
In this post on the Water Programming Blog, we continue to explore the application of the stochastic weather generator (available on GitHub) for climate-change scenario developments. This is the second installment of a two-part series of blog posts, and readers are strongly encouraged to familiarize themselves with different components of the stochastic weather generator, as explained in Part 1 by Rohini Gupta (The Reed Research Group).
Here, we will begin by offering a concise overview of developing climate change scenarios and how these scenarios are integrated into the weather generation model. Following this, we will proceed to interpret the impact of these climatic change conditions on key statistical insights concerning occurrences of floods and droughts. Through these examples, the implications of these climatic shifts on water resources management and flood risk analysis will become evident.
Climate Change Perturbations
In this stochastic weather generator, we specifically focus on two aspects of climate change scenario developments, including 1) thermodynamic and 2) dynamic perturbations.
1) Thermodynamic Change
Thermodynamic climate change, often referred to as temperature-driven change, is primarily driven by changes in the Earth’s energy balance and temperature distribution. This warming affects various aspects of the climate system, such as intensifying precipitation extremes, melting snowpacks and ice sheets, rising sea levels, altered weather patterns, and shifts in ecosystems. The primary driver of temperature-driven climate change is the increase in regional-to-global average temperatures due to the enhanced greenhouse effect. As temperatures rise due to natural and anthropogenic forcings, they trigger a cascade of interconnected impacts throughout the climate system.
In the stochastic weather generator, scenarios of temperature change are treated simply by adding trends to simulated temperature data for each location across the spatial domain. However, scenarios of thermodynamic precipitation intensification are modeled using a quantile mapping technique through scaling the distribution of daily precipitation in a way that replicates the effects of warming temperatures on precipitation as the moisture holding capacity of the atmosphere increases. In the context of California, previous studies have demonstrated that as temperatures rise, the most severe precipitation events (often associated with Atmospheric Rivers landfalling) are projected to increase in frequency, while the intensity of smaller precipitation events is expected to decrease (Gershunov et al., 2019). This alteration effectively stretches the distribution of daily precipitation, causing extreme events to become more pronounced while reducing the occurrence and strength of lighter precipitation events. We replicate this phenomenon by making adjustments to the statistical characteristics and distribution percentiles of precipitation (e.g., Pendergrass and Hartmann, 2014). To further elaborate on this, we select a scaling factor for the 99th percentile of nonzero precipitation and then modify the gamma-GPD mixed distribution to enforce this chosen scaling factor. For instance, in a scenario with a 3°C temperature warming and a 7% increase in extreme precipitation per °C (matching the theoretical Clausius-Clapeyron rate of increase in atmospheric water holding capacity due to warming; Najibi and Steinschneider (2023)), the most extreme precipitation events are projected to increase by approximately 22.5% (1.073). We adjust the gamma-GPD models fitted to all locations to ensure this percentage increase in the upper tail of the distribution. Assuming that mean precipitation remains constant at baseline levels, this adjustment will cause smaller precipitation values in the gamma-GPD model to decrease, compensating for the increase in extreme events through stretching the distribution of nonzero precipitation.
Lines 33-40 from ‘config.simulations.R’ show the user-defined changes to implement the thermodynamic scenarios based on temperature in Celsius (tc: e.g. 1 °C), percent change in extreme precipitation quantile (pccc: e.g. 7% per °C), and percent change in average precipitation (pmuc: e.g. 12.5% decrease) inputs. Needless to say that the stochastic weather generator runs at baseline mode if tc=0 and pmuc=0.
##-------------Define perturbations-------------##
##climate changes and jitter to apply:
change.list <- data.frame("tc"= c(0), # {e.g., 0, 1, 2, ...} (changes in temperature)
"jitter"= c(TRUE),
"pccc"= c( 0.00), # {e.g., 0, 0.07, 0.14, ...} (changes for precipitation extreme quantile -- CC)
"pmuc"= c( 0.00)# {e.g., 0, -.125, .125, ...} (changes in precipitation mean)
)
##----------------------------------------------##
2) Dynamic Change
Dynamic climate change, also known as circulation-driven change, is driven by shifts in atmospheric and oceanic circulation patterns. These circulation patterns are influenced by a variety of factors, including temperature gradients, differences in air pressure, and Earth’s rotation. Changes in these patterns can lead to alterations in weather patterns, precipitation distribution, and regional climate characteristics. One well-known example of dynamic climate change is the phenomenon of El Niño and La Niña, which involve changes in ocean temperatures and atmospheric pressure in the Pacific Ocean. These events can significantly impact local-to-global weather patterns, causing droughts, heavy rainfall, and other extreme weather events (Pfahl et al., 2017).
Dynamic changes impact the evolution of weather patterns and can modify the occurrence frequency of these patterns. This influence can occur through direct adjustments to the transition probabilities between different weather regimes, or indirectly by modifying the covariates that govern the progression of these weather regimes. In Steinschneider et al. (2019), a Niño 3.4 index is used to force weather regime evolution and is systematically adjusted to create more frequent El Niño and La Niña events. In Gupta et al. (in review), a 600-year long sequence of tree-ring reconstructed principal components of weather regime occurrence are used as an alternative covariate to better capture natural variability inherent in the weather regimes.
