
Regression is the primary tool used in econometrics to infer relationships between a group of explanatory variables, X and a dependent variable, y. My previous post focused on the mechanics of Ordinary Least Squares (OLS) Regression and outlined key assumptions that, if true, make OLS estimates the Best Linear Unbiased Estimator (BLUE) for the coefficients in the regression:
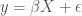
This post will discuss three common violations of OLS assumptions, and explain tools that have been developed for dealing with these violations. We’ll start with a violation of the assumption of a linear relationship between X and y, then discuss heteroskedasticity in the error terms and the issue of endogeniety.
Linearity
If the relationship between X and y is not linear, OLS can no longer be used to estimate beta. A nonlinear regression of y on X has the form:

Where g(X\beta) is the functional form of the nonlinear relationship between X and y and epsilon is the error term. Beta can be estimated using Nonlinear Least Squares regression (NLS). Similar to OLS regression, NLS seeks to minimize the sum of the square error term.
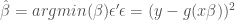
To solve for beta, we again take the derivative and set it equal to zero, but for the nonlinear system there is no closed form solution, so the estimators have to be found using numerical optimization techniques.
The variance of a NLS estimator is:

Where G is a matrix of partial derivatives of g with respect to each Beta.
Modern numerical optimization techniques can solve many NLS equations quite easily making NLS a common alternative to OLS regression especially when there is a hypothesized functional form for the relationship between X and y.
Heteroskedasticity
Heteroskedasticity arises within a data set when the errors do not have a constant variance with respect to X. In equation form, under heteroskedasticity:
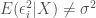
The presence of heteroskedasticity increases the variance of Beta estimators found using OLS regression, reducing the efficiency of the estimator and causing it to no longer be the BLUE. As put by Allison (2012), OLS on heteroskedastic data puts “equal weight on all observations when, in fact, observations with larger disturbances contain less information”.
To fix this problem, econometric literature provides two options which both use a form of weighting to correct for differences in variance amongst the error terms:
- Use the OLS estimate for beta, but calculate the variance of beta with a robust variance-covariance matrix .
- Estimate Beta using Feasible Generalized Least Squares (FGLS)
Let’s begin with the first strategy, using OLS beta estimates with a robust variance-covariance matrix. The robust variance-covariance matrix can be derived using the Generalized Method of Moments (GMM) for the sake of brevity, I’ll omit the derivation here and skip to the final result:
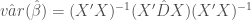
Where 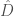

The second strategy, estimation using FGLS, requires a more involved process for estimating beta. FGLS can be accomplished through 3 steps:
- Use OLS to find OLS estimate for beta and calculate the residuals:

2. Regress the error term on a subset of X, which we will call Z, to get an estimate of a new parameter, theta (denoted with a tilde, but wordpress makes it difficult for me to add this in the middle of a paragraph). We then use this parameter to estimate the variance of the error term, sigma squared, for each observation:

A diagonal matrix, D (different than the D used for the robust variance-covariance matrix), is then constructed using these variance estimates.
3. Finally, we use the matrix D to find our FGLS estimator for beta:

The variance of of the FGLS beta etimate is then defined as:

Endogeneity
Endogeneity arises when explanatory variables are correlated with the error term in a regression. This may be a result of simultaneity, when errors and explanatory variables are effected by the same exogenous influences, omitted variable bias, when an important variable is left out of a regression, causing the over- or underestimation of the effect of other explanatory variables and the error term, measurement error or a lag in the dependent variable. Endogeniety can be hard to detect and may cause regression large errors in regression results.
A common way of correcting for endogeniety is through Instrumental Variables (IVs). Instrumental variables are explanatory variables that are highly correlated with variables that cause endogeniety but are exogenous to the system. Examples include using proximity to cardiac care centers as an IV for heart surgery when modeling health or state cigarette taxes as an IV for maternal smoking rate when modeling infant birth weight (Angrist and Kruger, 2001). For an expansive but accessible overview of IVs and their many applications, see Angrist and Kruger (2001).
A common technique for conducting a regression using IVs is 2 Stage Least Squares (2SLS) regression. The two stages of 2SLS are as follows:
- Define Z as a new set of explanatory variables, which omits the endogenous variables and includes the IVs (which are usually not included in the original OLS regression).
- Project Z onto the column space of X.
- Estimate the 2SLS using this projection:
![\hat{\beta}_{2SLS} = [X'Z(Z'Z)^{-1}Z'X]^{-1}[X'Z(Z'Z)^{-1}Z'y]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Cbeta%7D_%7B2SLS%7D+%3D+%5BX%27Z%28Z%27Z%29%5E%7B-1%7DZ%27X%5D%5E%7B-1%7D%5BX%27Z%28Z%27Z%29%5E%7B-1%7DZ%27y%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Using 2SLS regression to correct for endogeneity is fairly simple, however identifying good IVs for an endogenous variable can be extremely difficult. Finding a good IV (or set of IVs) can be enough to get one published in an economics journal (at least that’s what my economist friend told me).
Concluding thoughts
These two posts have constituted an extremely brief introduction to the field of econometrics meant for engineers who may be interested in learning about common empirical tools employed by economists. We covered the above methods in much more detail in class and also covered other topics such as panel data, Generalize Method Of Moments estimation, Maximum Likelihood Estimation, systems of equations in regression and discrete choice modeling. Overall, I found the course (AEM 7100) to be a useful introduction to a field that I hope to learn more about over the course of my PhD.
References:
Allison, Paul D. (2012). “Multiple regression: a primer“. Pine Forge. Thousand Oaks, CA: Press Print.
Angrist, J.; Krueger, A. (2001). “Instrumental Variables and the Search for Identification: From Supply and Demand to Natural Experiments”. Journal of Economic Perspectives. 15 (4): 69–85. doi:10.1257/jep.15.4.69.



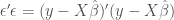



 , is the orthogonal distance between y and
, is the orthogonal distance between y and 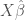 . (Image source: Wikipedia commons)
. (Image source: Wikipedia commons) terms should be independent of the value of the explanatory variables, X. Put in equation form, this assumption requires:
terms should be independent of the value of the explanatory variables, X. Put in equation form, this assumption requires:


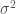 is a constant value.
is a constant value.
 as:
as:
