
This post will introduce basic concepts regarding the parallelization of the Borg Multiobjective Evolutionary Algorithm (Borg MOEA). In this post I’ll assume the reader is familiar with the basic architecture of the Borg MOEA, if you’re unfamiliar with the algorithm or would like a refresher, see Hadka and Reed, (2013a) before reading further.
Parallelization Basics
Before we go into parallization of Borg, let’s quickly define some terminology. Modern High Performance Computing (HPC) resources are usually comprised of many multi-core processors, each consisting of two or more processing cores. For this post, I’ll refer to an individual processing core as a “processor”. Parallel computing refers to programs that utilize multiple processors to simultaneously perform operations that would otherwise be performed in serial on a single processor.
Parallel computing can be accomplished using either “distributed” or “shared” memory methods. Shared memory methods consist of parallelizing tasks across a group of processors that all read and write from the same memory space. In distributed memory parallelization, each processor maintains its own private memory and data is usually passed between processors using a message passing interface (MPI) library. Parallel Borg applications are coded using distributed memory parallelization, though it’s important to note that it’s possible to parallelize the simulation model that is coupled with Borg using shared memory parallelization. For additional reading on parallelization concepts see Bernardo’s post from April and Barney’s posts from 2017.
Hadka et al., (2012) showed that the quality of search results discovered by the Borg MOEA is strongly dependent on the number of function evaluations (NFE) performed in an optimization run. Efficient parallelization of search on HPC resources can allow not only for the search to be performed “faster” but also may allow more NFE to be run, potentially improving the quality of the final approximation of the Pareto front. Parallelization also offers opportunities to improve the search dynamics of the MOEA, improving the reliability and efficiency of multi-objective search (Hadka and Reed, 2015; Salazar et al., 2017).
Below I’ll discuss two parallel implementations of the Borg MOEA, a simple master-worker implementation to parallelize function evaluations across multiple processors and an advanced hybrid multi-population implementation that improves search dynamics and is scalable Petascale HPC resources.
Master-worker Borg
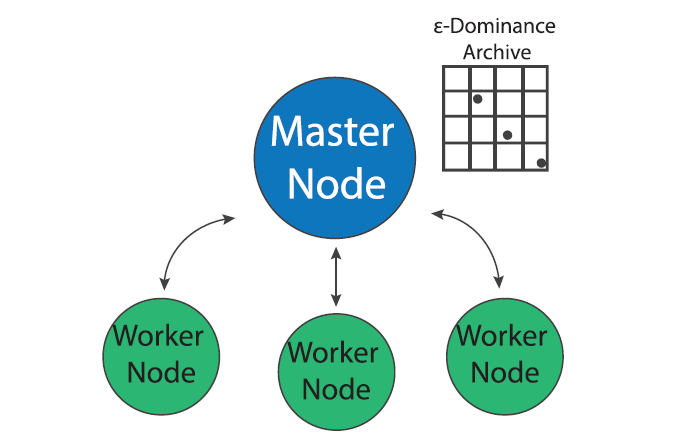
MOEA search is “embarrassingly parallel” since the evaluation of each candidate solution can be done independently of other solutions in a population (Cantu-Paz, 2000). The master-worker paradigm of MOEA parallelization, which has been in use since early days of evolutionary algorithms (Grefenstette, 1981), utilizes this property to parallelize search. In the master worker implementation of Borg in a system of P processors, one processor is designated as the “master” and P-1 processors are designated as “workers”. The master processor runs the serial version of the Borg MOEA but instead of evaluating candidate solution, it sends the decision variables to an available worker which evaluates the problem with the given decision variables and sends the evaluated objectives and constraints back to the master processor.
Most MOEAs are generational, meaning that they evolve a population in distinct stages known as generations (Coello Coello et al., 2007). During one generation, the algorithm evolves the population to produce offspring, evaluates the offspring and then adds them back into the population (methods for replacement of existing members vary according to the MOEA). When run in parallel, generational MOEAs must evaluate every solution in a generation before beginning evaluation of the next generation. Since these algorithms need to synchronize function evaluations within a generation, they are known as synchronous MOEAs. Figure 2, from Hadka et al., (2013b), shows a timeline of events for a typical synchronous MOEA. Algorithmic time (TA) represents the time it takes the master processor to perform the serial components of the MOEA. Function evaluation time (TF) is the the time it takes to evaluate one offspring and communication time (TC) is the time it takes to pass information to and from worker nodes. The vertical dotted lines in Figure 2 represent the start of each new generation. Note the periods of idle time that each worker node experiences while it waits for the algorithm to perform serial calculations and communicate. If the function evaluation time is not constant across all nodes, this idle time can increase as the algorithm waits for all solutions in the generation to be evaluated.