In the most recent version of the stochastic weather generator, we developed a novel non-parametric approach to simulation of weather regimes, allowing for future dynamic change scenarios with altered (customized) weather regime probabilities. Assuming that the historical time series of water regimes is divided into distinct, consecutive segments without overlaps, each segment has a duration of D years, and there is a total of ND segments considered there (here, D=4 and ND=18). In the non-parametric method, each segment (indexed as n=1 to ND) is assigned a sampling probability denoted as pn. To generate a new sequence of daily weather regimes spanning any desired number of years, the procedure involves resampling (with replacement) the nth D-year segment of daily weather regimes using the corresponding probability pn. This process is repeated until the required number of years of simulated weather regimes has been attained. If needed, the last segment can be trimmed to ensure the precise desired duration of simulated weather regimes.
In the baseline scenario for the weather generator with no dynamic climate change (only thermodynamic change), each segment is considered equally likely (i.e., no changes to large-scale circulation patterns).
However, the probabilities pn can be adjusted to alter the frequencies of each of the identified weather regimes in the final simulation, enabling the generation of dynamic climate change scenarios (i.e., scenarios in which the frequencies of different atmospheric flow patterns change compared to their historical frequencies). This is achieved using a linear program. The goal of the linear model (not shown) is to identify new sampling probabilities pn that, when used in the non-parametric simulation approach above, create a sequence of weather regimes with long-term average frequencies that approach some vector of target probabilities for those identified weather regimes.
Lines 91-126 from ‘config.simulations.R’ show the user-defined changes to implement a non-parametric scenario with equal probabilities (0: no change to the historical sequence of weather regimes) to ten weather regimes, i.e., dynamic scenario #0; and a 30% increase in weather regime number three (a dry weather condition) in California, i.e., dynamic scenario #1.
##Choose below whether through parametric or non-parametric way to create the simulated WRs ##
use.non_param.WRs <- TRUE #{TRUE, FALSE}: TRUE for non-parametric, FALSE for parametric simulated WRs
dynamic.scenario <- 0 # {0, 1, 2}: 0: no dynamic change; 1: dynamic scenario #1 (30% increase in WR3); or 2: dynamic scenario #2 (linear trend)
if (use.non_param.WRs){ #----------- 1+2 dynamic scenarios ----------#
if (dynamic.scenario==0){
##===> Attempt #0 (thermodynamic only; no change to freq of WRs) ===##
# #specify target change (as a percent) for WR probabilities
WR_prob_change <- c(0,0,0,0,0,0,0,0,0,0) # between 0 and 1
# #how close (in % points) do the WR frequencies (probabilities) need to be to the target
lp.threshold <- 0.00001
# #how much change do we allow in a sub-period sampling probability before incurring a larger penalty in the optimization
piecewise_limit <- .02
}else if(dynamic.scenario==1){
##===> Attempt #1 (dynamic scenario #1) ===##
# #specify target change (as a percent) for WR probabilities (if, increasing WR3 in future)
WR_prob_change <- c(0,0,.3,0,0,0,0,0,0,0) # between 0 and 1
# #how close (in % points) do the WR frequencies (probabilities) need to be to the target
lp.threshold <- 0.007
# #how much change do we allow in a sub-period sampling probability before incurring a larger penalty in the optimization
piecewise_limit <- .02
}else if(dynamic.scenario==2){
##===> Attempt #2 (dynamic scenario #2) ===##
# specify target change (as a percent) for WR probabilities (if, continuing their current trends in future)
WR_prob_change <- c(-0.09969436, 0.27467048, 0.33848792,
-0.28431861, -0.23549986, 0.03889970,
-0.05628958, 0.38059153, -0.16636739, -0.17995965) # between 0 and 1
# how close (in % points) do the WR frequencies (probabilities) need to be to the target
lp.threshold <- 0.008
# how much change do we allow in a sub-period sampling probability before incurring a larger penalty in the optimization
piecewise_limit <- .02
}
}
Stochastic Weather Generation for Climate Change Scenarios
The stochastic weather generator is utilized to generate two climate change scenarios as defined above. The description of specific configurations for each scenario is listed as follows:
- Thermodynamic Scenario: 3°C increase in temperature, 7% per °C increase in precipitation extremes, no change in average precipitation.
- Dynamic Scenario: 30% increase in occurrence frequency of one weather regime only, labeled as ‘WR3’, which exhibits a ridge directly over the northwest US, i.e., blocking moisture flow over California, and resulting in dry conditions during the cold season there.
Thus, we generated 1008 years of simulated precipitation and temperature for each 12 sites in the Tuolumne River Basin in California (similar to Part 1) following these two scenarios. Below is a list of figures to understand better the impact of each scenario on precipitation and temperature statistical distributions and important climate extremes at basin scale.
The two Figures below present the cumulative distribution function (CDF) of the generated scenario for precipitation (left) and temperature (right) based on the thermodynamic and dynamic change, respectively. The observed time-series of precipitation and temperature across these 12 sites is also illustrated.

