
Conditioning Synthetic Weather Generation on Seasonal Climate Forecasts
This is the final blog post in a five part series on synthetic weather generators. See Parts I and II for a description of single-site parametric and non-parametric generators, respectively, and Part III for a description of multi-site generators of both types.
In my previous post, Part IV, I discussed how parametric and non-parametric weather generators can be modified to produce weather that is consistent with climate change projections for use in long-term planning. In the shorter-term, water managers may be able to exploit mid-range climate forecasts to inform seasonal reservoir operations (see e.g., Kim and Palmer (1997), Chiew et al. (2003), Block (2011), Block and Goddard (2012), Anghileri et al. (2016)). For such analyses, it could be useful to tailor management plans to simulated weather conditions consistent with these probabilistic forecasts. Here I discuss how one can condition weather generators on seasonal climate forecasts for such purposes.
Two major forecasting groups, the International Research Institute (IRI) for Climate and Society at Columbia University and the Climate Prediction Center (CPC) of the U.S. National Centers for Environmental Prediction, issue tercile seasonal forecasts that specify the probabilities of observing above normal (pA), near normal (pN) and below normal (pB) precipitation and temperature. Forecasts are issued each month for the upcoming three months (see those from IRI and CPC). While these forecasts are derived from dynamical and statistical models that include a variety of physically-based processes, most of the forecast skill can be explained by the effects of the El Niño-Southern Oscillation (ENSO) on the climate system (Barnston et al., 1994). As most of you probably know, ENSO refers to the quasi-periodic cycling of sea surface temperatures (SSTs) in the tropical eastern Pacific Ocean. The warm phase is known as El Niño and the cool phase as La Niña. These are quantified as five consecutive three-month periods with SST anomalies in the Niño 3.4 region of the Pacific > +0.5°C (El Niño) or < -0.5°C (La Niña). All other periods are considered neutral (Climate Prediction Center, 2016). Because much of seasonal climate forecast skill is derived from ENSO, current or forecasted SST anomalies in the Niño 3.4 region are sometimes used by themselves as proxy seasonal forecasts. Here I will discuss techniques for conditioning weather generator parameters on either tercile forecasts or current or projected ENSO conditions.
Parametric Weather Generators
Wilks (2002) presents a method for conditioning parametric weather generators of the Richardson (1981) type on tercile seasonal climate forecasts using a network of sites in New York State. The key idea, derived from Briggs and Wilks (1996), is to estimate the weather generator parameters not from the entire historical record, but from a weighted bootstrapped sample of the historical record consistent with the forecast. This is similar to the method of streamflow generation use by Herman et al. (2016) to increase the frequency of droughts of a given magnitude. As an illustrative example, Herman et al. (2016) empirically estimate the quantile of a noteworthy drought from the historical record and show the system impacts of droughts of that magnitude or worse becoming n times more likely. This is done by adapting the semi-parametric streamflow generator developed by Kirsch et al. (2013) to sample years with historical droughts of at least that magnitude n times more often.
While Herman et al. (2016) take a fully non-parametric approach by estimating quantiles empirically, Briggs and Wilks (1996) estimate terciles parametrically by fitting a normal distribution to the historical mean seasonal temperatures and a Gamma distribution to the historical seasonal precipitation totals at each site. After estimating terciles, Briggs and Wilks (1996) classify each year in the historical record as below normal, near normal or above normal in terms of temperature and precipitation in the season of interest. Because terciles are estimated parametrically, each category will not necessarily contain an equal number of years, even if the record length is a multiple of three. It should be noted, however, that like Herman et al. (2016), IRI defines terciles empirically from the most recent 30-yr record (see more here and here) and CPC from the most recent 30-yr record updated only every 10 years, i.e., the current reference frame is 1981-2010 (see more here). IRI provides a discussion of the advantages and disadvantages to parametric and non-parametric tercile estimation methods. For consistency, it may be best to take the same approach as the agency whose forecasts are being used.
