
A quick look into translating code: speed comparisons, practicality, and comments
As I am becoming more and more familiar with Julia—an open-source programming language—I’ve been attracted to translate code to not only run it on an opensource and free language but also to test its performance. Since Julia was made to be an open source language made to handle matrix operations efficiently (when compared to other high-level opensource languages), finding a problem to utilize these performance advantages only makes sense.
As with any new language, understanding how well it performs relative to the other potential tools in your toolbox is vital. As such, I decided to use a problem that is easily scalable and can be directly compare the performances of MATLAB and Julia—the Kirsch-Nowak synthetic stationary streamflow generator.
So, in an effort to sharpen my understanding of the Kirsch-Nowak synthetic stationary streamflow generator created by Matteo Giuliani, Jon Herman and Julianne Quinn, I decided to take on this project of converting from this generator from MATLAB. This specific generator takes in historical streamflow data from multiple sites (while assuming stationarity) and returns a synthetically generated daily timeseries of streamflow. For a great background on synthetic streamflow generation, please refer to this post by Jon Lamontagne.
Model Description
The example is borrowed from Julie’s code utilizes data from the Susquehanna River flows (cfs) at both Marietta (USGS station 01576000) and Muddy Run along with lateral inflows (cfs) between Marietta and Conowingo Damn (1932-2001). Additionally, evaporation rates (in/day) over the Conowingo and Muddy Run Dams (from an OASIS model simulation) utilized. The generator developed by Kirsch et al. (2013) utilizes a Cholesky decomposition to create a monthly synthetic record which preserves the autocorrelation structure of the historical data. The method proposed by Nowak et al. (2010) is then used to disaggregate to daily flows (using a historical month +/- 7 days). A full description of the methods can be found at this link.
Comparing Julia and MATLAB
Comparison of Performance between Julia and MATLAB
To compare the speeds of each language, I adapted the MATLAB code into Julia (shown here) on as nearly of equal basis as possible. I attempted to keep the loops, data structures, and function formulation as similar as possible, even calling similar libraries for any given function. 
When examining the performance between Julia (solid lines) and MATLAB (dashed lines), there is only one instance where MATLAB(x) outperformed Julia(+)—in the 10-realization, 1000-year simulation shown in the yellow dots in the upper left. Needless to say, Julia easily outperformed MATLAB in all other situations and required only 53% of the time on average (all simulations considered equal). However, Julia was much proportionally faster at lower dimensions of years (17-35% of the time required) than MATLAB. This is likely because I did not handle arrays optimally—the code could likely be sped up even more.
Considerations for Speeding Up Code
Row- Versus Column-Major Array Architecture
It is worth knowing how a specific language processes its arrays/matrices. MATLAB and Julia are both column-major languages, meaning the sequential indexes and memory paths are grouped by descending down row by row through a column then going through the next column. On the other hand, Numpy in Python specifically uses row-major architecture. The Wikipedia article on this is brief but well worthwhile for understanding these quirks.
This is especially notable because ensuring that proper indexing and looping methods are followed can substantially speed up code. In fact, it is likely that the reason Julia slowed down significantly on a 10-realization 1000-year simulation when compared to both its previous performances and MATLAB because of how the arrays were looped through. As a direct example shown below, when exponentiating through a [20000, 20000] array row-by-row took approximately 47.7 seconds while doing the same operation column-by-column only took 12.7 seconds.

