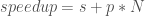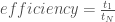We have recently begun introducing multi-objective evolutionary algorithms (MOEAs) to a few new additions to our research group, and it reminded me of when I began learning the relevant terminology myself barely a year ago. I recalled using Antonia’s glossary of commonly-used terms as I was getting acquainted with the group’s research in general, and figured that it might be helpful to do something similar for MOEAs in particular.
This glossary provides definitions and examples in plain language for terms commonly used to explain and describe MOEAs, and is intended for those who are just being introduced to this optimization tool. It also has a specific focus on the Borg MOEA, which is a class of algorithms used in our group. It is by no means exhaustive, and since the definitions are in plain language, please do leave a comment if I have left anything out or if the definitions and examples could be better written.
Greek symbols
ε-box
Divides up the objective space into n-dimensional boxes with side length ε. Used as a “filter” to prevent too many solutions from being “kept” by the archive. The smaller the size of the ε-box, the finer the “mesh” of the filter, and the more solutions are kept by the archive. Manipulating the value of ε affects convergence and diversity.
Each ε-box can only hold one solution at a time. If two solutions are found that reside in the same ε-box, the solution closest to the lower left corner of the box will be kept, while the other will be eliminated.
ε-dominance
A derivative of Pareto dominance. A solution x is said to ε-dominate solution y if it lies in the lower left corner of an ε-box for at least one objective, and is not ε-dominated by solution y for all other objectives.
ε-progress
ε-progress occurs when the current solution x lies in an different ε-box that dominates the previous solution. Enforces a minimum threshold ( ε ) over which an MOEA’s solution must exceed to avoid search stagnation.
ε-value
The “resolution” of the problem. Can also be interpreted a measure of the degree of error tolerance of the decision-maker. The ε-values can be set according to the discretion of the decision-maker.
A
A posteriori
Derived from Latin for “from the latter”. Typically used in multi-objective optimization to indicate that the search for solutions precedes the decision-making process. Exploration of the trade-offs resulting from different potential solutions generated by the MOEA is used to identify preferred solutions. Used when uncertainties and preferences are not known beforehand.
A priori
Derived from Latin for “from the former”. Typically used in multi-objective optimization to indicate that a set of potential solutions have already been decided beforehand, and that the function of a search is to identify the best solution(s). Used when uncertainties and preferences are known (well-characterized).
Additive ε-indicator
The distance that the known Pareto front must “move” to dominate the true Pareto front. In other words, the gap between the current set of solutions and the true (optimal) solutions. A performance measure of MOEAs that captures convergence. Further explanation can be found here.
Archive
A “secondary population” that stores the non-dominated solutions. Borg utilizes ε-values to bound the size of the archive (an ε-box dominance archive) . That is, solutions that are ε-dominated are eliminated. This helps to avoid deterioration.
C
Conditional dependencies
Decision variables are conditionally dependent on each other if the value of one decision variable affects one or more if its counterparts.
Control maps
Figures that show the hypervolume achieved in relation to the number of objective function evaluations (NFEs) against the population size for a particular problem. Demonstrates the ability of an MOEA to achieve convergence and maintain diversity for a given NFE and population size. An ideal MOEA will be able to achieve a high hypervolume for any given NFE and population size.
Controllability
An MOEA with a high degree of controllability is one that results in fast convergence rates, high levels of diversity, and a large hypervolume regardless of the parameterization of the MOEA itself. That is, a controllable MOEA is insensitive to its parameters.
Convergence
Two definitions:
- An MOEA is said to have “converged” at a solution when the subsequent solutions are no better than the previous set of solutions. That is, you have arrived at the best set of solutions that can possibly be attained.
- The known Pareto front of the MOEA is approximately the same as the true Pareto front. This definition requires that the true Pareto front be known.
D
Decision variables
Variables that can be adjusted and set by the decision-maker.
Deterioration
Occurs when elements of the current solution are dominated by a previous set of solutions within the archive. This indicates that the MOEA’s ability to find new solutions is diminishing.
Diversity
The “spread” of solutions throughout the objective space. An MOEA is said to be able to maintain diversity if it is able to find many solutions that are evenly spread throughout the objective space.
Dominance resistance
A phenomenon in which an MOEA struggles to produce offspring that dominate non-dominated members of the population. That is, the current set of solutions are no better than the worst-performing solutions of the previous set. An indicator of stagnation.
E
Elitist selection
Refers to the retention of a select number of ‘best’ solutions in the previous population, and filling in the slots of the current generation with a random selection of solutions from the archive. For example, the Borg MOEA utilizes elitist selection during the randomized restarts when the best k-solutions from the previous generation are maintained in the population.
Epistasis
Describes the interactions between the different operators used in Borg MOEA. Refers to the phenomenon in which the heavier applications of one operator suppresses the use of other operators, but does not entirely eliminate the use of the lesser-used operators. Helps with finding new solutions. Encourages diversity and prevents pre-convergence.
G
Generation
A set of solutions generated from one iteration of the MOEA. Consists of both dominated and non-dominated solutions.
Generational
Generational MOEAs apply the selection, crossover and mutation operators all at once to an entire generation of the population. The result is a complete replacement of the entire generation at the next time-step.
Generational distance
The average distance between the known Pareto front and the true Pareto front. The easiest performance metric to meet, and captures convergence of the solutions. Further explanation can be found here.
Genetic algorithm
An algorithm that uses the principles of evolution – selection, mutation and crossover – to search for solutions to a problem given a starting point, or “seed”.
H
Hypervolume
The n-dimensional “volume” covered by the known Pareto front with respect to the total n-dimensional volume of all the objectives of a problem, bounded by a reference point. Captures both convergence and diversity. One of the performance measures of an MOEA. Further explanation can be found here.