Once terciles have been defined, weather generator parameters can be estimated from a bootstrapped sample of the historical record consistent with the forecast (Wilks, 2002). Consider a historical record with NB years classified as being below normal, NN as near normal, and NA as above normal. Then the expected value of a given seasonal statistic, X, can be estimated from a bootstrapped sample of L years from the historical record in which the below normal, near normal and above normal years are sampled with probabilities pB, pN, and pA, respectively. Representing the statistic of interest in the ith below, near and above normal year as xi(B), xi(N) and xi(A), respectively, then the expected value of X is the following:
(1)
![E\left[X\right] = \lim_{L\to\infty} \frac{1}{L}\left[\sum_{i=1}^{N_B} \frac{p_BL}{N_B}x_{i}^{\left(B\right)} + \sum_{i=1}^{N_N} \frac{p_NL}{N_N}x_{i}^{\left(N\right)} + \sum_{i=1}^{N_A} \frac{p_AL}{N_A}x_{i}^{\left(A\right)}\right]](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX%5Cright%5D+%3D+%5Clim_%7BL%5Cto%5Cinfty%7D+%5Cfrac%7B1%7D%7BL%7D%5Cleft%5B%5Csum_%7Bi%3D1%7D%5E%7BN_B%7D+%5Cfrac%7Bp_BL%7D%7BN_B%7Dx_%7Bi%7D%5E%7B%5Cleft%28B%5Cright%29%7D+%2B%C2%A0%5Csum_%7Bi%3D1%7D%5E%7BN_N%7D+%5Cfrac%7Bp_NL%7D%7BN_N%7Dx_%7Bi%7D%5E%7B%5Cleft%28N%5Cright%29%7D+%2B%C2%A0%5Csum_%7Bi%3D1%7D%5E%7BN_A%7D+%5Cfrac%7Bp_AL%7D%7BN_A%7Dx_%7Bi%7D%5E%7B%5Cleft%28A%5Cright%29%7D%5Cright%5D&bg=ffffff&fg=444444&s=0&c=20201002)
That is, the forecast-conditional value of X is a weighted sum of its average in the below normal, near normal and above normal years, where the weights are equal to the forecast probabilities for each of the three respective categories (Wilks, 2002). Note that X is a seasonal statistic, not a parameter, so one cannot simply estimate a weather generator parameter as a weighted average of its value in each of the terciles unless the parameter is itself a simple statistic.
Fortunately, for some of the weather generator parameters this is the case. Recall from Part I that the first step of the Richardson generator is to generate a sequence of daily rainfall occurrences from a first order Markov chain. This chain is defined by the probabilities of transitioning from a dry day to a wet day, p01, or from a wet day to another wet day, p11. As discussed in Part IV, these two parameters together define the unconditional probability of a wet day, π, and the first-order autocorrelation of the occurrences, d, where π = p01/(1 + p01 – p11) and d = p11 – p01 (Katz, 1983). The unconditional probability of a wet day is a simple statistic. Therefore, since pN = 1 – pA – pB, π can be estimated each month as a function of pB, pA and the average portion of wet days in below normal, near normal and above normal years for that month (x̅(B), x̅(N) and x̅(A)):
(2) π = pBx̅(N) + (1 – pB – pA)x̅(N) + pAx̅(A).
More generically, π =b0 + bBpB + bApA, where b0 = x̅(N), bB = x̅(B) – x̅(N) and bA = x̅(A) – x̅(N). Wilks, 2002 recommends that the parameter π be estimated separately at each site and for each month, but that the below normal, near normal and above normal years be defined based on the total precipitation at that site in the entire three-month season. This is because the forecast is for the entire season, but the portion of wet days varies on a shorter time scale.
Like the unconditional probability of a wet day, the persistence parameter d can also be estimated as a function of pB, pA and the value of d in below normal, near normal and above normal years. Wilks (2002) shows that d can be represented by a quadratic function of pA and pB:
(3) d = b0 + bBpB + bBBpB2 + bApA + bAApA2 + bBApBpA.
but finds that variations in d across forecasts are small such that one can reasonably assume the climatological estimate of d for all sites and months, regardless of the forecast.