Dealing with Arrays
Simply put, arrays and matrices in Julia are a pain compared to MATLAB. As an example of the bad and the ugly, unlike in MATLAB where you can directly declare any size array you wish to work with, you must first create an array and then fill the array with individual array in Julia. This is shown below where an array of arrays is initialized below. However, once an array is established, Julia is extremely fast in loops, so dealing with filling a previously established array makes for a much faster experience.
# initialize output
qq = Array{Array}(undef, num_sites) #(4, 100, 1200)
for i = 1:num_sites
qq[i] = Array{Float64}(undef, nR, nY * 12)
end
Once the plus side when creating arrays, Julia is extremely powerful in its ability to assign variable types to the components of a given array. This can drastically speed up your code during the day. Shown below, it is easy to the range of declarations and assignments being made to populate the array. There’s an easy example of declaring an array with zeros, and another where we’re populating an array using slices of another. Note the indexing structure for Qd_cg in the second loop–it is not technically a 3-D array but rather a 2-D array nested within a 1-D array–showing the issues mentioned prior.
delta = zeros(n_totals)
for i = 1:n_totals
for j = 1:n_sites
delta[i] += (Qtotals[month][j][i] - Z[j]) ^ 2
end
end
q_ = Array{Float64, 2}(undef, num_realizations[k], 365 * num_years[k])
for i = 1: Nsites
# put into array of [realizations, 365*num_yrs]
for j = 1: num_realizations[k]
q_[j, :] = Qd_cg[j][:, i]'
end
end
Code Profiling: Order of Experiments
An interesting observation I’ve noticed is that Julia’s first run on a given block of code is substantially slower than every other attempt. Thus, it is likely worthwhile to run a smaller-scale array through to initialize the code if there are plans to move on to substantially more expensive operations (i.e. scaling up).
In the example below, we can see that the second iteration of the same exact code was over 10% faster when calling it a second time. However, when running the code without the function wrapper (in the original timed runs), the code was 10% faster (177 seconds) than the second sequential run shown below. This points to the importance of profiling and experimenting with sections of your code.

Basic profiling tools are directly built into Julia, as shown in the Julia profiling documentation. This can be visualized easily using the ProfileView library. The Juno IDE (standard with Julia Pro) allegedly has a good built-in profile as well. However, it should be expected that most any IDE should do the trick (links to IDEs can be found here).
Syntax and Library Depreciation
While Julia is very similar in its structure and language to MATLAB, much of the similar language has depreciated as Julia has been rapidly upgraded. Notably, Julia released V1.0 in late 2018 and recently released V1.1, moving further away from similarities in function names. Thus, this stands as a lesson for individuals wishing to translate all of their code between these languages. I found a useful website that assists in translating general syntax, but many of the functions have depreciated. However, as someone who didn’t have any experience with MATLAB but was vaguely familiar with Julia, this was a godsend for learning differences in coding styles.
For example, creating an identity matrix in MATLAB utilizes the function eye(size(R)) to create an nxn matrix the size of R. While this was initially the language used in Julia, this specific language was depreciated in V0.7. To get around this, either ‘I’ can be used to create a scalable identity matrix or Matrix{Float64}(I, size(R), size(R)) declare an identity matrix of size(R) by size(R) for a more foolproof and faster operation.
When declaring functions, I have found Julia to be relatively straightforward and Pythonic in its declarations. While I still look to insert colons at the ends of declarations while forgetting to add ‘end’ at the end of functions, loops, and more, the ease of creating, calling, and interacting with functions makes Julia very accessible. Furthermore, its ability to interact with matrices in without special libraries (e.g. Numpy in Python) allows for more efficient coding without having to know specific library notation.
Debugging Drawbacks
One of the most significant drawbacks I run into when using Julia is the lack of clarity in generated error codes for common mistakes, such as adding extra brackets. For example, the following error code is generated in Python when adding an extra parenthesis at the end of an expression.
However, Julia produces the follow error for an identical mistake:

One simple solution to this is to simply upgrade my development environment from Jupyter Notebooks to a general IDE to more easily root out issues by running code line-by-line. However, I see the lack of clarity in showing where specific errors arise a significant drawback to development within Julia. However, as shown in the example below where an array has gone awry, an IDE (such as Atom shown below) can make troubleshooting and debugging a relative breeze.