As seen above, although the 3°C warming is clearly manifested in the alteration of simulated temperature’s CDF, it is hard to notice any drastic shifts in the overall CDF of precipitation time series, as the bulk of distribution has not been altered (remember the average precipitation remained constant although its extreme quantile scaled up by ~ 22.5%).

Similarly, while the CDF of precipitation demonstrates a slight shift towards a drier condition, we notice a large shift in tail of temperature distribution.
Now, we go ahead and examine a set of important indexes for climate risk assessment of water systems. The Figure below presents the 1-day precipitation maxima derived from the generated scenario for precipitation based on the thermodynamic (left) and dynamic (right) change.

In the plot above depicted for thermodynamic climate change, the median 1-day precipitation extremes at the basin scale throughout the entire synthetic weather generation vs. historical period demonstrates a 25.5% increase in its magnitude, which is consistent with the event-based precipitation scaling by 22.5% at each site. However, such metric has almost remained unchanged in the dynamic climate change scenario.
Finally, the Figure below shows the 5-year drought derived from the generated scenario for water-year precipitation total, based on the thermodynamic (left) and dynamic (right) change.

The boxplots presented above related to the thermodynamic scenario, revealing a consistent median 5-year drought magnitude, as anticipated (no shift in the distribution of average precipitation bulk). In contrast, the dynamic climate change scenario exhibits a substantial exacerbation, with the 5-year drought magnitude worsening by around 9% compared to the historical records.
There is plenty more to explore! The stochastic weather generator is suitable to quickly simulate a long sequence of weather variables that reflect any climate change of interest. Keep an eye out for upcoming additions to the repository in the coming months, and do not hesitate to contact us or create a GitHub issue if you need clarification.
References
Gershunov, A., Shulgina, T., Clemesha, R.E.S. et al. (2019). Precipitation regime change in Western North America: The role of Atmospheric Rivers. Scientific Reports, 9, 9944. https://doi.org/10.1038/s41598-019-46169-w.
Gupta, R.S., Steinschneider S., Reed, P.M. Understanding Contributions of Paleo-Informed Natural Variability and Climate Changes on Hydroclimate Extremes in the Central Valley Region of California. Authorea. March 13, 2023. https://doi.org/10.22541/essoar.167870424.46495295/v1
Najibi, N., and Steinschneider, S. (2023). Extreme precipitation-temperature scaling in California: The role of Atmospheric Rivers, Geophysical Research Letters, 50(14), 1–11, e2023GL104606. https://doi.org/10.1029/2023GL104606.
Pendergrass, A.G., and Hartmann, D.L. (2014). Two modes of change of the distribution of rain, Journal of Climate, 27(22), 8357-8371. https://doi.org/10.1175/JCLI-D-14-00182.1
Pfahl, S., O’Gorman, P.A., Fischer, E.M. (2017). Understanding the regional pattern of projected future changes in extreme precipitation, Nature Climate Change, 7 (6), 423-427. http://dx.doi.org/10.1038/nclimate3287
Steinschneider, S., Ray, P., Rahat, S. H., & Kucharski, J. (2019). A weather‐regime‐based stochastic weather generator for climate vulnerability assessments of water systems in the western United States. Water Resources Research, 55(8), 6923-6945. https://doi.org/10.1029/2018WR024446








 is the pollution concentration in the lake,
is the pollution concentration in the lake,  is the anthropogenically pollution discharged from the town,
is the anthropogenically pollution discharged from the town, 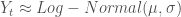 is the natural pollution inflow into the lake and follows a log-normal distribution,
is the natural pollution inflow into the lake and follows a log-normal distribution,  is the rate at which pollution is recycled from the sediment into the water column, and
is the rate at which pollution is recycled from the sediment into the water column, and  is the rate at which the nutrient pollution is removed from the lake due to natural processes.
is the rate at which the nutrient pollution is removed from the lake due to natural processes.  is generated and the policy is evaluated under these conditions. This is repeated 100 times for 100 unique realizations of natural inflow.
is generated and the policy is evaluated under these conditions. This is repeated 100 times for 100 unique realizations of natural inflow.  ) for an increasingly large number of realizations:
) for an increasingly large number of realizations:









