recent version of the stochastic weather generator, we developed a novel non-parametric approach to simulation of weather regimes, allowing for future dynamic change scenarios with altered (customized) weather regime probabilities. Assuming that the historical time series of water regimes is divided into distinct, consecutive segments without overlaps, each segment has a duration of D years, and there is a total of ND segments considered there (here, D=4 and ND=18). In the non-parametric method, each segment (indexed as n=1 to ND) is assigned a sampling probability denoted as pn. To generate a new sequence of daily weather regimes spanning any desired number of years, the procedure involves resampling (with replacement) the nth D-year segment of daily weather regimes using the corresponding probability pn. This process is repeated until the required number of years of simulated weather regimes has been attained. If needed, the last segment can be trimmed to ensure the precise desired duration of simulated weather regimes.
In the baseline scenario for the weather generator with no dynamic climate change (only thermodynamic change), each segment is considered equally likely (i.e., no changes to large-scale circulation patterns).
However, the probabilities pn can be adjusted to alter the frequencies of each of the identified weather regimes in the final simulation, enabling the generation of dynamic climate change scenarios (i.e., scenarios in which the frequencies of different atmospheric flow patterns change compared to their historical frequencies). This is achieved using a linear program. The goal of the linear model (not shown) is to identify new sampling probabilities pn that, when used in the non-parametric simulation approach above, create a sequence of weather regimes with long-term average frequencies that approach some vector of target probabilities for those identified weather regimes.
Lines 91-126 from ‘config.simulations.R’ show the user-defined changes to implement a non-parametric scenario with equal probabilities (0: no change to the historical sequence of weather regimes) to ten weather regimes, i.e., dynamic scenario #0; and a 30% increase in weather regime number three (a dry weather condition) in California, i.e., dynamic scenario #1.
##Choose below whether through parametric or non-parametric way to create the simulated WRs ##
use.non_param.WRs <- TRUE #{TRUE, FALSE}: TRUE for non-parametric, FALSE for parametric simulated WRs
dynamic.scenario <- 0 # {0, 1, 2}: 0: no dynamic change; 1: dynamic scenario #1 (30% increase in WR3); or 2: dynamic scenario #2 (linear trend)
if (use.non_param.WRs){ #----------- 1+2 dynamic scenarios ----------#
if (dynamic.scenario==0){
##===> Attempt #0 (thermodynamic only; no change to freq of WRs) ===##
# #specify target change (as a percent) for WR probabilities
WR_prob_change <- c(0,0,0,0,0,0,0,0,0,0) # between 0 and 1
# #how close (in % points) do the WR frequencies (probabilities) need to be to the target
lp.threshold <- 0.00001
# #how much change do we allow in a sub-period sampling probability before incurring a larger penalty in the optimization
piecewise_limit <- .02
}else if(dynamic.scenario==1){
##===> Attempt #1 (dynamic scenario #1) ===##
# #specify target change (as a percent) for WR probabilities (if, increasing WR3 in future)
WR_prob_change <- c(0,0,.3,0,0,0,0,0,0,0) # between 0 and 1
# #how close (in % points) do the WR frequencies (probabilities) need to be to the target
lp.threshold <- 0.007
# #how much change do we allow in a sub-period sampling probability before incurring a larger penalty in the optimization
piecewise_limit <- .02
}else if(dynamic.scenario==2){
##===> Attempt #2 (dynamic scenario #2) ===##
# specify target change (as a percent) for WR probabilities (if, continuing their current trends in future)
WR_prob_change <- c(-0.09969436, 0.27467048, 0.33848792,
-0.28431861, -0.23549986, 0.03889970,
-0.05628958, 0.38059153, -0.16636739, -0.17995965) # between 0 and 1
# how close (in % points) do the WR frequencies (probabilities) need to be to the target
lp.threshold <- 0.008
# how much change do we allow in a sub-period sampling probability before incurring a larger penalty in the optimization
piecewise_limit <- .02
}
}
Stochastic Weather Generation for Climate Change Scenarios
The stochastic weather generator is utilized to generate two climate change scenarios as defined above. The description of specific configurations for each scenario is listed as follows:
Thermodynamic Scenario: 3°C increase in temperature, 7% per °C increase in precipitation extremes, no change in average precipitation.
Dynamic Scenario: 30% increase in occurrence frequency of one weather regime only, labeled as ‘WR3’, which exhibits a ridge directly over the northwest US, i.e., blocking moisture flow over California, and resulting in dry conditions during the cold season there.