The Borg MOEA is not generational but rather a steady-state algorithm. As soon as an offspring is evaluated by a worker and returned to the master, the next offspring is immediately sent to the worker for evaluation. This is accomplished through use of a queue, for details of Borg’s queuing process see Hadka and Reed, (2015). Since Borg is not bound by the need to synchronize function evaluations within generations, it is known as an asynchronous MOEA. Figure 3, from Hadka et al., (2013b), shows a timeline of a events for a typical Borg run. Note that the idle time has been shifted from the workers to the master processor. When the algorithm is parallelized across a large number of cores, the decreased idle time for each worker has the potential to greatly increase the algorithm’s parallel efficiency. Furthermore, if function evaluation times are heterogeneous, the algorithm is not bottlenecked by slow evaluations as generational MOEAs are.

While the master-worker implementation of the Borg MOEA is an efficient means of parallelizing function evaluations, the search algorithm’s search dynamics remain the same as the serial version and as the number of processors increases, the search may suffer from communication bottlenecks. The multi-master implementation of the Borg MOEA uses parallelization to not only improve the efficiency of function evaluations but also improve the quality of the multi-objective search.
Multi-Master Borg
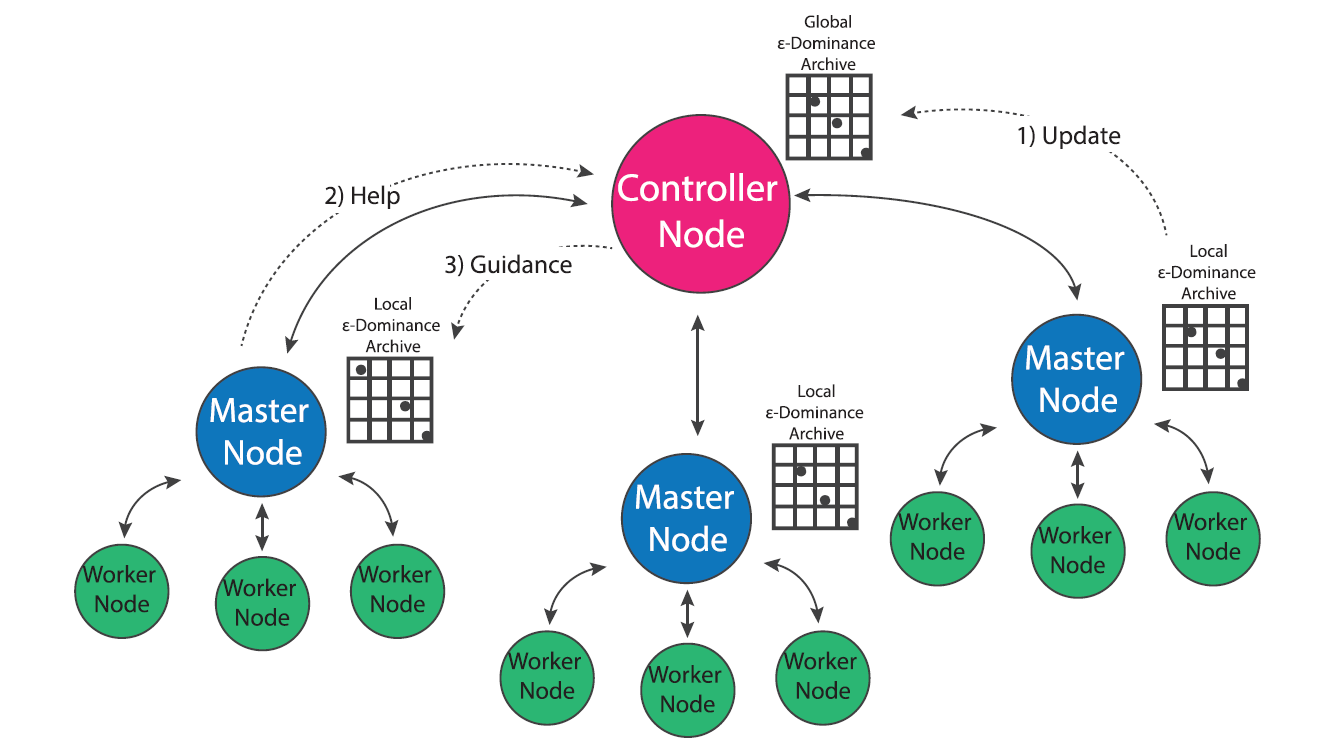
In population genetics, the “island model” considers distinct populations that evolve independently but periodically interbreed via migration events that occur over the course of the evolutionary process (Cantu-Paz, 2000). Two independent populations may evolve very different survival strategies based on the conditions of their environment (i.e. locally optimal strategies). Offspring of migration events that combine two distinct populations have the potential to combine the strengths developed by both groups. This concept has been utilized in the development of multi-population evolutionary algorithms (also called multi-deme algorithms in literature) that evolve multiple populations in parallel and occasionally exchange individuals via migration events (Cantu-Paz, 2000). Since MOEAs are inherently stochastic algorithms that are influenced by their initial populations, evolving multiple populations in parallel has the potential to improve the efficiency, quality and reliability of search results (Hadka and Reed, 2015; Salazar et al., 2017). Hybrid parallelization schemes that utilize multiple versions of master-worker MOEAs may further improve the efficiency of multi-population search (Cantu-Paz, 2000). However, the use of a multi-population MOEA requires the specification of parameters such as the number of islands, number of processors per island and migration policy that whose ideal values are not apparent prior to search.
