
Recently I’ve been learning to view the world in frequencies and amplitudes instead of time and magnitudes, also known as Fourier-domain time series analysis. It’s become a rather popular method in the field of water supply planning, with applications in forecasting demand and water quality control. While this post will not delve into advanced applications, we will walk through some fundamental time series concepts to ease you into the Fourier Domain. I will then demonstrate how time series analysis can be used to identify long- and short-term trends in inflow data.
Important frequencies
When reviewing time series analysis, there are three fundamental frequencies to remember:
- The sampling frequency,
is the frequency at which data for a time series is collected. It is equivalent to the inverse of the time difference between two consecutive data points,
. It has units of Hertz (
). Higher values of
- The Nyquist frequency,
is equal to
. As a rule of thumb, you should sample your time series at a frequency
, as sampling at a higher frequencies will result in the time series signals overlapping. This is a phenomenon called aliasing, where the sampled points do not sufficiently represent the input signal, resulting in higher frequencies being incorrectly observed at lower frequencies (Ellis, 2012)
- The cutoff frequency,
. The value of
Filtering
Filtering does exactly what its name implies it does. It allows certain signal frequencies to pass through, filtering out the rest. There are three main types of filters:
- Low-pass filter: A low-pass filter eliminates all frequencies above
- High-pass filter: Unlike the low-pass filter, the high-pass filter eliminates all frequencies below
- Band-pass filter: This filter has both the properties of a low- and high-pass filter. It eliminates all frequencies that do not lie within a range of frequencies.
Windowing
The core idea behind windowing is that is is possible to obtain more detailed insight into your signal’s properties by dividing it into ‘windows’ of time. Windowing is useful to reduce artifacts in a signal caused by periodic extension, and the distinction between signal and noise becomes unclear. For particularly noisy signals, windowing can also be useful to amplify the signal-to-noise ratio, thereby making it easier to distinguish between the actual signal and white noise. This is possible as the large ‘main lobe’ of the window (both in the time and frequency domain), amplifies the lower-frequency, higher-amplitude signal, but dampens the higher-frequency, lower-amplitude noise.

Spectrograms
There is a key issue when analyzing a time series in the Fourier domain, and vice versa – there is no way (as of right now) to view when or where a specific frequency occurs, or which frequencies dominate at any specific time. A spectrogram (or the Short-Time Fourier Transform, STFT) of a signal address this issue by consolidating three types of information into one visualization:
- The frequencies inherent to the signal
- How the frequencies change over time
- The relative strength of the frequencies (the frequency content or “power” of the frequency).
It allows us to view changes in the signal across both time and frequency, overcoming the limitation of only being applicable to stationary time series. However, it still applies a fixed window size, as we will see in a little bit, and cannot fully capture all the different frequencies that characterize a signal. Here, using wavelets is useful. Please refer to Rohini’s post on using wavelets on ENSO El Niño data here if you’re interested! On that note, let’s see how we can bring it all in with a quick demonstration!
Demonstrating basic time series analysis methods on an inflow timeseries
This demonstration will use MATLAB, and we begin by first loading and plotting a time series of weekly inflow data. Feel free to replace the inflow file with any time series you have on hand!
%%
% Read in and plot inflows of Jordan Lake in the Research Triangle
inflows_jl = readmatrix('jordan_lake_inflows.csv');
inflows_jl = inflows_jl(1,:);
% define sampling rate, Nyquist frequency, number of samples, sampling period, and frequency series
fs_inflow = 1/(7*24*3600);
N = length(inflows_jl);
delta_t = 1/fs_inflow;
freqseries_inflow = (1/(N*delta_t))*(0:(N-1));
fNy = fs_inflow/2;
%% Plot the inflow time series
figure(1)
plot(inflows_jl, 'Color','#104E8B');
grid on
xlabel('Time (weeks)');
ylabel('Inflow (MGD)');
xlim([0 5200]); ylim([0 15e4]);
title('Jordan Lake inflow timeseries');
The output figure should look similar to this:

Next, we Fourier Transform the inflow time series using the MATLAB fft() function, then convert it’s amplitude to decibels by first applying the abs() function, and then the mag2db() function to the output of the Fourier Transform.
%% Perform and plot the FFT of inflow
fft_jl = abs(fft(inflows_jl));
figure(2)
loglog(freqseries_inflow, mag2db(fft_jl), '-ko', 'Color','#104E8B', 'MarkerSize',2);
grid on
xlabel('Frequency (Hz)');
ylabel('Amplitude (dB)');
title("FFT of Jordan Lake");
This returns the following plot:

Note the large spikes in Figure 3. Those indicate frequencies that result in large inflow events. In this blog post, we will focus on the two leftmost spikes: the four-year cycle and the annual cycle, shown below. These cycles were identified by first converting their frequencies into seconds, and then into weeks and years.