Thus, we generated 1008 years of simulated precipitation and temperature for each 12 sites in the Tuolumne River Basin in California (similar to Part 1) following these two scenarios. Below is a list of figures to understand better the impact of each scenario on precipitation and temperature statistical distributions and important climate extremes at basin scale.
The two Figures below present the cumulative distribution function (CDF) of the generated scenario for precipitation (left) and temperature (right) based on the thermodynamic and dynamic change, respectively. The observed time-series of precipitation and temperature across these 12 sites is also illustrated.
As seen above, although the 3°C warming is clearly manifested in the alteration of simulated temperature’s CDF, it is hard to notice any drastic shifts in the overall CDF of precipitation time series, as the bulk of distribution has not been altered (remember the average precipitation remained constant although its extreme quantile scaled up by ~ 22.5%).
Similarly, while the CDF of precipitation demonstrates a slight shift towards a drier condition, we notice a large shift in tail of temperature distribution.
Now, we go ahead and examine a set of important indexes for climate risk assessment of water systems. The Figure below presents the 1-day precipitation maxima derived from the generated scenario for precipitation based on the thermodynamic (left) and dynamic (right) change.
In the plot above depicted for thermodynamic climate change, the median 1-day precipitation extremes at the basin scale throughout the entire synthetic weather generation vs. historical period demonstrates a 25.5% increase in its magnitude, which is consistent with the event-based precipitation scaling by 22.5% at each site. However, such metric has almost remained unchanged in the dynamic climate change scenario.
Finally, the Figure below shows the 5-year drought derived from the generated scenario for water-year precipitation total, based on the thermodynamic (left) and dynamic (right) change.
The boxplots presented above related to the thermodynamic scenario, revealing a consistent median 5-year drought magnitude, as anticipated (no shift in the distribution of average precipitation bulk). In contrast, the dynamic climate change scenario exhibits a substantial exacerbation, with the 5-year drought magnitude worsening by around 9% compared to the historical records.
There is plenty more to explore! The stochastic weather generator is suitable to quickly simulate a long sequence of weather variables that reflect any climate change of interest. Keep an eye out for upcoming additions to the repository in the coming months, and do not hesitate to contact us or create a GitHub issue if you need clarification.
References
Gershunov, A., Shulgina, T., Clemesha, R.E.S. et al. (2019). Precipitation regime change in Western North America: The role of Atmospheric Rivers. Scientific Reports, 9, 9944. https://doi.org/10.1038/s41598-019-46169-w.
Gupta, R.S., Steinschneider S., Reed, P.M. Understanding Contributions of Paleo-Informed Natural Variability and Climate Changes on Hydroclimate Extremes in the Central Valley Region of California. Authorea. March 13, 2023. https://doi.org/10.22541/essoar.167870424.46495295/v1
Najibi, N., and Steinschneider, S. (2023). Extreme precipitation-temperature scaling in California: The role of Atmospheric Rivers, Geophysical Research Letters, 50(14), 1–11, e2023GL104606. https://doi.org/10.1029/2023GL104606.
Pendergrass, A.G., and Hartmann, D.L. (2014). Two modes of change of the distribution of rain, Journal of Climate, 27(22), 8357-8371. https://doi.org/10.1175/JCLI-D-14-00182.1
Pfahl, S., O’Gorman, P.A., Fischer, E.M. (2017). Understanding the regional pattern of projected future changes in extreme precipitation, Nature Climate Change, 7 (6), 423-427. http://dx.doi.org/10.1038/nclimate3287
Steinschneider, S., Ray, P., Rahat, S. H., & Kucharski, J. (2019). A weather‐regime‐based stochastic weather generator for climate vulnerability assessments of water systems in the western United States. Water Resources Research, 55(8), 6923-6945. https://doi.org/10.1029/2018WR024446
In this blog post, we debut the weather-regime-based stochastic weather generator on the Water Programming Blog! This weather generator was first published in the following article:
Steinschneider, S., Ray, P., Rahat, S. H., & Kucharski, J. (2019). A weather‐regime‐based stochastic weather generator for climate vulnerability assessments of water systems in the western United States. Water Resources Research, 55(8), 6923-6945.