The multi-master implementation of the Borg MOEA is a hybrid parallelization of the MOEA that seeks to generalize the algorithm’s ease of use and auto-adaptivity while maximizing its parallel efficiency on HPC architectures (Hadka and Reed, 2015). In the multi-master implementation, multiple versions of the master-worker MOEA are run in parallel, and an additional processor is designated as the “controller”. Each master maintains its own epsilon dominance archive and operator probabilities, but regulatory updates its progress with the controller which maintains a global epsilon dominance archive and global operator probabilities. If a master processor detects search stagnation that it is not able to overcome via Borg’s automatic restarts, it requests guidance from the controller node which seeds the master with the contents of the global epsilon dominance archive and operator probabilities. This guidance system insures that migration events between populations only occurs when one population is struggling and only consists of globally non-dominated solutions. Borg’s adaptive population sizing ensures the injected population is resized appropriately given the global search state.
The use of multiple-populations presents an opportunity for the algorithm to improve the sampling of the initial population. The serial and master-worker implementations of Borg generate the initial population by sampling decision variables uniformly at random from their bounds, which has the potential to introduce random bias into the initial search population (Hadka and Reed, 2015). In the multi-master implementation of Borg, the controller node first generates a latin hypercube sample of the decision variables, then distributes these samples between masters uniformly at random. This initial sampling strategy adds some additional overhead to the algorithm’s startup, but ensures that globally the algorithm starts with a well-distributed, diverse set of initial solutions which can help avoid preconvergence (Hadka and Reed, 2015).
Conclusion
This post has reviewed two parallel implementations of the Borg MOEA. The next post in this series will discuss how to evaluate parallel performance of a MOEA in terms of search efficiency, quality and reliability. I’ll review recent literature comparing performance of master-worker and multi-master Borg and discuss how to determine which implementation is appropriate for a given problem.
References
Cantu-Paz, E. (2000). Efficient and accurate parallel genetic algorithms (Vol. 1). Springer Science & Business Media.
Hadka, D., Reed, P. M., & Simpson, T. W. (2012). Diagnostic assessment of the Borg MOEA for many-objective product family design problems. 2012 IEEE Congress on Evolutionary Computation (pp. 1-10). IEEE.
Hadka, D., & Reed, P. (2013a). Borg: An auto-adaptive many-objective evolutionary computing framework. Evolutionary computation, 21(2), 231-259.
Hadka, D., Madduri, K., & Reed, P. (2013b). Scalability analysis of the asynchronous, master-slave borg multiobjective evolutionary algorithm. In 2013 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (pp. 425-434). IEEE.
Hadka, D., & Reed, P. (2015). Large-scale parallelization of the Borg multiobjective evolutionary algorithm to enhance the management of complex environmental systems. Environmental Modelling & Software, 69, 353-369.
Salazar, J. Z., Reed, P. M., Quinn, J. D., Giuliani, M., & Castelletti, A. (2017). Balancing exploration, uncertainty and computational demands in many objective reservoir optimization. Advances in water resources, 109, 196-210.









