
If you’re a reader of this blog, you are probably well aware that historical observations of streamflow and rainfall represent single traces of inherently stochastic processes. Simply relying on the historical record when evaluating decisions in water resources problems may cause us to underestimate uncertainty and overestimate the reliability of our system. Synthetic generation of streamflow and weather data can help us overcome this challenge. Synthetic generation is a family of methods that allow us to explore conditions not observed in the historical record while preserving fundamental statistical properties of the recorded observations (for a great history of synthetic generation, see Jon’s post). Before using synthetically generated records, we first need to perform a diagnostic evaluation to ensure that the synthetic records preserve properties such as the moments of the historical record as well as the spatial and temporal correlation structures (for some great tutorials on this process, see Julie and Lillian’s posts). Another important aspect of understanding the synthetically generated records is the extreme events they produce – a topic that this blog has not explored in detail. Evaluating extreme events helps us understand the internal variability present in the stochastic system and contextualize the ensemble of synthetic records with events in the historical record (such as large droughts and floods).
In this post, we’ll explore how a small ensemble of synthetically generated streamflows in the Upper Colorado River basin produces decadal drought events. We’ll start with a definition of decadal drought and then explore the frequency, magnitude, and distribution of drought events across our ensemble of synthetically generated streamflows. The streamflow records used in this post were generated using a Gaussian Hidden Markov Model (HMM) streamflow generator. These records have previously been diagnostically evaluated to confirm that they reproduce the statistical properties of the historical record. For details on HMM generation and diagnostic evaluation, see Julie’s posts on introducing HMM generators and providing example code.
Defining decadal drought
We’ll begin by defining a measure of decadal drought introduced by Ault et al., (2014). This measure defines a decadal drought as a period when the 11-year rolling mean of streamflows drops below a drought threshold. The threshold is defined as half a standard deviation below the mean of the full historical record. Note this is one of many definitions of drought. For a detailed discussion of drought metrics, see Rohini’s recent post.

Periods of decadal drought in the historical record are highlighted with shading in the figure below.