The remaining weather generator parameters related to precipitation are those defining the distribution of precipitation amounts. Because these parameters (α and β if fitting a Gamma distribution, and α, λ1 and λ2 if fitting a mixed exponential distribution) are estimated iteratively in an MLE approach, they cannot be estimated as a function of the forecast probabilities like the occurrence parameters can. Instead, Wilks (2002) suggests using the Briggs and Wilks (1996) approach of bootstrapping a large sample of years from the historical record consistent with the forecast and fitting separate probability distributions to the precipitation amounts in each month’s weighted sample. When performing this estimation using a mixed exponential distribution to model precipitation amounts, Wilks (2002) found the estimates of the mixing parameter, α, to be the least consistent across the investigated sites and chose to hold it constant across sites and forecasts. Thus, only λ1 and λ2 were re-estimated for each month and site as a function of the seasonal forecast.
One drawback to the sampling scheme employed by Briggs and Wilks (1996) is that all historical years within each tercile have an equal probability of being sampled: pB/NB, pN/NN and pA/NA for below, near and above normal years. In reality, years similar to those in the tail are less likely to occur than years similar to those near the median. An alternative, more precise sampling scheme called the pdf-ratio method suggested by Stedinger and Kim (2010) assigns each year i an un-normalized probability of selection, qi = (1/N)*f1(xi)/f0(xi) where N is the number of years in the historical record and f1 and f0 are pdfs of the statistic X under forecast and climatological conditions, respectively. The qi are then normalized such that they sum to 1. f1 and f0 can be analytical or empirical distributions.
After estimating parameters of the precipitation amounts distributions using either the approach of Briggs and Wilks (1996) or Stedinger and Kim (2010), one must estimate the forecast-conditional temperature parameters. Recall that in the Richardson generator, separate harmonics are fit to the eight time series of means and standard deviations of minimum and maximum temperature on wet and dry days. Historical residuals from these fits are determined by first subtracting the predicted mean and then dividing by the predicted standard deviation. Finally, the residuals are modeled by an order-one vector autoregression, or VAR(1) model. Because forecast-conditional weather generators are only applied three months at a time, Wilks (2002) suggests instead fitting quadratic functions to these eight time series within the season of interest.
Like the parameters describing precipitation occurrences, the parameters of the quadratic functions of time describing the mean temperature on wet and dry days can be estimated as a weighted average of fits in each of the three terciles. As shown in Wilks (2002), the four mean temperature functions (minimum and maximum on wet and dry days), µ(t), at each site are specified by the function:
(4) µ(t) = (β0 + βBpB + βApA) + (γ0 + γBpB + γApA)t + (δ0 + δBpB + δApA)t2
where
(5) µ̅t(N) = β0 + γ0t + δ0t2,
(6) [µ̅t(B) – µ̅t(N)] = βB + γBt + δBt2,
(7) [µ̅t(A) – µ̅t(N)] = βA + γAt + δAt2,
t is the day and µ̅t(B), µ̅t(N) and µ̅t(A) are the mean temperature statistics of concern on each day of below normal, near normal and above normal years in the historical record, respectively.
Finally, Wilks (2002) shows that the standard deviations of minimum and maximum temperature on wet and dry days can be estimated by an extension of Equation 1:
(8)
![s\left(t\right) = \left[\frac{p_B}{N_B}\sum_{i=1}^{N_B}\left[x_{i}^{\left(B\right)}\left(t\right) - \mu\left(t\right)\right]^2 + \frac{p_N}{N_N}\sum_{i=1}^{N_N}\left[x_{i}^{\left(N\right)}\left(t\right) - \mu\left(t\right)\right]^2 + \frac{p_A}{N_A}\sum_{i=1}^{N_A}\left[x_{i}^{\left(A\right)}\left(t\right) - \mu\left(t\right)\right]^2\right]^{1/2}](https://s0.wp.com/latex.php?latex=s%5Cleft%28t%5Cright%29+%3D+%5Cleft%5B%5Cfrac%7Bp_B%7D%7BN_B%7D%5Csum_%7Bi%3D1%7D%5E%7BN_B%7D%5Cleft%5Bx_%7Bi%7D%5E%7B%5Cleft%28B%5Cright%29%7D%5Cleft%28t%5Cright%29+-+%5Cmu%5Cleft%28t%5Cright%29%5Cright%5D%5E2+%2B+%5Cfrac%7Bp_N%7D%7BN_N%7D%5Csum_%7Bi%3D1%7D%5E%7BN_N%7D%5Cleft%5Bx_%7Bi%7D%5E%7B%5Cleft%28N%5Cright%29%7D%5Cleft%28t%5Cright%29+-+%5Cmu%5Cleft%28t%5Cright%29%5Cright%5D%5E2+%2B+%5Cfrac%7Bp_A%7D%7BN_A%7D%5Csum_%7Bi%3D1%7D%5E%7BN_A%7D%5Cleft%5Bx_%7Bi%7D%5E%7B%5Cleft%28A%5Cright%29%7D%5Cleft%28t%5Cright%29+-+%5Cmu%5Cleft%28t%5Cright%29%5Cright%5D%5E2%5Cright%5D%5E%7B1%2F2%7D&bg=ffffff&fg=444444&s=0&c=20201002)
