In this blog post, we will be discussing the many household uses of citrus aurantiifolio, or the common lime.
Just kidding, we’ll be talking about a completely different type of LIME, namely Local Interpretable Model-Agnostic Explanations (at this point you may be thinking that the former’s scientific name becomes the easier of the two to say). After all, this is the WaterProgramming blog.
On a more serious note though, LIME is one of the two widely-known model agnostic explainable AI (xAI) methods, alongside Shapley Additive Explanations (SHAP). This post is intended to be an introduction to LIME in particular, and we will be setting up the motivation for using xAI methods as well as a brief example application using the North Carolina Research Triangle system.
Before we proceed, here’s a quick graphic to get oriented:

The figure above mainly demonstrates three main concepts: Artificial Intelligence (AI), the methods used to achieve AI (one of which includes Machine Learning, or ML), and the methods to explain how such methods achieved their version of AI (explainable AI, or more catchily known as xAI). For more explanation on the different categories of AI, and their methods, please refer to these posts by IBM’s Data Science and AI team and this SpringerLink book by Sarker (2022) respectively.
Model-agnostic vs model-specific
Model-specific methods
As shown in the figure, model-specific xAI methods are techniques that can only be used on the specific model that it was designed for. Here’s a quick rundown of the type of model and their available selection of xAI methods:
- Decision trees
- Decision tree visualization (e.g. Classification and Regression Tree (CART) diagrams)
- Feature importance rankings
- Neural networks (NN), including deep neural networks
- Coefficient (feature weight) analysis
- Neural network neuron/layer activation visualization
- Attention (input sequence) mechanisms
- Integrated gradients
- DeepLIFT
- GradCAM
- Reinforcement learning
- Causal models
Further information on the mathematical formulation for these methods can be found in Holzinger et al (2022). Such methods account for the underlying structure of the model that they are used for, and therefore require some understanding of the model formulation to fully comprehend (e.g. interpreting NN activation visualizations). While less flexible than their agnostic counterparts, model-specific xAI methods provide more granular information on how specific types of information is processed by the model, and therefore how changing input sequences, or model structure, can affect model predictions.
Model-agnostic methods
Model-agnostic xAI (as it’s name suggests) relies solely on analyzing the input-output sets of a model, and therefore can be applied to a wide range of machine learning models regardless of model structure or type. It can be thought of as (very loosely) as sensitivity analysis, but applied to AI methods (for more information on this discussion, please refer to Scholbeck et al. (2023) and Razavi et al. (2021)). SHAP and LIME both fall under this set of methods, and approximately abide by the following process: perturb the input then identify how the output is changed. Note that this set of methods provide little insight as to the specifics of model formulation and how it affects model predictions. Nonetheless, it affords a higher degree of flexibility, and does not bind you to one specific model.
Why does this matter?
Let’s think about this in the context of water resources systems management and planning. Assume you are a water utility responsible for ensuring that you reliably deliver water to 280,000 residents on a daily basis. In addition, you are responsible for planning the next major water supply infrastructure project. Using a machine learning model to inform your short- and long-term management and planning decisions without interrogating how it arrived at its recommendations implicitly assumes that the model will make sensible decisions that balance all stakeholders’ needs while remaining equitable. More often than not, this assumption can be incorrect and may lead to (sometimes funny but mostly) unintentional detrimental cascading implications on the most vulnerable (for some well-narrated examples of how ML went awry, please refer to Brian Christian’s “The Alignment Problem”).
Having said that, using xAI as a next step in the general framework of adopting AI into our decision-making processes can help us better understand why a model makes its predictions, how those predictions came to be, and their degree of usefulness to a decision maker. In this post, I will be demonstrating the use of LIME to answer the following questions.