I’ve written a simple Python function to find these droughts in a streamflow record, count the number of droughts, and calculate the magnitude of drought events (more on this below).
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import statistics
import matplotlib.cm as cm
from mpl_toolkits.axes_grid1 import make_axes_locatable
def drought_statistics(file_name, hist, drought_def):
'''
Identifies drought periods in a streamflow record. Returns drought instances, list of drought years, and severity
:param file_name: path to the annual Q file (string)
:param hist: historical record toggle (bool)
:param drought_def: size of moving window (float)
:return:
- drought_instances (list) - all drought periods in the record
- final_drought_range (list) ranges of years of decadal droughts in the record
- total_severity - sum of the difference between the mean & annual flows during a drought normalized by std
'''
# Read historical or synthetic record
if hist:
AnnualQ_s = pd.read_csv(file_name, sep=',')
else:
AnnualQ_s = pd.read_csv(file_name, sep=' ', header=None)
AnnualQ_s.columns = ['cm', 'gm', 'ym', 'wm', 'sj']
AnnualQ_s['Year'] = list(range(1909, 2014))
# find the drought threshold
std = statistics.stdev(AnnualQ_s.iloc[:, 0])
threshold = np.mean(AnnualQ_s.iloc[:, 0]) - (0.5 * std)
drought_instances = [i for i, v in enumerate(AnnualQ_s.iloc[:, 0].rolling(drought_def).mean()) if v < threshold]
drought_years = AnnualQ_s.iloc[:, 5].rolling(drought_def).mean()[drought_instances]
# find years of drought in each record
drought_range = [range(0, 1)]
j = 0
for i in range(len(drought_years)):
already_in = 0
for j in range(len(drought_range)):
if drought_years.iloc[i] in drought_range[j]:
already_in = 1
if already_in == 0:
start_year = drought_years.iloc[i] - 5
end_year = drought_years.iloc[i] + 5
drought_range.append(range(int(start_year), int(end_year)))
elif already_in == 1:
if drought_years.iloc[i] - 5 < start_year:
start_year = drought_years.iloc[i] - 5
if drought_years.iloc[i] + 5 > end_year:
end_year = drought_years.iloc[i] + 5
drought_range.append(range(int(start_year), int(end_year)))
# combine overlapping periods
final_drought_range = []
for i in range(1, len(drought_range)):
if final_drought_range:
if min(drought_range[i]) < max(final_drought_range[-1]):
final_drought_range[-1] = range(min(final_drought_range[-1]), max(drought_range[i]) + 1)
elif min(drought_range[i]) < min(drought_range[i - 1]):
final_drought_range.append(range(min(drought_range[i - 1]), int(max(drought_range[i]) + 1)))
else:
final_drought_range.append(drought_range[i])
else:
if min(drought_range[i]) < min(drought_range[i - 1]):
final_drought_range.append(range(min(drought_range[i - 1]), max(drought_range[i]) + 1))
else:
final_drought_range.append(drought_range[i])
# calculate the severity of droughts
total_severity = []
if drought_instances:
for i in range(len(final_drought_range)):
cur_severity = 0
for j in range(105):
if AnnualQ_s.iloc[j, 5] in final_drought_range[i]:
cur_severity += (AnnualQ_s.iloc[:, 0].mean() - AnnualQ_s.iloc[j, 0])/std
total_severity.append(cur_severity)
return drought_instances, final_drought_range, total_severity
We can run this function for our small ensemble of 100 records generated (which can be found here) using the code below:
drought_def = 11 # size of moving window
# synthetic realizations
num_droughts = np.zeros(100)
severity_curve = []
all_drought_years =[]
max_severity = np.zeros(100)
for r in range(0,100):
file_name = 'data/AnnualQ_s' + str(r) + '.txt' # edit here
drought_instances, drought_years, drought_severity = drought_statistics(file_name, False, drought_def)
if drought_instances:
all_drought_years.append(drought_years)
severity_curve.append(drought_severity)
max_severity[r] = max(drought_severity)
# Historical (edit file name)
file_name = 'data/historical.csv'
drought_instances_hist, drought_years_hist, drought_severity_hist = drought_statistics(file_name, True, drought_def)
drought_ranks = np.zeros([len(severity_curve), 5])
for i in range(len(severity_curve)):
sorted_curve = np.sort(severity_curve[i])[::-1]
for j in range(len(sorted_curve)):
drought_ranks[i, j] = sorted_curve[j]
drought_ranks_hist = np.zeros(5)
sorted_ranks_hist = np.sort(drought_severity_hist)[::-1]
for i in range(len(drought_severity_hist)):
drought_ranks_hist[i] = sorted_ranks_hist[i]
max_ranks = np.max(drought_ranks, axis=0)
min_ranks = np.min(drought_ranks, axis=0)
# pad ranks with zeros for realizations without droughts
no_drought_traces = 99-len(severity_curve)
print('num no drought rels = ' + str(no_drought_traces))
for nr in range(no_drought_traces):
drought_ranks = np.vstack((drought_ranks, np.zeros(5)))
Examining Drought Frequency
The first diagnostic we’ll perform is to examine the frequency of drought years in our ensemble of synthetic records (shaded years in the figure above) against the number of drought years in the historical record.
def count_drought_years(droughts):
total_drought_years = 0
for i in range(len(droughts)):
total_drought_years += len(droughts[i])
return total_drought_years
drought_lengths = np.zeros(100)
for d in range(len(all_drought_years)):
drought_lengths[d] = count_drought_years(all_drought_years[d])
hist_drought_years = count_drought_years(drought_years_hist)
fig, ax = plt.subplots()
ax.bar(np.arange(len(num_droughts)), np.sort(drought_lengths))
ax.plot(np.arange(100), np.ones(100) * hist_drought_years, color='k', linestyle='--')
ax.set_xlim([0, 100])
ax.set_ylim([0, 50])
ax.set_xlabel('Rank Across Ensemble')
ax.set_ylabel('Number of Drought Years')
plt.savefig('DroughtFrequency.png')
This code produces the figure shown below. Each bar represents the number of drought years in a single synthetic realization (ranked from lowest to highest), and the dashed line represents the number of drought years in the historical record. We observe that the number of drought years in the historical record sits right in the middle of the range of synthetic realizations. We can see that the maximum number of drought years is twice as high as observed in the historical record – indicating that some realizations generate much more challenging drought scenarios than the observed record. We also see that some realizations have zero years of drought – indicating they are much milder than the observed record.

Evaluating drought magnitude
Another way we can evaluate droughts generated by our synthetic records is to examine the maximum magnitude of drought events produced by each record. To do this, we need a measure of drought magnitude. Here, we’ll define drought magnitude as the difference between the historical mean flow and the flow during drought periods normalized by the standard deviation. We can express this mathematically with a simple integral:

We can visualize this metric in the figure below. Drought magnitude is the sum of the red regions for each drought.

Below, we’ll plot drought magnitude using a horizontal bar chart to make it look distinct from the frequency plot. The maximum drought magnitude in the historical record will be plotted as a black dashed line.
fig, ax = plt.subplots()
ax.barh(np.arange(len(num_droughts)), np.sort(max_severity))
ax.plot(np.ones(100)*max(drought_severity_hist), np.arange(100), color='k', linestyle='--')
ax.set_ylim([0,100])
ax.set_xlabel('Drought Magnitude')
ax.set_ylabel('Rank Across Ensemble')
plt.savefig('DroughtMagnitude.png')