Since its inception, the generator has been applied in studies led by researchers primarily affiliated with Cornell or the Army Corp of Engineers. In this blog post, we’ll step through the key theory and components of this weather generator and show how to run a simple simulation and diagnostics with code that is now provided in an official GitHub repo! Future blog posts in this series will step through more sophisticated examples and additions to the generator. Readers can refer to the paper above for more details on the specific components or methods used in this generator.
Why use this generator?
If you are looking to develop alternative local weather scenarios informed by climate changes, you can go down two avenues: (1) using projections from General Circulation Models (GCMs) or (2) using statistical weather generation approaches. GCMs have a rich physical representation of ocean and atmospheric processes and are useful to generate internally consistent scenarios that can ultimately be downscaled to the region of interest. However, due to coarse model resolution, GCMs exhibit significant variability and biases in processes that are important for regional planning and vulnerability assessments like precipitation, atmospheric river flux and droughts. These models are also computationally expensive to run and so you are limited to a few storylines of warming scenarios to explore.
Stochastic weather generators, however, are a complementary way to develop local weather scenarios. They are directly conditioned on the weather of the region of interest and therefore can better capture regional processes and be more applicable to regional water systems planning. This generator can be used to create many scenarios that preserve regional and temporal statistics but are not bounded by the historical record; notably these scenarios can also be generated in a computationally efficient manner. The output from these generators can also be systematically adjusted to create basic climate change scenarios. What is often missing from these statistical models, however, is process information, and this is where the weather-regime-based stochastic generator can be useful.
What are the key components of this generator?
Figure 1: Generator flow chart (Steinschneider et al., 2019)
Figure 1 shows the main components of the first version of the generator, some of which have been extended or altered in newer studies. There are three primary levels to this generator listed below.
Simulation of Weather Regimes: The first step of using this generator is identifying weather regimes that bring regional weather to the application area. Weather regimes are large scale atmospheric flow patterns that tend to persist and organize local weather systems and can effectively be modeled by a Markovian process. Weather regimes are often identified by either clustering or fitting a Hidden Markov Model (HMM) to a selected number of principal components of geopotential height (GPH) anomalies. In many of the studies that use this generator in the Western U.S. (Steinschneider et al., 2019, Najibi et al., 2021, Rahat et al., 2022, Gupta et al., (in review), 500 hPa GPH anomalies are used to identify cool season weather regimes because this GPH effectively capture the weather systems organized by the jet stream. The same GPH anomalies also have been used to identify North Atlantic weather regimes that bring weather systems to Europe (Charlton-Perez et al., 2018). A combination of 500 and 250 hPa GPH anomalies have been used to identify weather regimes in Chile (Meseguer-Ruiz et al., 2020), for example. The choice of number of weather regimes is also region specific. In the case of Western US weather regimes, prior work has developed a framework to identify the optimal number of weather regimes that produce the best results in reproducing regional weather statistics over a large geographic area in California (Najibi et al., 2021). In the case of the Western U.S., 4-5 metastable regimes are defined (both in Guirguis et al., 2020 and Najibi et al., 2021), but other regions might be defined by more. Once weather regimes are identified, then they can be simulated as Markov chains, effectively dictating the large-scale atmospheric flow processes that are taking place on a given day.
Simulation of Local Weather: The next step is a bootstrapping procedure to create local weather. Each day of the historical record is classified to be in a specific weather regime and has a certain value of precipitation and temperature associated with each grid cell in the basin of interest. Thus, when chains of weather regimes are simulated, precipitation and temperature can be bootstrapped from the historical record from time periods where simulated blocks of weather regimes match with historical blocks. The block bootstrapping procedure helps maintain the joint distribution of the weather variables, but an additional copula-based jittering technique helps to broaden the range of simulated precipitation outside of the historical distribution while still maintaining the shape of the underlying distribution.
Dynamic and Thermodynamic Perturbations: Dynamic and thermodynamic climate changes are imposed separately in this generator. This allows a way to systematically understand how specific climate changes lead to changes to local climate. Dynamical changes influence how weather regimes evolve and can change the frequency of weather regimes. This can be done by directly changing the transition probabilities of the weather regimes or indirectly by imposing covariates that dictate the evolution of the weather regimes. In Steinschneider et al. (2019), a Niño 3.4 index is used to force weather regime evolution and is systematically adjusted to create more frequent El Niño and La Niña events. In Gupta et al. (in review), a 600-year long sequence of tree-ring reconstructed principal components of weather regime occurrence are used as an alternative covariate to better capture natural variability inherent in the weather regimes. Thermodynamic trends are applied post generation of local weather and consist of manipulations to temperature or precipitation. Stepwise temperature trends can be added to each grid cell, or elevation-dependent warming can be imposed. Based on an imposed temperature, the mean or an upper quantile of the precipitation distribution can be scaled to reflect an increased capacity for the atmosphere to hold moisture due to increased temperature.