The next section will establish the three components we will need to apply LIME to our problem:
- An input (feature) set and the training dataset
- The model predictions
- The LIME explainer
A quick example using the North Carolina Research Triangle
The input (feature) set and training dataset
The Research Triangle region in North Carolina consists of six main water utilities that deliver water to their namesake cities: OWASA (Orange County), Durham, Cary, Raleigh, Chatham, and Pittsboro (Gold et al., 2023). All utilities have collaboratively decided that they will each measure their system robustness using a satisficing metric (Starr 1962; Herman et al. 2015), where they satisfy their criteria for robustness if the following criteria are met:
- Their reliability meets or exceeds 98%
- Their worst-case cost of drought mitigation actions amount to no more than 10% of their annual volumetric revenue
- They do not restrict demand more than 20% of the time
If all three criteria are met, then they are considered “successful” (represented as a 1). Otherwise, they have “failed” (represented as a 0). We have 1,000 training data points of success or failure, each representing a state of the world (SOW) in which a utility fails or succeeds to meet their satisficing critieria. This is our training dataset. Each SOW consists of a unique combination of features that include inflow, evaporation and water demand Fourier series coefficients, as well as socioeconomic, policy and infrastructure construction factors. This is our feature set.
Feel free to follow along this portion of the post using the code available in this Google Colab Notebook.
The model prediction
To generate our model prediction, let’s first code up our model. In this example, we will be using Extreme Gradient Boosting, otherwise known as XGBoost (xgboost) as our prediction model, and the LIME package. Let’s first install the both of them:
pip install lime
pip install xgboost
We will also need to import all the needed libraries:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import lime
import lime.lime_tabular
import xgboost as xgb
from copy import deepcopy
Now let’s set up perform XGBoost! We will first need to upload our needed feature and training datasets:
satisficing = pd.read_csv('satisficing_all_utilites.csv')
du_factors = pd.read_csv('RDM_inputs_final_combined_headers.csv')
# get all utility and feature names
utility_names = satisficing.columns[1:]
du_factor_names = du_factors.columns
There should be seven utility names (six, plus one that represents the entire region) and thirteen DU factors (or feature names). In this example, we will be focusing only on Pittsboro.
# select the utility
utility = 'Pittsboro'
# convert to numpy arrays to be passed into xgboost function
du_factors_arr = du_factors.to_numpy()
satisficing_utility_arr = satisficing[utility].values
# initialize the figure object
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
perform_and_plot_xbg(utility, ax, du_factors_arr, satisficing_utility_arr, du_factor_names)

Note the perform_and_plot_xgb function being used – this function is not shown here for brevity, but you can view the full version of this function in this Google Colab Notebook.
The figure above is called a factor map that shows mid-term (Demand2) and long-term (Demand3) demand growth rates on its x- and y-axes respectively. The green denotes the range of demand growth rates where XGBoost has predicted that Pittsboro will successfully meet its satisficing criteria, and brown is otherwise. Each point is a sample from the original training dataset, where the color (white is 1 – success, and red is 0 – failure) denotes whether Pittsboro actually meets its satisficing criteria. In this case we can see that Pittsboro quickly transitions in failure when its mid- and long-term demand are both higher than expected (indicated by the 1.0-value on both axes).
The LIME explainer

Before we perform LIME, let’s first select an interesting point using the figure above.
In the previous section, we can see that the XGBoost algorithm predicts that Pittsboro’s robustness is affected most by mid-term (Demand2) and long-term (Demand3) demand growth. However, there is a point (indicated using the arrow and the brown circle below) where this prediction did not match the actual data point.
To better understand why then, this specific point was predicted to be a “successful” SOW where the true datapoint had it labeled as a “failure” SOW, let’s take a look at how the XGBoost algorithm made its decision.
First, let’s identify the index of this point:
# select an interesting point
interesting_point_range_du = du_factors[(du_factors['Demand2'] < 0) & (du_factors['Demand3'] < 0)].index
interesting_point_satisficing = satisficing_utility_arr[interesting_point_range_du]
interesting_point_range_sat = np.where(satisficing_utility_arr == 0)
interesting_point = np.intersect1d(interesting_point_range_du, interesting_point_range_sat)[0]
This will return an index of 704. Next, we’ll run LIME to break down the how this (mis)classification was made:
# instantiate the lime explainer
explainer = lime_tabular.LimeTabularExplainer(du_factors_arr,
mode='classification',
feature_names=du_factor_names)
# explain the interesting instance
exp = explainer.explain_instance(du_factors_arr[interesting_point_selected],
xgb_model.predict_proba,
num_features=len(du_factor_names))
exp.show_in_notebook(show_table=True)
The following code, if run successfully, should result in the following figure.


Here’s how to interpret it:
- The prediction probability bars on the furthest left show the model’s prediction. In this case, the XGBoost model classifies this point as a “failure” SOW with 94% confidence.
- The tornado plot in the middle show the feature contributions. In this case, it shows the degree to which each SOW feature influenced the decision. In this case, the model misclassified the data point as a “success” although it was a failure as our trained model only accounts for the top two overall features that influence the entire dataset to plot the factor map, and did not account for short-term demand growth rates (
Demand1) and the permitting time required for constructing the water treatment plant (JLWTP permit). - The table on the furthest right is the table of the values of all the features of this specific SOW.
Using LIME has therefore enabled us to identify the cause of XGBoost’s misclassification, allowing us to understand that the model needed information on short-term demand and permitting time to make the correct prediction. From here, it is possible to further dive into the types of SOWs and their specific characteristics that would cause them to be more vulnerable to short-term demand growth and infrastructure permitting time as opposed to mid- and long-term demand growth.
Summary
Okay, so I lied a bit – it wasn’t quite so “brief” after all. Nonetheless, I hope you learned a little about explainable AI, how to use LIME, and how to interpret its outcomes. We also walked through a quick example using the good ol’ Research Triangle case study. Do check out the Google Colab Notebook if you’re interested in how this problem was coded.
With that, thank you for sticking with me – happy learning!
References
Amazon Web Services. (1981). What’s the Difference Between AI and Machine Learning? Machine Learning & AI. https://aws.amazon.com/compare/the-difference-between-artificial-intelligence-and-machine-learning/
Btd. (2024, January 7). Explainable AI (XAI): Model-specific interpretability methods. Medium. https://baotramduong.medium.com/explainable-ai-model-specific-interpretability-methods-02e23ebceac1
Christian, B. (2020). The alignment problem: Machine Learning and human values. Norton & Company.
Gold, D. F., Reed, P. M., Gorelick, D. E., & Characklis, G. W. (2023). Advancing Regional Water Supply Management and infrastructure investment pathways that are equitable, robust, adaptive, and cooperatively stable. Water Resources Research, 59(9). https://doi.org/10.1029/2022wr033671
Herman, J. D., Reed, P. M., Zeff, H. B., & Characklis, G. W. (2015). How should robustness be defined for water systems planning under change? Journal of Water Resources Planning and Management, 141(10). https://doi.org/10.1061/(asce)wr.1943-5452.0000509
Holzinger, A., Saranti, A., Molnar, C., Biecek, P., & Samek, W. (2022). Explainable AI methods – A brief overview. xxAI – Beyond Explainable AI, 13–38. https://doi.org/10.1007/978-3-031-04083-2_2
IBM Data and AI Team. (2023, October 16). Understanding the different types of artificial intelligence. IBM Blog. https://www.ibm.com/blog/understanding-the-different-types-of-artificial-intelligence/
Sarker, I. H. (2022, February 10). AI-based modeling: Techniques, applications and research issues towards automation, intelligent and Smart Systems – SN Computer Science. SpringerLink. https://link.springer.com/article/10.1007/s42979-022-01043-x#Sec6
Scholbeck, C. A., Moosbauer, J., Casalicchio, G., Gupta, H., Bischl, B., & Heumann, C. (2023, December 20). Position paper: Bridging the gap between machine learning and sensitivity analysis. arXiv.org. http://arxiv.org/abs/2312.13234
Starr, M. K. (1963). Product design and decision theory. Prentice-Hall, Inc.