Furthermore, when editing auxiliary functions in another file or module that was loaded as a library, Julia is not kind enough to simply reload and recompile the module; to get it to properly work in Atom, I had to shut down the Julia kernel then rerun the entirety of the code. Since Julia takes a bit to initially load and compile libraries and code, this slows down the debugging process substantially. There is a specific package (Revise) that exists to take care of this issue, but it is not standard and requires loading this specific library into your code.
GitHub Repositories: Streamflow Generators
PyMFGM: A parallelized Python version of the code, written by Bernardo Trindade
Kirsch-Nowak Stationary Generator in MATLAB: Developed by Matteo Giuliani, Jon Herman and Julianne Quinn
Kirsch-Nowak Stationary Generator in Julia: Please note that the results are not validated. However, you can easily access the Jupyter Notebook version to play around with the code in addition to running the code from your terminal using the main.jl script.
Full Kirsch-Nowak Streamflow Generator: Also developed by Matteo Giuliani, Jon Herman and Julianne Quinn and can handle rescaling flows for changes due to monsoons. I would highly suggest diving into this code alongside the relevant blog posts: Part 1 (explanation), Part 2 (validation).











 is the weight assigned to weak classifier
is the weight assigned to weak classifier 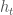 around samples
around samples 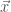 at iteration t, and T is the number of classifiers in the ensemble.
at iteration t, and T is the number of classifiers in the ensemble.
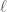 is a loss function, Boosting is trained via gradient descent in functional space, so that:
is a loss function, Boosting is trained via gradient descent in functional space, so that: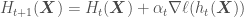

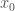 to the value of
to the value of  with the minimum value of
with the minimum value of 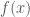 , which in machine learning is a loss function, henceforth called
, which in machine learning is a loss function, henceforth called  . Gradient descent does that by moving one step of length s at a time starting from
. Gradient descent does that by moving one step of length s at a time starting from  in the direction of the steeped downhill slope at location
in the direction of the steeped downhill slope at location  , the value of
, the value of  iteration. This idea is formalized by the Taylor series expansion below:
iteration. This idea is formalized by the Taylor series expansion below:
 . Furthermore,
. Furthermore,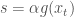
![\ell\left[x_{t+1} -\alpha g(x_t)\right] \approx \ell(x^{t})-\alpha g(x_t)^Tg(x_t)](https://s0.wp.com/latex.php?latex=%5Cell%5Cleft%5Bx_%7Bt%2B1%7D+-%5Calpha+g%28x_t%29%5Cright%5D+%5Capprox+%5Cell%28x%5E%7Bt%7D%29-%5Calpha+g%28x_t%29%5ETg%28x_t%29&bg=ffffff&fg=444444&s=0&c=20201002)
 , called the learning rate, must be positive and can be set as a fixed parameter. The dot product on the last term
, called the learning rate, must be positive and can be set as a fixed parameter. The dot product on the last term 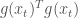 will also always be positive, which means that the loss should always decrease — the reason for the italics is that too high values for
will also always be positive, which means that the loss should always decrease — the reason for the italics is that too high values for  would be a function of a function, say
would be a function of a function, say 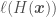 instead of a real number x. As mentioned, Gradient Descent in real space works by adding small quantities to
instead of a real number x. As mentioned, Gradient Descent in real space works by adding small quantities to  , which is an ensemble of small
, which is an ensemble of small 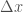 ‘s added together. By analogy, gradient descent in functional space works by adding functions to an ever growing ensemble of functions. Using the definition of a functional gradient, which is beyond the scope of the this post, this leads us to:
‘s added together. By analogy, gradient descent in functional space works by adding functions to an ever growing ensemble of functions. Using the definition of a functional gradient, which is beyond the scope of the this post, this leads us to: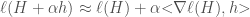
 notation denotes a dot product between f and g. Gradient descent in function space is an important component of Boosting. Based on that, the next section will talk about AdaBoost, a specific Boosting algorithm.
notation denotes a dot product between f and g. Gradient descent in function space is an important component of Boosting. Based on that, the next section will talk about AdaBoost, a specific Boosting algorithm.
 is the
is the 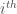 data point in the training set. The step size
data point in the training set. The step size  have corresponding vector of dependent variables
have corresponding vector of dependent variables 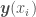 , in which each
, in which each  is a vector with the classification of each point, with -1 and 1 representing the two classes to which a point may belong (say, -1 for red circles and 1 for blue crosses). The weak classifiers h in AdaBoost also return
is a vector with the classification of each point, with -1 and 1 representing the two classes to which a point may belong (say, -1 for red circles and 1 for blue crosses). The weak classifiers h in AdaBoost also return 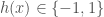 .
.
![\alpha=argmin_{\alpha}\sum_{i=1}^ne^{y(\boldsymbol{x}_i)\left[H(\boldsymbol{x}_i)+\alpha h(\boldsymbol{x}_i)\right]}](https://s0.wp.com/latex.php?latex=%5Calpha%3Dargmin_%7B%5Calpha%7D%5Csum_%7Bi%3D1%7D%5Ene%5E%7By%28%5Cboldsymbol%7Bx%7D_i%29%5Cleft%5BH%28%5Cboldsymbol%7Bx%7D_i%29%2B%5Calpha+h%28%5Cboldsymbol%7Bx%7D_i%29%5Cright%5D%7D+&bg=ffffff&fg=444444&s=0&c=20201002)
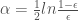
 is the classification error of weak classifier
is the classification error of weak classifier  will be the one that minimizes the term
will be the one that minimizes the term  , which when zero would mean that the zero-slope ensemble has been reached, denoting the minimum value of the loss function has been reached for a convex problem such as this. Replacing the dot product by a summation, this minimization problem can be written as:
, which when zero would mean that the zero-slope ensemble has been reached, denoting the minimum value of the loss function has been reached for a convex problem such as this. Replacing the dot product by a summation, this minimization problem can be written as: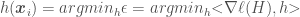