Where can I use this generator?
A weather-regime based stochastic weather generator is not applicable everywhere. It can be utilized for any region in which weather regimes dictate regional weather, which are the midlatitude regions of the Earth. Examples of locations where weather regimes are active and have been identified in studies include locations like the Western U.S, the Great lakes region of the U.S., parts of Western Europe, Morocco, Chile, and New Zealand, among others. If a midlatitude location is not applicable to your case study, consider using other synthetic weather generation techniques extensively covered in this series of posts by Julie Quinn. It is worth noting that the quality of the generator is also going to be dependent on having a sufficient historical precipitation and temperature record to bootstrap off of.
Where can I find the code?
Now, for the first time ever, demo code is publicly available in an official GitHub repo. In this demo, created by Nasser, the user can simulate precipitation and temperature for 12 randomly selected grid cells in the Tuolumne River Basin in California. In its most complex form, the generator can be used to generate weather across 12 basins simultaneously in the Central Valley region of California. Download or clone the GitHub repository and then download the necessary data from the Zenodo archive here. Then, drag these data to the Data folder in the repo. Then, the user can proceed with stepping through the rest of the demo.
You will first simulate weather regimes for a certain number of years using either a parametric (config.WRs.param.NHMM.R) or non-parametric method (config.WRs.non_param.R).
Parametric Method: In this method, NHMMs are fitted using the following covariates: the first four PCs of the SPI index over California and two harmonics for the cold season. The two harmonics are the only covariates used during the warm season. From this fitted NHMM, one can simulate an arbitrary sequence of WRs. The parametric method is particularly useful if the user is interested in using specific covariates to force the evolution of the weather regime sequence.
Non-parametric Method: Randomly resample a block of m-years (here, m=4 years) of observed WRs to create a sequence of 1000-yr simulated WRs. Because the non-parametric method doesn’t requires covariates, it is particularly effective for flexibly generating very long sequences of weather regimes that can more appropriate capture natural variability for example.
Once the WRs are simulated, you can simulate local precipitation and temperature. This is done by running the config.simulations.R script.
#Demo code- simulates precipitation and temperature for 12 grid cells in the Tuolumne Basin
rm(list=ls())
library(MASS)
library(fExtremes)
library(evmix)
library(zoo)
library(abind)
library(parallel)
library(mvtnorm)
library(tictoc)
library(lubridate)
#adjust main directory and directory for simulation files
mainDir <- "D:/Projects/Tuolumne_River_Basin/GitHub_WGENv2.0"
setwd(mainDir)
dir.to.sim.files <- "./Data/simulated.data.files/WGEN.out"
dir.create(file.path(mainDir, dir.to.sim.files), showWarnings = FALSE)
num.iter <- 1 # A single long trace (e.g., thousand years) is sufficient although we create like 5 ensembles in the simulated WRs
basin.cnt <- 'myPilot' # for a set of 12 randomly selected Livneh grids in the Tuolumne River Basin
number.years.long <- 3050 # e.g., 500, 1000, 2000, 3000, 5000 years, etc [note: current NHMM output (parametric) is for 1036 years; current non-parametric is for 3050 years]
##############################Define perturbations#######################################
## Climate changes and jitter to apply:
change.list <- data.frame("tc"= c(0), # e.g., 1, 2, ...
"jitter"= c(TRUE),
"pccc"=c( 0), # e.g., 0.07, 0.14, ...