where µ(t) is defined as in Equation 4. Once again, the forecast-conditional standard deviations of the four temperature series, σ(t), can then be estimated by quadratic functions of time, conditional on the forecast probabilities pA and pB:
(9) σ(t) = (β0 + βBpB + βBBpB2 + βApA + βAApA2 + βBApBpA)+ (γ0 + γBpB + γBBpB2 + γApA + γAApA2 + γBApBpA)t + (δ0 + δBpB + δBBpB2 + δApA + δAApA2 + δBApBpA)t2.
For the VAR(1) model of temperature residuals, Wilks (2002) found that variations in the estimates of these parameters as a function of the forecast, like d, were minor for the investigated sites in New York. For this reason, the VAR(1) model was fit separately for each month and site based on the entire historical record and these estimates were unchanged with the forecast. Finally, Wilks (2002) found that the spatial correlation of temperature and precipitation also did not change significantly between climatic terciles, and so they too were assumed independent of the forecast. Correlations in temperature were included in the VAR(1) model as described in Part III. Correlations in precipitation occurrences ω, and amounts, ζ, between sites k and l were approximated for all site pairs each month as a function of the horizontal distance, c, between them (see Equations 10 and 11, respectively, for which parameters θ1, θ2 and θ3 were estimated).
(10)

(11)
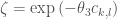
If one received a tercile ENSO forecast, the same approach could be used as in Wilks (2002), except the season of interest in each historical year would be classified as La Niña, Neutral or El Niño instead of below normal, near normal or above normal.
Non-parametric Weather Generators
The key idea of weighted sampling from Briggs and Wilks (1996) has also been applied in non-parametric weather generators to condition synthetic weather series on seasonal climate forecasts. For example, Apipattanavis et al. (2007) modify their semi-parametric k-nn generator to find and probabilistically select neighbors, not from the entire historical record, but from a bootstrapped sample of the historical record consistent with the forecast. Again, this can be applied using tercile forecasts of either the {Below Normal, Near Normal, Above Normal} type or {La Niña, Neutral, El Niño} type.
Clark et al. (2004a) develop a more innovative approach that combines ideas from the non-parametric Schaake Shuffle method used to spatially correlate short-term precipitation and temperature forecasts (Clark et al., 2004b) with a parametric approach to weighted resampling presented by Yates et al. (2003) for the k-nn generator of Rajagopalan and Lall (1999). The Schaake Shuffle, originally devised by Dr. J. Schaake of the National Weather Service Office of Hydrologic Development, is a method of reordering ensemble precipitation and temperature forecasts to better capture the spatial and cross correlation of these spatial fields (Clark et al., 2004b).
Traditionally, model output statistics (MOS) from the Numerical Weather Prediction (NWP) model such as temperature, humidity and wind speed at different pressure levels, are used as predictors in a regression model to forecast daily temperature and precipitation at a number of sites. To generate an ensemble of predictions for each forecasted day, normal random variables with mean 0 and variance σε2 are added back to the mean prediction, where σε2 is the variance of the regression residuals. However, these regressions are generally developed independently for each variable at each site and therefore do not reproduce the spatial or temporal correlation between the variables across sites and time (Clark et al., 2004b). To better capture these correlations, the Schaake Shuffle, illustrated in Figure 2 from Clark et al. (2004a) for a 10-member ensemble, re-orders the ensemble members each day in order to preserve the Spearman-rank correlation in the temperature and precipitation variables between sites.

