
I’ve been developing some course material on multiobjective optimization, and I thought I’d share an introductory exercise I’ve written as a blog post. The purpose of the exercise is to introduce students to multi-objective optimization, starting with basic terms and moving toward the central concept of Pareto dominance (which I’ll define below). The exercise explores trade-offs across two conflicting objectives in the design of a cantilever beam. This example is drawn from the textbook “Multi-Objective Optimization using Evolutionary Algorithms” by Kalyanmoy Deb (2001), though all code is original. This exercise is intended to be a teaching tool to complement introductory lectures on multi-objective optimization and Pareto dominance.
A simple model of a cantilever beam
In this exercise, we’ll first develop a simple model to evaluate a cantilever beam’s deflection, weight, and stress supporting a constant force (as specified by Deb, 2001). We’ll then enumerate possible design alternatives and visualize feasible designs and their performance. Next, we’ll introduce Pareto Dominance and examine trade-offs between conflicting system objectives. Finally, we’ll use the NSGA-II Multiobjective Evolutionary Algorithm (MOEA) to discover a Pareto-approximate set of designs and visualize design alternatives.
Let’s start by considering the cantilever beam shown below.

Our task is to “design” the beam by specifying its length (l) and diameter (d). Assuming the beam will be subjected to a constant force, P, we are interested in minimizing two conflicting performance objectives, the weight and the end deflection. We can model our beam using the following system of equations:

Following Deb (2001), we’ll use the parameter values shown below:
10mm ≤ d ≤ 50 mm; 200 mm ≤ l ≤ 1000 mm; ρ = 7800 kg/m3; P = 1 KN; E = 207 GPa
We would also like to ensure that our beam meets two feasibility constraints:

Modeling the beam in Python
As multiobjective design problems go, this is a fairly simple problem to solve. We can enumerate all possible design options and explore trade-offs between different combinations of length and diameter. Below I’ve coded a Python function to evaluate a beam with parameters l and d.
# create a model of the beam
def cantileverBeam(l, d):
"""
Models the weight, deflection and stress on a cantilever beam subjected to a force of P=1 kN
:param l: length of the beam (mm)
:param d: diameter of the beam (mm)
:return:
- weight: the weight of the beam
- deflection: the deflection of the beam
- stress: the stress on the beam
"""
weight = (7800.0 * (3.14159 * d**2)/4 * l)/1000000000 # (division by 1000000000 is unit conversion)
deflection = (64.0*P * l**3)/(3.0*207.0*3.14159*d**4)
stress = (32.0 * P * l)/(3.14159*d**3)
return weight, deflection, stress
With this function, we can explore alternative beam designs. We’ll first create a set of samples of l and d, then simulate them through our beam model. Using our results, we’ll visualize the search space, which includes all possible design alternatives for l and d, enclosed 10≤ d ≤ 50 and 200 ≤ l ≤ 1000. Inside the search space, we can also delineate the feasible decision space composed of all combinations of l and d that meet our beam performance constraints. Every feasible solution can be mapped to the feasible objective space, which contains each sized beam’s corresponding weight and deflection. In the code below, we’ll simulate 1681 different possible beam designs and visualize the feasible decision space and the corresponding objective space.
import numpy as np
from matplotlib import pyplot as plt
# initialize arrays to store our design parameters
l = np.arange(200, 1020, 20)
d = np.arange(10,51,1)
P = 1.0
# initialize arrays to store model output
weight = np.zeros([41,41])
deflection = np.zeros([41,41])
constraints = np.zeros([41,41])
stress = np.zeros([41,41])
# evaluate the system
for i in range(41):
for j in range(41):
weight[i, j], deflection[i,j], stress[i,j] = cantileverBeam(l[i], d[j])
if stress[i, j] <= 300 and deflection[i, j] <= 5:
constraints[i,j] =1
# create a figure with two subplots
fig, axes = plt.subplots(1, 2, figsize=(12,4))
# plot the decision space
for i in range(41):
for j in range(41):
axes[0].scatter(i,j, c=constraints[i,j], cmap='Blues', vmin=0, vmax=1, alpha=.6)
axes[0].set_xticks(np.arange(0,45,5))
axes[0].set_yticks(np.arange(0,45,5))
axes[0].set_yticklabels(np.arange(10,55,5))
axes[0].set_xticklabels(np.arange(200,1100,100))
axes[0].set_xlabel('Length (mm)')
axes[0].set_ylabel('Diameter (mm)')
axes[0].set_title('Decision Space')
# plot the objective space
axes[1].scatter(weight.flatten(), deflection.flatten(), edgecolor='white')
axes[1].set_ylim([0,5])
axes[1].set_xlabel('Weight (kg)')
axes[1].set_ylabel('Deflection (mm)')
axes[1].set_title('Objective Space')