In the plot above, we observe that the magnitude of droughts in our synthetic records can get much more severe than the worst drought observed in the historical period. This finding aligns with studies on the Upper Colorado River basin using paleo data (Ault et al., 2014; Woodhouse et al., 2014) and underscores that relying solely on the historical record may underestimate drought risk for the basin.
Pulling it all together
To end our exploration, we’ll generate a final plot that simultaneously visualizes the frequency and magnitude of drought events in the synthetic realizations and the historical record. This plot will show all droughts in a given record, ranked according to their magnitude. To visualize the full ensemble of synthetic records, we’ll plot the percentiles of magnitude across the ensemble of 100 records.
fig, ax = plt.subplots()
# Calculate the percentiles of drought magnitude across the ensemble
ps = np.arange(0, 1.01, 0.01) * 100
for j in range(1, len(ps)):
u = np.percentile(drought_ranks, ps[j], axis=0)
l = np.percentile(drought_ranks, ps[j - 1], axis=0)
# plot the percentiles
ax.fill_between(np.arange(0, 1.25, .25), l, u, color=cm.OrRd(ps[j - 1] / 100.0), alpha=0.75,
edgecolor='none')
dummy = ax.scatter([100,200], [100,200], c=[0,1], cmap='OrRd') # dummy for the colorbar
# plot the historical droughts for context
for i in range(4):
if drought_ranks_hist[i] > 0:
ax.scatter(np.arange(0, 1.25, .25)[i], drought_ranks_hist[i], color='k', s=50, zorder=3)
# make a color bar
divider = make_axes_locatable(ax)
cax = divider.append_axes('right', size='5%', pad=0.05)
fig.colorbar(dummy, cmap='OrRd', cax=cax, orientation='vertical', label='Ensemble Exceedance')
# format the plot
ax.set_xlim([0, 1])
ax.set_xticks([0,.25, .5, .75, 1])
ax.set_ylim([0, 16])
ax.set_title('Drought In Synthetic Records', fontsize=16)
ax.set_ylabel('Drought Magnitude', fontsize=14)
ax.set_xlabel('Exceedance', fontsize=14)
plt.savefig('FreqSeverity.png')

The color in the figure above represents the percentiles of the synthetic records, and the two black points represent the droughts observed in the historical record. The vertical axis represents the magnitude of drought events, and the horizontal axis represents the fraction of droughts in a record that exceeds a given event. We can see that the maximum drought magnitude generated by the synthetic ensemble is much greater than the most severe drought of record (as observed in our magnitude figure). We can also see that the second most severe historical drought is right in the middle of the distribution of the second-highest droughts produced by the synthetic ensemble (.25 on the horizontal axis). Finally, we observe that while most realizations produce two decadal drought events, a small fraction contain an additional drought event.
Final thoughts
This analysis complements traditional diagnostic evaluation of synthetic streamflow records by revealing the extent of extreme events generated by our synthetic generator and contextualizing synthetic events in the historical record. Historical contextualization can help us communicate our experimental results to decision-makers by making an analysis that uses synthetic records less abstract. This analysis also helps us understand the internal variability of the stochastic process, which can provide a helpful baseline if we’re investigating non-stationarity.
References
Ault, T. R., Cole, J. E., Overpeck, J. T., Pederson, G. T., & Meko, D. M. (2014). Assessing the risk of persistent drought using climate model simulations and paleoclimate data. Journal of Climate, 27(20), 7529-7549.
Woodhouse, C. A., Gray, S. T., & Meko, D. M. (2006). Updated streamflow reconstructions for the Upper Colorado River basin. Water Resources Research, 42(5).














































 is the time it takes the serial version of the MOEA to achieve a given hypervolume threshold, and
is the time it takes the serial version of the MOEA to achieve a given hypervolume threshold, and 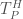 is the time it takes the parallel implementation to reach the same threshold. Figure 1 below, adapted from Hadka and Reed, (2014), shows the hypervolume speedup across different parallel implementations of the Borg MOEA for the five objective NSGA II test problem run on 16,384 processors (in this work the parallel epsilon-NSGA II algorithm is used as a baseline rather than a serial implementation). Results from Figure 1 reveal that the Multi-Master implementations of Borg are able to reach each hypervolume threshold faster than the baseline algorithm and the master-worker implementation. For high hypervolume thresholds, the 16 and 32 Master implementations achieve the hypervolume thresholds 10 times faster than the baseline.
is the time it takes the parallel implementation to reach the same threshold. Figure 1 below, adapted from Hadka and Reed, (2014), shows the hypervolume speedup across different parallel implementations of the Borg MOEA for the five objective NSGA II test problem run on 16,384 processors (in this work the parallel epsilon-NSGA II algorithm is used as a baseline rather than a serial implementation). Results from Figure 1 reveal that the Multi-Master implementations of Borg are able to reach each hypervolume threshold faster than the baseline algorithm and the master-worker implementation. For high hypervolume thresholds, the 16 and 32 Master implementations achieve the hypervolume thresholds 10 times faster than the baseline.