The Schaake Shuffle proceeds as follows. For a particular day, the original ensemble members for each variable at each station are ranked from lowest to highest, as shown in Table A of Figure 2 above. Next, a set of historical observations of the same size is generated by randomly selecting days from the historical record within a window of 7 days before and after the forecast date (Table B). Third, the historical observations are sorted from lowest to highest for each variable at each site, as shown in Table C. Finally, the original ensemble members in Table A are re-shuffled to form the final, spatially correlated ensembles in Table D in the following way:
- The rank of the data in the first historical observation (shown with dark circles in Tables B and C) is determined at each site
- At each site, the member of the original ensemble with the same rank as the first historical observation for that site becomes the first member of the final, correlated ensemble (see dark circles in Table A and location in Table D).
- Steps 1 and 2 are repeated for every historical observation/ensemble member.
As stated earlier, this process reproduces the Spearman rank correlation of the observations across sites (Clark et al., 2004b). In order to preserve the temporal correlation for each variable, instead of re-generating a random set of historical observations to use for shuffling the next day’s forecast, the observations from the day following that used for the previous time step is utilized. While the Schaake Shuffle does not guarantee reproduction of the spatial correlation in the observations, just in their rank, the results presented in Clark et al. (2004b) indicate that the method does reasonably well for both, and significantly improves upon the un-shuffled forecasts.
In the weather generator presented by Clark et al. (2004a), the same approach is used to simulate weather sequences except the ensembles in Table A are not generated by MOS regressions but by independently sampling historical observations within +/- 7 days of the simulated day at each site. To condition this weather generator on seasonal climate forecasts, the unshuffled ensembles are formed by preferential selection of different years from the historical record following an approach inspired by Yates et al. (2003). The first step in this approach is to sort all N historical years in terms of their similarity to a climate index, such as current SSTs in the Niño 3.4 region. The most similar year is given rank i = 1 and the least similar i = N. Next, a standard uniform random variable u is drawn and the year of rank i is chosen as an ensemble member, where i = INT(uλN/α) + 1. Here INT(·) is the integer operator, λ is a weighting parameter, and α a selection parameter. Values of λ greater (less) than 1 increase (decrease) the probability of selecting years ranked more similar to the climate index. Values of α greater than 1 restrict the number of sampled years such that α = 5, for example, results in only the most similar 1/5 of years being selected (Clark et al., 2004a).
Yates et al. (2003) apply a simplified version of this method with only one parameter, λ, in a scenario discovery-type approach, investigating the effects of e.g. warmer-drier springs and cooler-wetter summers. Clark et al. (2004a) first take this approach by ranking the historical years according to their similarity to the current Niño 3.4 index and exploring the effects of different choices of λ and α on the skill of the generated weather sequences in forecasting total winter precipitation at Petrified Forest in Arizona, measuring skill by the ranked probability skill score (RPSS). Interestingly, they find that high values of both λ and α, where years more similar to the climate index at the beginning of the season are selected, result in negative forecast skill. This highlights the importance of not being overconfident by only sampling years closest to current or forecast conditions. They note that the values of λ and α should depend on the strength of the Niño 3.4 index, and therefore should be re-optimized for different values of the index in order to maximize the RPSS.
All of these approaches could prove informative for seasonal water resources planning, if the forecasts being used are reliable. In the case of tercile forecasts, this means that, on average, when a given climate state is forecast to occur with probability p, it does in fact occur with that probability. Given that past diagnostic assessments of IRI and CPC forecasts have found biases and overconfidence in some locations (Wilks and Godfrey, 2002; Wilks, 2000), water managers should proceed with caution in using them for seasonal planning. At a minimum, one should perform an analysis of the forecast value for the system of concern (Anghileri et al., 2016) before changing system operations. Fortunately, these forecasts continue to improve over time and several studies have already found value in using them to inform seasonal operations (e.g. Kim and Palmer (1997), Block (2011), Block and Goddard (2012), Anghileri et al. (2016)), indicating promise in their use for water resources planning.