Examining the figures above, we observe that only around 40% of our evaluated beam designs are feasible (they meet the constraints of maximum stress and deflection). We can see a clear relationship between length and diameter – long narrow beams are unlikely to meet our constraints. When we examine the objective space of feasible beam designs, we observe trade-offs between our two objectives, weight and deflection. Examine the objective space. Is there a clear “best” beam that you would select? Are there any alternatives that you would definitely not select?
Introducing Pareto Dominance
Without a clear articulation of our preferences between weight and deflection, we cannot choose a single “best” design. We can, however, definitively rule out many of the beam designs using the concept of Pareto dominance. We’ll start by picking and comparing the objectives of any two designs from our set of feasible alternatives. For some pairs, we observe that one design is better than the other in both weight and deflection. In this case, the design that is preferable in both objectives is said to dominate the other design. For other pairs of designs, we observe that one design is preferable in weight while the other is preferable in deflection. In this case, both designs are non-dominated, meaning that the alternative is not superior in both objectives. If we expand from pairwise comparisons to evaluating the entire set of feasible designs simultaneously, we can discover a non-dominated set of designs. We call this set of designs the Pareto-optimal set. In our beam design problem, this is the set of designs that we should focus our attention on, as all other designs are dominated by at least one member of this set. The curve made by plotting the Pareto-optimal set is called the Pareto front. The Pareto front for the problem is plotted in orange in the figure below.

Multiobjective optimization
As mentioned above, the cantilever beam problem is trivial because we can easily enumerate all possible solutions and manually find the Pareto set. However, we are not so lucky in most environmental and water resources applications. To solve more challenging problems, we need new tools. Fortunately for us, these tools exist and have been rapidly improving in recent decades (Reed et al., 2013). One family of multiobjective optimization techniques that have been shown to perform well on complex problems is MOEAs (Coello Coello, 2007). MOEAs use search operators inspired by natural evolution, such as recombination and mutation, to “evolve” a population of solutions and generate approximations of the Pareto set. In the sections below, we’ll employ a widely used MOEA, NSGA-II (Deb et al., 2002), to find Pareto approximate designs for our simple beam problem. We’ll use the Platypus Python library to implement our evolutionary algorithm and explore results. Platypus is a flexible and easy-to-use library that contains 20 different evolutionary algorithms. For more background on MOEAs and Platypus, see the examples in the library’s online documentation.
Formulating the optimization problem
Formally, we can specify our multiobjective problem as follows:

Multiobjective optimization in Python with Platypus
Below we’ll define a function to use in Platypus based on our problem formulation. To work with Platypus, this function must accept a vector of decision variables (called vars) and return a vector of objectives and constraints.
# Define a function to use with NSGA-II
def evaluate_beam(vars):
"""
A version of the cantilever beam model to optimize with an MOEA in Platypus
:param vars: a vector with decision variables element [0] is length, [1] is diameter
:return:
- a vector of objectives [weight, deflection]
- a vector of constraints, [stress, deflection]
"""
l = vars[0]
d = vars[1]
weight = (7800.0 * (3.14159 * d ** 2) / 4 * l)/1000000000
deflection = (64.0*1.0 * l**3)/(3.0*207.0*3.14159*d**4)
stress = (32.0 * 1.0 * l)/(3.14159*d**3)
return [weight, deflection], [stress - 300, deflection - 5]
Next, we’ll instantiate a problem class in Platypus. We’ll first create a class with 2 decision variables, 2 objectives, and 2 constraints, then specify the allowable range of each decision variable, the type of constraints, and s function the algorithm will evaluate. We’ll then select NSGAII as our algorithm and run the optimization for 1000 generations.
# set up the Platypus problem (2 decision variables, 2 objectives, 2 constraints)
problem = Problem(2, 2, 2)
# specify the decision variable ranges (200 mm <= length <= 1000 mm) and (10 mm <= diameter <= 50 mm)
problem.types[:] = [Real(200, 1000), Real(10, 50)]
# specify the type of constraint
problem.constraints[:] = "<=0"
# tell Platypus what function to optimize
problem.function = evaluate_beam
# set NSGA II to optimize the problem
algorithm = NSGAII(problem)
# run the optimization for 1000 generations
algorithm.run(2000)
Plotting our approximation of the Pareto front allows us to examine trade-offs between the two conflicting objectives.
# plot the Pareto approximate set
fig = plt.figure()
plt.scatter([s.objectives[0] for s in algorithm.result],
[s.objectives[1] for s in algorithm.result])
plt.xlabel('Weight (kg)')
plt.ylabel('Deflection (mm)')
plt.xlim([0,5])
plt.ylim([0,5])

NSGA-II has found a set of non-dominated designs that show a strong trade-off between beam weight and deflection. But how does our approximation compare to the Pareto front we discovered above? A good approximation of the Pareto front should have two properties 1) convergence, meaning the approximation is close to the true Pareto front, and 2) diversity, meaning the solutions cover as much of the true Pareto front as possible. We can plot the designs discovered by NSGA-II in the space of the enumerated designs to reveal that the algorithm is able to do a great job approximating the true Pareto front. The designs it discovered are right on top of the true Pareto front and maintain good coverage of the range of trade-offs.

In real-world design problems, the true Pareto front is usually not known, so it’s important to evaluate an MOEA run using runtime diagnostics to assess convergence. Here we can visualize the algorithm’s progress over successive generations to see it converge to a good approximation of the Pareto front. Notice how the algorithm first evolves solutions that maintain good convergence, then adds to these solutions to find a diverse representation of the Pareto front. In more complex or higher-dimensional contexts, metrics of runtime performance are required to assess MOEA performance. For background on runtime diagnostics and associated performance metrics, see this post.

Final thoughts
In this exercise, we’ve explored the basic multiobjective concepts through the design of a cantilever beam. We introduced the concepts of the search space, feasible decision space, objective space, and Pareto dominance. We also solved the multiobjective optimization problem using the NSGA-II MOEA. While the cantilever beam model used here is simple, our basic design approach can be adapted to much more complex and challenging problems.
References
- Coello, C. C. (2006). Evolutionary multi-objective optimization: a historical view of the field. IEEE computational intelligence magazine, 1(1), 28-36.
- Deb, K. (2011). Multi-objective optimisation using evolutionary algorithms: an introduction. In Multi-objective evolutionary optimisation for product design and manufacturing (pp. 3-34). London: Springer London.
- Deb, K., Pratap, A., Agarwal, S., & Meyarivan, T. A. M. T. (2002). A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE transactions on evolutionary computation, 6(2), 182-197.
- Reed, P. M., Hadka, D., Herman, J. D., Kasprzyk, J. R., & Kollat, J. B. (2013). Evolutionary multiobjective optimization in water resources: The past, present, and future. Advances in water resources, 51, 438-456.











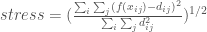
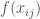 is the euclidean distance between points
is the euclidean distance between points  and
and  in the full dimensional space. (Note: extensions of MDS have been developed that substitute this distance for a weakly monotonic transformation of the original points)
in the full dimensional space. (Note: extensions of MDS have been developed that substitute this distance for a weakly monotonic transformation of the original points) is the euclidean distance between points
is the euclidean distance between points 


 : is the distance between points x_i and x_j in the full objective space
: is the distance between points x_i and x_j in the full objective space : is the distance between points x_i and x_j in the lower dimensional space
: is the distance between points x_i and x_j in the lower dimensional space









{kind=link}
{kind=link}