"pmuc"=c( 0)# e.g., -.125
)
# For simulating the WRs (i.e., 'config.WRs.non_param.R'; 'config.WRs.param.NHMM.R'), do you use non-parametric or parametric method
use.non_param.WRs <- TRUE #TRUE for non-parametric, FALSE for parametric simulated WRs
####### Choose A (FALSE) or B (TRUE) below for the simulated WRs #################
#-- A) load in NHMM with WRs (parametric)
tmp.list <- readRDS(paste0("./Data/simulated.data.files/WRs.out/final.NHMM.output.rds"))
weather.state.assignments <- tmp.list$WR.historical # this is for BOTH the parametric and non-parametric approach
sim.weather.state.assignments <- tmp.list$WR.simulation[,1:num.iter] # this is only for the parametric approach of simulating WRs
num.states <- length(unique(as.vector(weather.state.assignments))) #number of WRs in the model
rm(tmp.list) # for memory
#-- B) load in non-parametric simulation with WRs
np.list.sim.weather.state.assignments <- readRDS(paste0("./Data/simulated.data.files/WRs.out/final.non_param.WRs.output.rds")) #this is only for the non-parametric approach of simulating WRs
num.states <- length(unique(np.list.sim.weather.state.assignments$markov.chain.sim[[num.iter]])) #number of WRs in the model
# load in supporting functions
files.sources = list.files("./Programs/functions",full.names = TRUE)
my.functions <- sapply(files.sources, source)
##################################
#dates for the historical WRs
start_date_synoptic="1948-01-01"; end_date_synoptic="2021-12-31"
dates.synoptic <- seq(as.Date(start_date_synoptic),as.Date(end_date_synoptic), by="days")
#create dates for the simulated WRs
my.num.sim = ceiling(number.years.long/length(unique(format(dates.synoptic,'%Y')))) # number of chunks of historical periods; e.g., 1 is one set of simulation equal to the historical
long.dates.sim <- rep(dates.synoptic,times=my.num.sim)
The overarching parameters of the simulation are listed in Lines 14-23 of the code. Here you can adjust paths to directories, how many iterations you want to run (set to “1” currently) and the length of the simulation.
Lines 26-31: These are the thermodynamic climate change parameters. Here you can impose a temperature increase (tc), a precip scaling factor for the upper quantile of the distribution (pccc), and a mean shift to the simulated precipitation distribution (pmuc). Currently, the simulation is set to no imposed climate changes but copula-based jittering is imposed and so is kept as TRUE.
Lines 33-45: Depending on which method was used to simulate the WRs, load in the WRs accordingly, using the blocks of code under either A or B. Be sure to run Line 38 no matter which method was used.
Lines 62-98 contain more details on precipitation characteristics.
#########Precipitation characteristics#########
#location of obs weather data (RData format): weather data (e.g., precip and temp) as matrices (time x lat|lon: t-by-number of grids); dates vector for time; basin average precip (see the example meteohydro file)
processed.data.meteohydro <- paste0("./Data/processed.data.files/processed.meteohydro/processed.meteohydro.myPilot.RData")
load(processed.data.meteohydro) #load in weather data
qq <- .99 # percentile threshold to separate Gamma and GPD distributions
thshd.prcp <- apply(prcp.site,2,function(x) {quantile(x[x!=0],qq,na.rm=T)})
#Bootstrapping choices###
window.size <- rep(3,length(months)) #the size of the window (in days) from which runs can be bootstrapped around the current day of simulation, by month: Jan -- Dec
trace <- 0.25 #trace prcp threshold. 0.25 mm (for Livneh dataset); or 0.01 inches
#The spearman correlation between basin and site precipitation, used in the copula-based jitters
prcp.basin.site <- cbind(prcp.basin,prcp.site)
S <- cor(prcp.basin.site,method="spearman")
n.sites <- dim(prcp.site)[2] # Number of gridded points for precipitation
#fit emission distributions to each site by month. sites along the columns, parameters for month down the rows
emission.fits.site <- fit.emission(prcp.site=prcp.site,
months=months,
months.weather=months.weather,
n.sites=n.sites,
thshd.prcp=thshd.prcp)
#how often is prcp under threshold by month and site
qq.month <- sapply(1:n.sites,function(i,x=prcp.site,m,mm) {
sapply(m,function(m) {
length(which(as.numeric(x[x[,i]!=0 & mm==m & !is.na(x[,i]),i])<=thshd.prcp[i]))/length(as.numeric(x[x[,i]!=0 & mm==m & !is.na(x[,i]),i]))
})},
m=months, mm=months.weather)
thshd.prcp: the threshold precipitation quantile that dictates the separation between extreme precipitation and the rest of the distribution (set at .99). Precipitation scaling is applied to this upper quantile.
trace: the minimum precipitation for which a day is classified as “dry”
window.size: The window around which data is bootstrapped from the historical datasetS: The Spearman rank correlation between individual basin sites and the basin average (for the copula-based jittering)
The fit.emission.R function which fits gamma and GPD distributions to the prcp.site data. A GPD is fit to the precipitation that lies above the thshd.prcp at each site, while the gamma distribution is fit to the rest of the precipitation data by month.