Works Cited
Anghileri, D. Voisin, N., Castelletti, A., Pianosi, A., Nijssen, B., & Lettenmaier, D. P. (2016). Value of long-term streamflow forecasts to reservoir operations for water supply in snow-dominated river catchments. Water Resources Research, 52(6), 4209-4225.
Apipattanavis, S., Podestá, G., Rajagopalan, B., & Katz, R. W. (2007). A semiparametric multivariate and multisite weather generator. Water Resources Research, 43(11).
Barnston, A. G., van den Dool, H. M., Rodenhuis, D. R., Ropelewski, C. R., Kousky, V. E., O’Lenic, E. A., et al. (1994). Long-lead seasonal forecasts-Where do we stand?. Bulletin of the American Meteorological Society, 75(11), 2097-2114.
Block, P. (2011). Tailoring seasonal climate forecasts for hydropower operations. Hydrology and Earth System Sciences, 15, 1355-1368.
Block, P., & Goddard, L. (2012). Statistical and dynamical climate predictins to guide water resources in Ethiopoia. Journal of Water Resources Planning and management, 138(3), 287-298.
Briggs, W. M., & Wilks, D. S. (1996). Extension of the Climate Prediction Center long-lead temperature and precipitation outlooks to general weather statistics. Journal of climate, 9(12), 3496-3504.
Chiew, F. H. S., Zhou, S. L., & McMahon, T. A. Use of seasonal streamflow forecasts in water resources management. Journal of Hydrology, 270(1), 135-144.
Clark, M. P., Gangopadhyay, S., Brandon, D., Werner, K., Hay, L., Rajagopalan, B., & Yates, D. (2004a). A resampling procedure for generating conditioned daily weather sequences. Water Resources Research, 40(4).
Clark, M., Gangopadhyay, S., Hay, L., Rajagopalan, B., & Wilby, R. (2004b). The Schaake shuffle: A method for reconstructing space-time variability in forecasted precipitation and temperature fields. Journal of Hydrometeorology, 5(1), 243-262.
Climate Prediction Center (2016). ENSO: Recent Evolution, Current Status and Predictions. National Oceanic and Atmospheric Administration, pp. 19-20.
Herman, J. D., Zeff, H. B., Lamontagne, J. R., Reed, P. M., & Characklis, G. W. (2016). Synthetic drought scenario generation to support bottom-up water supply vulnerability assessments. Journal of Water Resources Planning and Management, 04016050.
Katz, R. W. (1983). Statistical procedures for making inferences about precipitation changes simulated by an atmospheric general circulation model. Journal of the Atmospheric Sciences, 40(9), 2193-2201.
Kim, Y., & Palmer, R. (1997). Value of seasonal flow forecasts in Bayesian stochastic programming. Journal of Water Resources Planning and Management, 123(6), 327-335.
Kirsch, B. R. , Characklis, G. W., & Zeff, H. B. (2013). Evaluating the impact of alternative hydro-climate scenarios on transfer agreements: Practical improvement for generating synthetic streamflows. Journal of Water Resources Planning and Management, 139(4), 396-406.
Rajagopalan, B., & Lall, U. (1999). A k‐nearest‐neighbor simulator for daily precipitation and other weather variables. Water Resources Research, 35(10), 3089-3101.
Richardson, C. W. (1981). Stochastic simulation of daily precipitation, temperature and solar radiation. Water Resources Research, 17, 182-190.
Stedinger, J. R., & Kim, Y. O. (2010). Probabilities for ensemble forecasts reflecting climate information. Journal of hydrology, 391(1), 9-23.
Wilks, D. S. (2000). Diagnostic verification of the Climate Prediction Center long-lead outlooks, 1995-1998. Journal of Climate, 13, 2389-2403.
Wilks, D. S. (2002). Realizations of daily weather in forecast seasonal climate. Journal of Hydrometeorology, 3(2), 195-207.
Wilks, D. S. & Godfrey, C. M. (2002). Diagnostic verification of the IRI net assessment forecasts, 1997-2000. Journal of Climate, 15(11), 1369-1377.
Yates, D., Gangopadhyay, S., Rajagopalan, B., & Strzepek, K. A technique for generating regional climate scenarios using a nearest-neighbor algorithm. Water Resources Research, 39(7).