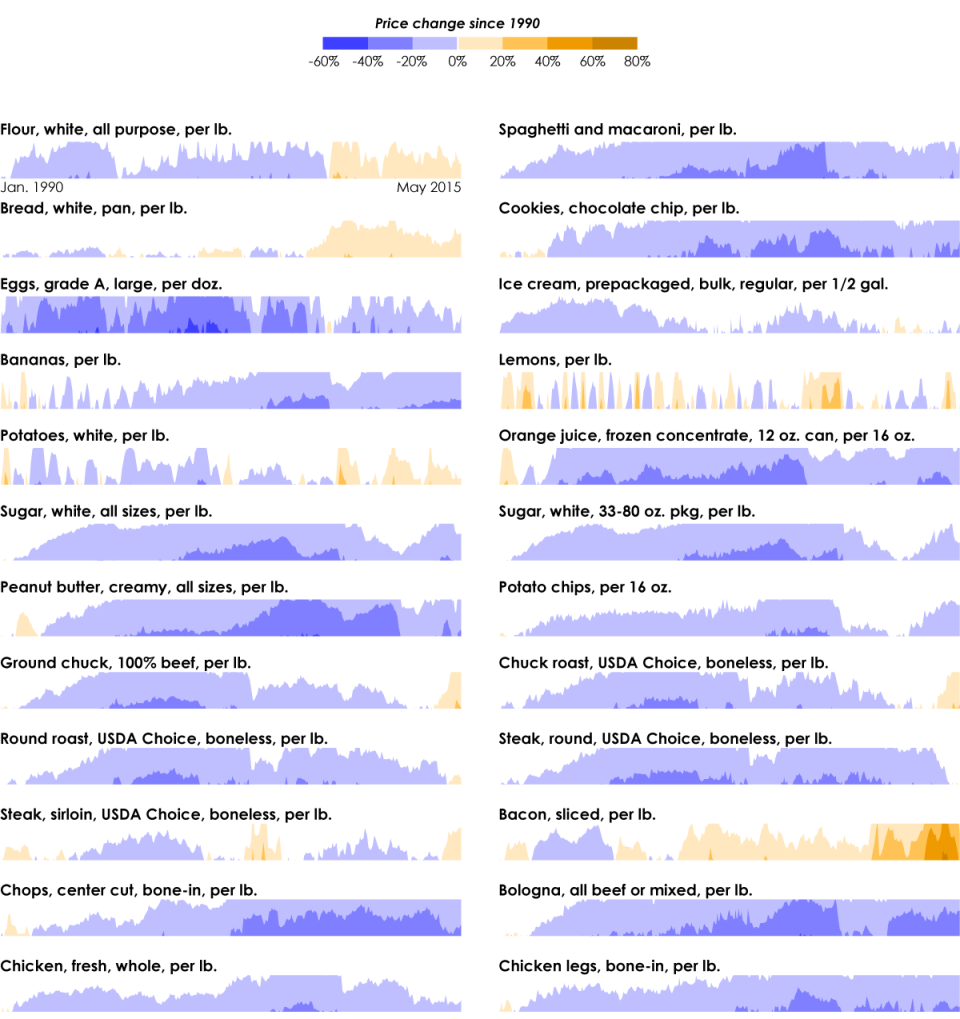
 is the number of policy inputs
is the number of policy inputs is the number of policy outputs
is the number of policy outputs is the number of radial basis functions (RBFs) used
is the number of radial basis functions (RBFs) used is a day within the entire record, while $t\%365$ is a calendar year (day of year, DOY)
is a day within the entire record, while $t\%365$ is a calendar year (day of year, DOY) is the number of reservoirs
is the number of reservoirs is the policy-prescribed release at reservoir $k$ at time $t$
is the policy-prescribed release at reservoir $k$ at time $t$ is the system state, aka the storage at the reservoir
is the system state, aka the storage at the reservoir is a vector of system variables for state $a$
is a vector of system variables for state $a$ and $b_{n,m}$ are the centers and radii of policy input $m \in M$ for RBF function $n \in N$
and $b_{n,m}$ are the centers and radii of policy input $m \in M$ for RBF function $n \in N$ is the weight of RBF function $n \in N$
is the weight of RBF function $n \in N$
 .