Line 122 is where the bootstrapping process occurs (wgen.simulator.R)
##########################Simulate model with perturbations#######################################
#decide whether or not to use historic or simulated WRs
if(use.non_param.WRs) {
dates.sim <- np.list.sim.weather.state.assignments$dates.sim
markov.chain.sim <- np.list.sim.weather.state.assignments$markov.chain.sim
identical.dates.idx <- dates.synoptic%in%dates.weather
weather.state.assignments <- weather.state.assignments[identical.dates.idx]
} else {
dates.sim <- long.dates.sim
markov.chain.sim <- as.list(data.frame(sim.weather.state.assignments))
}
#run the daily weather generate num.iter times using the num.iter Markov chains
mc.sim <- resampled.date.sim <- resampled.date.loc.sim <- prcp.site.sim <- tmin.site.sim <- tmax.site.sim <- list()
start_time <- Sys.time()
for (k in 1:num.iter) {
my.itertime <- Sys.time()
my.sim <- wgen.simulator(weather.state.assignments=weather.state.assignments,mc.sim=markov.chain.sim[[k]],
prcp.basin=prcp.basin,dates.weather=dates.weather,
first.month=first.month,last.month=last.month,dates.sim=dates.sim,
months=months,window.size=window.size,min.thresh=trace)
print(paste(k,":", Sys.time()-my.itertime))
#each of these is a list of length iter
mc.sim[[k]] <- my.sim[[1]]
resampled.date.sim[[k]] <- my.sim[[2]]
resampled.date.loc.sim[[k]] <- my.sim[[3]]
prcp.site.sim[[k]] <- prcp.site[resampled.date.loc.sim[[k]],]
tmin.site.sim[[k]] <- tmin.site[resampled.date.loc.sim[[k]],]
tmax.site.sim[[k]] <- tmax.site[resampled.date.loc.sim[[k]],]
}
end_time <- Sys.time(); run.time.sim <- end_time - start_time
print(paste("SIMULATION started at:",start_time,", ended at:",end_time)); print(round(run.time.sim,2))
#remove for memory
rm(my.sim)
Once baseline weather is generated, then perturbations can be applied in Line 156 using the perturb.climate.R function. In this function, temperature trends and precipitation scaling is applied if applicable. If not, just the copula-based jittering is applied. This output is then saved for analysis.
#once the simulations are created, we now apply post-process climate changes (and jitters)
for (change in 1:nrow(change.list)) {
start_time <- Sys.time()
cur.tc <- change.list$tc[change]
cur.jitter <- change.list$jitter[change]
cur.pccc <- change.list$pccc[change]
cur.pmuc <- change.list$pmuc[change]
#precipitation scaling (temperature change dependent)
perc.q <- (1 + cur.pccc)^cur.tc #scaling in the upper tail for each month of non-zero prcp
perc.mu <- (1 + cur.pmuc) #scaling in the mean for each month of non-zero prcp
#perturb the climate from the simulations above (the longest procedure in this function is saving the output files)
set.seed(1) #this ensures the copula-based jitterrs are always performed in the same way for each climate change
perturbed.sim <- perturb.climate(prcp.site.sim=prcp.site.sim,
tmin.site.sim=tmin.site.sim,
tmax.site.sim=tmax.site.sim,
emission.fits.site=emission.fits.site,
months=months,dates.sim=dates.sim,n.sites=n.sites,
qq=qq,perc.mu=perc.mu,perc.q=perc.q,S=S,cur.jitter=cur.jitter,cur.tc=cur.tc,
num.iter=num.iter,thshd.prcp=thshd.prcp,qq.month=qq.month)
set.seed(NULL)
prcp.site.sim.perturbed <- perturbed.sim[[1]]
tmin.site.sim.perturbed <- perturbed.sim[[2]]
tmax.site.sim.perturbed <- perturbed.sim[[3]]
#remove for memory
rm(perturbed.sim)
end_time <- Sys.time(); run.time.qmap <- end_time - start_time
print(paste("QMAPPING started at:",start_time,", ended at:",end_time)); print(round(run.time.qmap,2))
#how to name each file name to track perturbations in each set of simulations
file.suffix <- paste0(".temp.",cur.tc,"_p.CC.scale.",cur.pccc,"_p.mu.scale.",cur.pmuc,"_hist.state.",use.non_param.WRs,"_jitter.",cur.jitter,"_s",num.states,"_with_",num.iter,".",basin.cnt)
print(paste("|---start saving---|"))
write.output.large(dir.to.sim.files,
prcp.site.sim=prcp.site.sim.perturbed,
tmin.site.sim=tmin.site.sim.perturbed,
tmax.site.sim=tmax.site.sim.perturbed,
mc.sim=mc.sim,resampled.date.sim=resampled.date.sim,
dates.sim=dates.sim,file.suffix=file.suffix)
print(paste("|---finished saving---|"))
}
#remove for memory
rm(resampled.date.sim,resampled.date.loc.sim,markov.chain.sim,mc.sim)
##################################################################################################
print(paste0("--- done. state= ", num.states," --- ensemble member:",num.iter))
gc()
# The End
#####################################################################################
The R script plot.statistics.full.diagnostics.long.R can then be used to generate a variety of figures that demonstrate the quality of the generator in preserving and/or expanding around the observed statistics of each site. Options include:
Exceedance probability curves for all 12 sites
Simulated vs. observed maximum precipitation for all 12 sites
Simulated vs. observed 1-20 year droughts consolidated across all locations
And much more! Code is provided for 11 different diagnostic assessments of the quality of the generator. Look out for additions to the repository over the next months and feel free to open a GitHub issue if you have questions!
References
Charlton‐Perez, A. J., Ferranti, L., & Lee, R. W. (2018). The influence of the stratospheric state on North Atlantic weather regimes. Quarterly Journal of the Royal Meteorological Society, 144(713), 1140-1151.
Guirguis, K., Gershunov, A., DeFlorio, M.J., Shulgina, T., Delle Monache, L., Subramanian, A.C., Corringham, T.W. and Ralph, F.M., 2020. Four atmospheric circulation regimes over the North Pacific and their relationship to California precipitation on daily to seasonal timescales. Geophysical Research Letters, 47(16), p.e2020GL087609.
Gupta, R.S., Steinschneider S., Reed, P.M. Understanding Contributions of Paleo-Informed Natural Variability and Climate Changes on Hydroclimate Extremes in the Central Valley Region of California. Authorea. March 13, 2023. DOI: 10.22541/essoar.167870424.46495295/v1
Meseguer-Ruiz, O., Cortesi, N., Guijarro, J. A., & Sarricolea, P. (2020). Weather regimes linked to daily precipitation anomalies in Northern Chile. Atmospheric Research, 236, 104802.
Najibi, N., Mukhopadhyay, S., & Steinschneider, S. (2021). Identifying weather regimes for regional‐scale stochastic weather generators. International Journal of Climatology, 41(4), 2456-2479.
Rahat, S. H., Steinschneider, S., Kucharski, J., Arnold, W., Olzewski, J., Walker, W., … & Ray, P. (2022). Characterizing hydrologic vulnerability under nonstationary climate and antecedent conditions using a process-informed stochastic weather generator. Journal of Water Resources Planning and Management, 148(6), 04022028.
Steinschneider, S., Ray, P., Rahat, S. H., & Kucharski, J. (2019). A weather‐regime‐based stochastic weather generator for climate vulnerability assessments of water systems in the western United States. Water Resources Research, 55(8), 6923-6945.









 ,
,  is the generated flow,
is the generated flow,  is the mean historic flow,
is the mean historic flow,  is an autoregression coefficient for predicting that months flow from the prior months flow,
is an autoregression coefficient for predicting that months flow from the prior months flow,  is the standard deviation,
is the standard deviation,  is the correlation coefficient and
is the correlation coefficient and  is a random standard normal variable.
is a random standard normal variable. as the observed flows in month
as the observed flows in month 
 is the estimated “lower bound” for each month, calculated as:
is the estimated “lower bound” for each month, calculated as:

 is the observed average historic monthly
is the observed average historic monthly  series
series is the observed variance of the historic monthly
is the observed variance of the historic monthly  independent standard-normal random variables
independent standard-normal random variables observed between-month correlations of the historic
observed between-month correlations of the historic 






 -stages is an extension of the two-stage SP problem, where the decision at stage
-stages is an extension of the two-stage SP problem, where the decision at stage 
 is the infrastructure net present cost,
is the infrastructure net present cost,  is bond term for an infrastructure option, and is the discount rate for a given year
is bond term for an infrastructure option, and is the discount rate for a given year  of debt service payment
of debt service payment 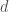 for an infrastructure option since its bond was issued. The value of
for an infrastructure option since its bond was issued. The value of  is calculated as follows:
is calculated as follows:![\frac{P[BR(1+BR)^T]}{(1+BR)^{T}-1}](https://s0.wp.com/latex.php?latex=%5Cfrac%7BP%5BBR%281%2BBR%29%5ET%5D%7D%7B%281%2BBR%29%5E%7BT%7D-1%7D&bg=ffffff&fg=444444&s=0&c=20201002)
 is the bond principal (the total value of the bond),
is the bond principal (the total value of the bond),  is the bond interest rate to be paid to the creditor throughout the bond term
is the bond interest rate to be paid to the creditor throughout the bond term  . All payments are discounted to their present value. The value of the bond principal is dependent on the capacity of the infrastructure option and is calculated as a function of the fixed and variable capital costs:
. All payments are discounted to their present value. The value of the bond principal is dependent on the capacity of the infrastructure option and is calculated as a function of the fixed and variable capital costs:
 is the capital cost of infrastructure option
is the capital cost of infrastructure option  and
and 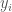 is a binary
is a binary  variable indicating if option
variable indicating if option  is the variable capital cost of infrastructure option
is the variable capital cost of infrastructure option  is the final built capacity of
is the final built capacity of  , calculated as follows:
, calculated as follows:![R_{s,i}=[(D_{s,i}\times UR \times \text{households})(1-\rho_{i})] - OC_{s,i}](https://s0.wp.com/latex.php?latex=R_%7Bs%2Ci%7D%3D%5B%28D_%7Bs%2Ci%7D%5Ctimes+UR+%5Ctimes+%5Ctext%7Bhouseholds%7D%29%281-%5Crho_%7Bi%7D%29%5D+-+OC_%7Bs%2Ci%7D&bg=ffffff&fg=444444&s=0&c=20201002)
 is per-capita daily water delivered,
is per-capita daily water delivered,  is the per-household uniform water rate, and
is the per-household uniform water rate, and  is the percentage of water lost during transmission given that infrastructure
is the percentage of water lost during transmission given that infrastructure  is Helm’s Keep’s daily operating costs per capita where
is Helm’s Keep’s daily operating costs per capita where
 is the variable operating cost of
is the variable operating cost of  is the percentage of NRW.
is the percentage of NRW. should not exceed 1.25 times that of Helm’s Keep’s annual net revenue
should not exceed 1.25 times that of Helm’s Keep’s annual net revenue  of water demand increase
of water demand increase  , Federal Reserve bond interest rate, and discount rate. The probability of each scenario is listed in the table below:
, Federal Reserve bond interest rate, and discount rate. The probability of each scenario is listed in the table below: ?
? and
and ![y_i \in {0,1} \forall i=[1,2,3]](https://s0.wp.com/latex.php?latex=y_i+%5Cin+%7B0%2C1%7D+%5Cforall+i%3D%5B1%2C2%2C3%5D&bg=ffffff&fg=444444&s=0&c=20201002)

 ,
,  and
and  be the amount of water delivered, bond rate, and discount rate, in scenario
be the amount of water delivered, bond rate, and discount rate, in scenario 
![PMT_{s,i}=(C_i y_i + VCC_i x_i) \frac{[BR_{s,i}(1+BR_{s,i})^{30}]}{(1+BR_{s,i})^{30} -1}](https://s0.wp.com/latex.php?latex=PMT_%7Bs%2Ci%7D%3D%28C_i+y_i+%2B+VCC_i+x_i%29+%5Cfrac%7B%5BBR_%7Bs%2Ci%7D%281%2BBR_%7Bs%2Ci%7D%29%5E%7B30%7D%5D%7D%7B%281%2BBR_%7Bs%2Ci%7D%29%5E%7B30%7D+-1%7D&bg=ffffff&fg=444444&s=0&c=20201002)





![R_{s,i} = [(3420D_{s,i})(1-\rho_i)] - (VOC_i\frac{D_{s,i}}{\rho_s})](https://s0.wp.com/latex.php?latex=R_%7Bs%2Ci%7D+%3D+%5B%283420D_%7Bs%2Ci%7D%29%281-%5Crho_i%29%5D+-+%28VOC_i%5Cfrac%7BD_%7Bs%2Ci%7D%7D%7B%5Crho_s%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)
 is the probability of scenario
is the probability of scenario  .
.




















