

About a year ago, the Reed Group began to develop a group Lab Manual. The motivation of the Lab Manual is to facilitate efficient training of new students, postdocs, and collaborators on everything from basic programming and high performance computing to synthetic streamflow generation and multi-objective reservoir operations. The Lab Manual is also meant to facilitate the sharing of open science tools more broadly with other researchers and practitioners. The Lab Manual is designed to be synergistic and interactive with the Water Programming Blog, which has been advancing similar goals for 12 years and counting.
In this blog post, I will give an introductory tour of the structure and content of the Reed Group Lab Manual. This project is fully open source – you can find the lab manual hosted on GitHub Pages here, as well as the underlying code repository on GitHub here. Previous blog posts have described the technical details behind creating the lab manual with Jupyter Books and automating build and deployment with GitHub Actions, as well as detailed code snippets for two different sections of the Figure Library (post 1, post 2). The present post, on the other hand, will provide a higher level tour of the Lab Manual contents without going into code-level detail.
The Lab Manual currently contains 8 sections as laid out in the left side navigation bar: (1) Graduate Student Resources, (2) Computational Resources, (3) Software, (4) Training, (5) Water Programming Blog Post Catalog, (6) List of Paper Repositories, (7) Figure Library, and (8) Contributing to this Manual. In the remainder of this post I will give a brief overview of each section.

Graduate Student Resources
The first section is meant to provide helpful resources for new students and scholars joining the Reed Group. This includes subsections on finding housing in Ithaca and a checklist for visiting scholars. It also includes links on important courses at Cornell and conferences to consider attending. Lastly, it includes tips, resources, and templates for designing presentations, writing papers, and staying organized.
Note that a few of the resources in this section (e.g., course list, presentations) link to private resources that are only available to Reed Group members and collaborators. The rest of the site is generally designed to be fully open access.

Computational Resources
The next section is designed to bring new researchers up to speed on topics in programming, computing, and other related topics. There are pages introducing researchers to basic Python, Linux, and Git/GitHub. There are also pages on more advanced topics of machine learning, citation/reference management, high performance computing, and Python-based website deployment (such as this Lab Manual website). These pages provide some original content but also rely heavily on links to previous Water Programming Blog posts and other online resources. This section also provides access information for The Cube and Hopper, two private clusters at Cornell University that Reed Group members have access to.

Software
Next, the Software section provides information on various software tools that past and present Reed Group members have contributed to. This includes software for multi-objective evolutionary computation and exploratory modeling (Borg MOEA, Rhodium, MOEA Framework), water resources management modeling (WaterPaths, Pywr-DRB, CALFEWS), sensitivity analysis (SALib), and high-dimensional visualization (J3). Each page contains links to the software itself, along with tutorials, Water Programming Blog posts, academic papers, and other code repositories that rely on the software.

Training
The Training section satisfies a core purpose of the Lab Manual: training new students, postdocs, and collaborators on core competencies needed by Reed Group members. Topics include key methodologies that underly much of our research (e.g., MOEAs, MORDM, sensitivity analysis, scenario discovery, synthetic generation) as well as important test problems (e.g., the shallow lake problem, the fisheries game) and software (e.g., Borg MOEA, WaterPaths).
These pages build on many years of formal and informal training exercises developed by past and present Reed Group members. Each page uses a common template structure that introduces the motivation and learning objectives, the necessary software installations, the prerequisite training prior to starting the current training, and the detailed sequence of training activities ranging from literature review to model execution and analysis.

Water Programming Blog Post Catalog
To complement the training exercises in the previous section, we have also embedded a searchable table of Water Programming Blog posts within the lab manual. This allows trainees to quickly find additional helpful material that may not be directly linked to their training exercises. Note that the main page of the Blog also has its own search functionality. The search tools in the lab manual vs the blog can return different results for the same search term, so it can be helpful to try both if you are looking for posts on a particular topic.

List of Paper Repositories
The Lab Manual also contains a list of important Reed Group papers and their relevant software repositories. This can be helpful for students or other researchers who are looking to replicate or build on the workflows in those papers.

Figure Library
Next, we have a Figure Library. The purpose of this section is to facilitate collaborative development and sharing of common types of figures that Reed Group members tend to use often. As discussed in my recent blog post, there are many tools available for creating figures such as parallel coordinates plots, but they often lack the level of flexibility and detail required to create high-quality figures for presentations and papers. Thus many Reed Group members and other researchers have built their own custom visualization tools from scratch. The purpose of the Figure Library is to create a bank of such tools so that we can build off of each other’s work rather than reinventing the wheel.
Because the Lab Manual is built with Jupyter Books, each page can be built using either Markdown or Python-based Jupyter Notebooks. The latter is an excellent option for the Figure Library as it allows for seamless integration of text, code blocks, and code output such as figures.

Contributing to this Lab Manual
The last section gives detailed instructions for those who want to contribute to the Lab Manual itself. This process is fairly straightforward for those who are comfortable with basic Git-based version control. Much of the complexity of building and deploying the site is done behind the scenes using GitHub Actions and GitHub Pages each time a new commit is pushed to the Main branch of the repository. This section also provides general examples for how to build pages in Markdown and Jupyter Notebooks, as well as a template that is used to ensure consistency across Training pages. Lastly, there is an FAQ page where contributors can describe helpful fixes to problems that they have experienced when working on the Lab Manual.

Conclusion
Overall, we hope that this Lab Manual will be a valuable resource for current and future Reed Group members and collaborators. This should improve the efficiency of training new researchers while easing the burden on both trainers and trainees. In addition, we hope that it is helpful for other researchers who want to learn about our suite of methodologies and software, as well as to other research groups looking to develop their own open source lab manuals.
It is worth noting that the Reed Group Lab Manual is meant to be a living document that will continue to evolve as current and future group members contribute new content or update old content to reflect the changing state-of-the-art. What I have described in this blog post simply reflects the current iteration of this Lab Manual roughly one year from when we began this project.
















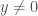 , and
, and  ).
). 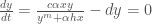
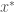 ) which satisfies this equation. Re-arrangement of the above equation yields:
) which satisfies this equation. Re-arrangement of the above equation yields: 

 yields the predator zero-isocline:
yields the predator zero-isocline: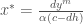
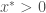 . From the zero-isocline stability equation above, it is clear that this is only true if:
. From the zero-isocline stability equation above, it is clear that this is only true if: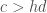
 ) must be greater than the death rate (
) must be greater than the death rate (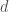 ) scaled by the time it needs to consume prey (
) scaled by the time it needs to consume prey (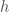 ).
). 

 , predator interference,
, predator interference,  , and the carrying capacity,
, and the carrying capacity,  ), unique species characteristics (e.g., the prey growth rate,
), unique species characteristics (e.g., the prey growth rate,  , and predation efficiency parameters
, and predation efficiency parameters 























{kind=link}