 — e.g., in panel “b” the error would be summation the of the weights of the two crosses on the upper left corner and of the circle at the bottom right corner. Now let’s get to these weights.
— e.g., in panel “b” the error would be summation the of the weights of the two crosses on the upper left corner and of the circle at the bottom right corner. Now let’s get to these weights.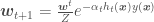
 is a vector containing the weights of each point, Z is a normalization factor to ensure the weights will sum up to 1. Be sure not to confuse
is a vector containing the weights of each point, Z is a normalization factor to ensure the weights will sum up to 1. Be sure not to confuse 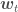 . For the weights to sum up to 1, Z needs to be the sum of their pre-normalization values, which is actually identical to the loss function, so
. For the weights to sum up to 1, Z needs to be the sum of their pre-normalization values, which is actually identical to the loss function, so
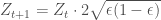



 . We have that:
. We have that:![\ell(H)\leq n\left[2\sqrt{\epsilon_{max}(1-\epsilon_{max})}\right]^T](https://s0.wp.com/latex.php?latex=%5Cell%28H%29%5Cleq+n%5Cleft%5B2%5Csqrt%7B%5Cepsilon_%7Bmax%7D%281-%5Cepsilon_%7Bmax%7D%29%7D%5Cright%5D%5ET+&bg=ffffff&fg=444444&s=0&c=20201002)
 , we have that
, we have that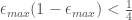

 in the interval
in the interval ![\left[-\frac{1}{2},\frac{1}{2}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B-%5Cfrac%7B1%7D%7B2%7D%2C%5Cfrac%7B1%7D%7B2%7D%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002) . Therefore, replacing the equation above in the first loss inequality written as a function of
. Therefore, replacing the equation above in the first loss inequality written as a function of 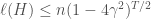
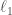 regularization, which is prone to eliminate irrelevant features and thus reduce overfitting. Another explanation is related to the concept of margins, so that at least certain boosting algorithms force a classification on a point only if possible by a certain margin, thus also preventing overfitting.
regularization, which is prone to eliminate irrelevant features and thus reduce overfitting. Another explanation is related to the concept of margins, so that at least certain boosting algorithms force a classification on a point only if possible by a certain margin, thus also preventing overfitting.
 (1)
(1) (2)
(2) is a diagonal covariance matrix with
is a diagonal covariance matrix with ![[\Sigma_y]_{\alpha,\alpha}=\sigma^2_{\alpha, y}](https://s0.wp.com/latex.php?latex=%5B%5CSigma_y%5D_%7B%5Calpha%2C%5Calpha%7D%3D%5Csigma%5E2_%7B%5Calpha%2C+y%7D&bg=ffffff&fg=444444&s=0&c=20201002) for each feature
for each feature  as:
as: (3)
(3) (4)
(4) (5)
(5) (6)
(6) (7)
(7)