I
Injection
The act of “refilling” the population with members of the archive after a restart. Injection can also include filling the remaining slots in the current population with new, randomly-generated solutions or mutated solutions. This helps to maintain diversity and prevent pre-convergence.
L
Latin hypercube sampling (LHS)
A statistical method of sampling random numbers in a way that reflects the true underlying probability distribution of the data. Useful for high-dimensional problems such as those faced in many-objective optimization. More information on this topic can be found here.
M
Many-objective problem
An optimization problem that involves more than three objectives.
Mutation
One of the three operators used in MOEAs. Mutation occurs when a solution from the previous population is slightly perturbed before being injected into the next generation’s population. Helps with maintaining diversity of solutions.
Multi-objective
An optimization problem that traditionally involves two to three objectives.
N
NFE
Number of function evaluations. The maximum number of times an MOEA is applied to and used to update a multi (or many)-objective problem.
O
Objective space
The n-dimensional space defined by the number, n, of objectives as stated by the decision-maker. Can be thought of as the number of axes on an n-dimensional graph.
Offspring
The result of selection, mutation, or crossover in the current generation. The new solutions that, if non-dominated, will be used to replace existing members in the current generation’s population.
Operator
Genetic algorithms typically use the following operators – selection, crossover, and mutation operators. These operators introduce variation in the current generation to produce new, evolved offspring. These operators are what enable MOEAs to search for solutions using random initial solutions with little to no information.
P
Parameters
Initial conditions for a given MOEA. Examples of parameters include population-to-archive ratio, initial population size, and selection ratio.
Parameterization
An MOEA with a high degree of parameterization implies that it requires highly-specific parameter values to generate highly-diverse solutions at a fast convergence rate.
Parents
Members of the current generation’s population that will undergo selection, mutation, and/or crossover to generate offspring.
Pareto-dominance
A solution x is said to Pareto-dominate another solution y if x performs better than y in at least one objective, and performs at least as well as y in all other objectives.
Pareto-nondominance
Both solutions x and y are said to be non-dominating if neither Pareto-dominates the other. That is, there is at least one objective in which solution x that is dominated by solution y and vice versa.
Pareto front
A set of solutions (the Pareto-optimal set) that are non-dominant to each other, but dominate other solutions in the objective space. Also known as the tradeoff surface.
Pareto-optimality
A set of solutions is said to have achieved Pareto-optimality when all the solutions within the same set non-dominate each other, but are dominant to other solutions within the same objective space. Not to be confused with the final, “optimal” set of solutions.
Population
A current set of solutions generated by one evaluation of the problem by an MOEA. Populated by both inferior and Pareto-optimal solutions; can be static or adaptive. The Borg MOEA utilizes adaptive population sizing, of which the size of the population is adjusted to remain proportional to the size of the archive. This prevents search stagnation and the potential elimination of useful solutions.
Pre-convergence
The phenomenon in which an MOEA mistakenly converges to a local optima and stagnates. This may lead the decision-maker to falsely conclude that the “best” solution set has been found.
R
Recombination
One of the ways that a mutation operator acts upon a given solution. Can be thought of as ‘shuffling’ the current solution to produce a new solution.
Rotation
Applying a transformation to change the orientation of the matrix (or vector) of decision variables. Taking the transpose of a vector can be thought of as a form of rotation.
Rotationally invariant
MOEAs that utilize rotationally invariant operators are able to generate solutions for problems and do not require that the problem’s decision variables be independent.
S
Search stagnation
Search stagnation is said to have occurred if the set of current solutions do not ε-dominate the previous set of solutions. Detected by the ε-progress indicator (ref).
Selection
One of the three operators used in MOEAs. The selection operator chooses the ‘best’ solutions from the current generation of the population to be maintained and used in the next generation. Helps with convergence to a set of optimal solutions.
Selection pressure
A measure of how ‘competitive’ the current population is. The larger the population and the larger the tournament size, the higher the selection pressure.
Steady-state
A steady-state MOEA applies its operators to single members of its population at a time. That is, at each step, a single individual (solution) is selected as a parent to be mutated/crossed-over to generate an offspring. Each generation is changed one solution at each time-step.
T
Time continuation
A method in which the population is periodically ’emptied’ and repopulated with the best solutions retained in the archive. For example, Borg employs time continuation during its randomized restarts when it generates a new population with the best solutions stored in the archive and fills the remaining slots with randomly-generated or mutated solutions.
Tournament size
The number of solutions to be ‘pitted against each other’ for crossover or mutation. The higher the tournament size, the more solutions are forced to compete to be selected as parents to generate new offspring for the next generation.
References
Coello, C. C. A., Lamont, G. B., & Van, V. D. A. (2007). Evolutionary Algorithms for Solving Multi-Objective Problems Second Edition. Springer.
Hadjimichael, A. (2017, August 18). Glossary of commonly used terms. Water Programming: A Collaborative Research Blog. https://waterprogramming.wordpress.com/2017/08/11/glossary-of-commonly-used-terms/.
Hadka, D., & Reed, P. (2013). Borg: An Auto-Adaptive Many-Objective Evolutionary Computing Framework. Evolutionary Computation, 21(2), 231–259. https://doi.org/10.1162/evco_a_00075
Kasprzyk, J. R. (2013, June 25). MOEA Performance Metrics. Water Programming: A Collaborative Research Blog. https://waterprogramming.wordpress.com/2013/06/25/moea-performance-metrics/.
Li, M. (n.d.). Many-Objective Optimisation. https://www.cs.bham.ac.uk/~limx/MaOP.html.
What is Latin Hypercube Sampling? Statology. (2021, May 10). https://www.statology.org/latin-hypercube-sampling/.