We also want to confirm that these frequencies characterize the time series. To verify this, we apply a low-pass Butterworth filter:
%% Number of weeks in a year
num_weeks = 52.1429;
% Record the low-pass cutoff frequencies
fcut1_jl = 8.40951e-9;
years1_jl = conv2weeks(1/fcut1_jl)/num_weeks;
fcut2_jl = 3.16974e-8;
years2_jl = conv2weeks(1/fcut2_jl)/num_weeks;
% Set up the filters and apply to the inflow time series
[b1_fl, a1_fl] = butter(6,fcut1_fl/(fs_inflow/2));
inflows_filtered_fl1 = filter(b1_fl, a1_fl, inflows_jl);
[b2_fl, a2_fl] = butter(6,fcut2_fl/(fs_inflow/2));
inflows_filtered_fl2 = filter(b2_fl, a2_fl, inflows_jl);
%% Plot the filtered inflow time series
figure(3)
plot(inflows_jl, 'Color','#104E8B', 'DisplayName', 'Original', 'LineWidth',2);
xlim([0 5200]);
ylim([0 15e4]);
xlabel('Time (Years)');
ylabel('Inflows (MGD)');
title('Jordan Lake 4-year cycle')
legend();
hold on
plot(inflows_filtered_jl1,'Color','#D88037', 'MarkerSize',2, 'DisplayName', '4-year cycle', 'LineWidth',2);
hold off
ticklocations = 0:520:5112;
xticks(ticklocations);
ticklabels = string(ticklocations);
ticklabels(mod(ticklocations, 520) ~= 0) = "";
xticklabels({'0', '10', '20', '30', '40', '50', '60', '70', '80', '90'});
% Plot their Fourier counterparts
fft_win1_jl = abs(fft(inflows_filtered_jl1));
figure(4)
loglog(freq_series(1:length(fft_jl)),fft_jl, 'Color','#104E8B', 'DisplayName','Original');
legend({'Original','4-year cycle'},'Location','southeast');
title("Low-pass filter (f_{cut}=", string(fcut1_jl));
xlabel("Frequency (Hz)");
ylabel("Amplitude");
hold on
loglog(freq_series(1:length(fft_win1_jl)),fft_win1_jl, 'Color','#D88037','DisplayName','4-year cycle');
hold off
Replacing inflows_filtered_jl1 and fft_win1_jl (the 4-year cycle) with that of the annual cycle will result in Figure 5 below.

As previously mentioned, the low-pass filter effectively attenuated all frequencies higher than their respective
Next, we construct a spectrogram for this inflow time series. Here, we will use the Blackman-Harris window, which is a window that has a relatively wide main lobe and small side lobes. This enables it to amplify frequencies that more significantly characterize inflow, while suppressing less-significant ones. This window can be generated using the MATLAB blackmanharris() function, as shown below:
%% Define window size
Noverlap1_jl = N1_jl/2; % 4-year cycle
Noverlap2_jl = N2_jl/2; % Annual cycle
% Generate window
win1_jl = blackmanharris(N1_jl, 'periodic'); % 4-year cycle
win2_jl = blackmanharris(N2_jl, 'periodic'); % Annual cycle
Finally, we are ready to apply the spectrogram() function to generate the spectrogram for this inflow time series! In the code below, we set up the necessary values and generate the figure:
%% Define overlap size
Noverlap1_jl = N1_jl/2; % 4-year cycle
Noverlap2_jl = N2_jl/2; % Annual cycle
%% Plot inflow spectrogram for annual sampling (Jordan Lake)
spectrogram(inflows_jl, win1_jl, Noverlap1_jl, N1_jl, fs_inflow, 'yaxis');
colormap(flipud(parula));
clim([100,150]);
title('Jordan Lake 4-year cycle (Blackman-Harris)');
By replacing the values associated with the 4-year cycle with that of the annual cycle in the above code, the following figures can be generated:

In Figure 6, the darker blue indicates more powerful fluctuations (high-inflow events). However, their low frequency implies that, in this time series, such event are fairly rare. On the other hand, a lighter blue to yellow indicates inflow events of higher frequencies, but are less powerful. While they occur more frequently, they do not influence the signals in the time series significantly. We can also see from these two figures, that, in the long- and mid-term, both low and high frequency events become less powerful, implying a decrease in inflow, even more rare rainfall events that historically result in large inflows.
Conclusion
In this post, I first introduced a few basic concepts and methods related to time series analysis and the Fourier Domain. Next, we applied these concepts to the simple analysis of an inflow time series using MATLAB. Nevertheless, this post and its contents barely scratch the surface of Fourier Transforms and time series analysis as a whole. I hope this gave you a flavor of what these tools enable you to do, and hope that it piqued your interest into exploring this topic further!
 .
. donor locations, nearest to the target point.
donor locations, nearest to the target point.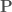 ) from the donor site(s) to the target.
) from the donor site(s) to the target.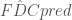 , and set of observed streamflow timeseries
, and set of observed streamflow timeseries  at
at ![Q_{obs} = [\mathbf{q_1}, \mathbf{q_2}, ..., \mathbf{q_k}]](https://s0.wp.com/latex.php?latex=Q_%7Bobs%7D+%3D+%5B%5Cmathbf%7Bq_1%7D%2C+%5Cmathbf%7Bq_2%7D%2C+...%2C+%5Cmathbf%7Bq_k%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002)
![FDC = [FDC_1, FDC_2, ..., FDC_k]](https://s0.wp.com/latex.php?latex=FDC+%3D+%5BFDC_1%2C+FDC_2%2C+...%2C+FDC_k%5D&bg=ffffff&fg=444444&s=0&c=20201002)
 , to non-exceedance probability timeseries,
, to non-exceedance probability timeseries, 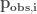 .
.

 where
where  is the distance from the observation
is the distance from the observation  to the ungauged location, and
to the ungauged location, and 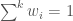 .
.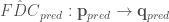

 gages using the
gages using the 
 .
.