.
 to the system states at
to the system states at  . But how do we calculate the derivatives of the policy
. But how do we calculate the derivatives of the policy ![\frac{\delta u_{t}^{k}}{\delta(x_t)_a} = \sum_{n=1}^{N}\Biggl\{\frac{-2w_{n}[(x_{t})_{a}-c_{n,a}]}{b_{n,a}^2}\text{ exp}\Biggl[-\sum_{m=1}^{M}\Bigl(\frac{(x_{t})_{j}-c_{n,m}}{b_{n,m}}\Bigr)^2\Biggr]\Biggr\}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cdelta+u_%7Bt%7D%5E%7Bk%7D%7D%7B%5Cdelta%28x_t%29_a%7D+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7D%5CBiggl%5C%7B%5Cfrac%7B-2w_%7Bn%7D%5B%28x_%7Bt%7D%29_%7Ba%7D-c_%7Bn%2Ca%7D%5D%7D%7Bb_%7Bn%2Ca%7D%5E2%7D%5Ctext%7B+exp%7D%5CBiggl%5B-%5Csum_%7Bm%3D1%7D%5E%7BM%7D%5CBigl%28%5Cfrac%7B%28x_%7Bt%7D%29_%7Bj%7D-c_%7Bn%2Cm%7D%7D%7Bb_%7Bn%2Cm%7D%7D%5CBigr%29%5E2%5CBiggr%5D%5CBiggr%5C%7D&bg=ffffff&fg=444444&s=0&c=20201002)
![u_{t}^{k} = \sum_{n=1}^{N}w_{n}^{k}\text{ exp}\Biggr[-\sum_{m=1}^{M}\Biggl(\frac{(x_n)_m - c_{n,m}}{b_{n,m}}\Biggr)^2\Biggr]](https://s0.wp.com/latex.php?latex=u_%7Bt%7D%5E%7Bk%7D+%3D+%5Csum_%7Bn%3D1%7D%5E%7BN%7Dw_%7Bn%7D%5E%7Bk%7D%5Ctext%7B+exp%7D%5CBiggr%5B-%5Csum_%7Bm%3D1%7D%5E%7BM%7D%5CBiggl%28%5Cfrac%7B%28x_n%29_m+-+c_%7Bn%2Cm%7D%7D%7Bb_%7Bn%2Cm%7D%7D%5CBiggr%29%5E2%5CBiggr%5D&bg=ffffff&fg=444444&s=0&c=20201002)
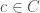 and radii
and radii  for each input variable, and a weight
for each input variable, and a weight 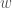 . It is a type of Gaussian process kernel that informs the model (in our case, the Red River model) of the degree of similarity between two input points (Natsume, 2022). Each input is shifted by its distance from its respective “optimal” center point, and scaled by its “optimal” radius. The overall influence of an RBF function on the final release decision is then weighted by an “optimal” constant, where the sum of all
. It is a type of Gaussian process kernel that informs the model (in our case, the Red River model) of the degree of similarity between two input points (Natsume, 2022). Each input is shifted by its distance from its respective “optimal” center point, and scaled by its “optimal” radius. The overall influence of an RBF function on the final release decision is then weighted by an “optimal” constant, where the sum of all  ,
,  across all following timesteps, and avoiding the storage of information on prior releases
across all following timesteps, and avoiding the storage of information on prior releases  .
. over all years. In this case, the timestep is in daily increments.
over all years. In this case, the timestep is in daily increments. ).
).