Intro to Python and Cython
Python has become one of the most loved and in demand programming languages in fields from data science and artificial intelligence to web and app development. Compared to lower-level programming languages like C/C++, Python puts an emphasis on readability and simplicity (you will often read that “Pythonic” code should be “beautiful”). This helps to accelerate the pace of program development and improve the sharing of ideas. According to Python developer Guido van Rossum,
Typically when you ask a programmer to explain to a lay person what a programming language is, they will say that it is how you tell a computer what to do… In reality, programming languages are how programmers express and communicate ideas — and the audience for those ideas is other programmers, not computers. The reason: the computer can take care of itself, but programmers are always working with other programmers, and poorly communicated ideas can cause expensive flops.
What we commonly call Python is really two different things: the language and the implementation. The Python language defines the syntax with which we write code. The most common implementation is CPython (written in C and Python), which compiles valid Python code into bytecode and then interprets it in real time as the program runs.
One of the reason’s for Python’s popularity is the flexibility afforded by its dynamic typing and memory management. I can define a variable x = 5, divide x by 2 to get 2.5, and then later set x = 'Florida'. In this sequence, x will have been typed as an integer, a float, and then a string. Python can do this for us automatically with no problem; under the hood it is dynamically allocating/deallocating memory, checking for type compatibility with mathematical operations, etc.
However, this flexibility has a cost, as it requires the interpreter to run a large number of tasks and checks behind the scenes at run time. Lower-level compiled languages like C require the user to pre-specify the type for each variable, how to allocate and deallocate memory, etc. This structure makes them less flexible and more difficult to use, but potentially much faster. In many applications Python is significantly slower (e.g., 10-100x) than typed, compiled languages such as C/C++.
Cython is an attempt to bridge the gap by bringing some of C’s qualities to Python. It is technically a separate programming language which is a superset of the Python language; Cython code mostly looks like Python code, but it also adds optional C-inspired syntax. Most notably, it allows us to declare static types when defining variables/classes/functions.
Cython can automatically translate our code into C, which can then be then compiled into CPython extension modules. These compiled modules can be imported and used within Python code with significantly lower overhead than the equivalent Python modules.
Software
You can find all code used in this blog post at this GitHub repository.
If you want to follow along and build Cython code on your own machine, you will need a working Python 3 environment (preferably 3.6+ to avoid dependency issues) with NumPy, Cython, Matplotlib, and Jupyter.
You will also need the right compiler. OSX and Linux (including WSL) users should already have gcc standard. Windows users who don’t use WSL will need to download Microsoft Visual Studio 2019 to make sure you have the right compiler. Choose “Desktop development with C++” when it asks which programs you want to install.
A simple example: the Fibonacci sequence
The Fibonacci sequence is defined through the following recurrence relation:
Fn = Fn-1 + Fn-2
The sequence begins 0, 1, 1, 2, 3, 5, 8, …
In this blogpost we will build several versions of a function to calculate the n’th Fibonacci number. All scripts associated with this example can be found in the “fibonacci/” directory of the repository above. The examples in this section are adapted from Kurt W. Smith’s O’Reilly Media book, “Cython: A Guide for Python Programmers“.
First, consider the pure Python implementation of this function, saved as fib_py.py:
def fib_py(n):
a, b = 0, 1
for i in range(n - 1):
a, b = a + b, a
return a
We can import and run this function, and print the 30th Fibonacci number as follows:
from fib_py import fib_py
print(fib_py(30))
The output is 514229, which is indeed the 30th number in the sequence.
The second file in the repository, fib_py_cy.py, is identical to the first script. We will “Cythonize” it to compiled C code without making any manual changes.
The third version, fib_cy.pyx, is a Cythonic implementation. Note the new file ending, .pyx, for Cython source files. Each variable is now statically typed as an integer. In the function body, this is done by prefacing the variable definition by cdef. The cdef is not necessary for arguments in the function definition (e.g., n).
def fib_cy(int n):
cdef int a = 0
cdef int b = 1
cdef int i
for i in range(n - 1):
a, b = a + b, a
return a
Because of the importance of types for Cython, I have also included three more files which are equivalent to the first three, except that they use floating point numbers to count rather than integers. Note that, confusingly, the Python float class is equivalent to C doubles, not C floats.
Here is fib_py_double.py and fib_py_cy_double.py. These don’t explicitly define a static type, but a and b are defined using a decimal so that they will be stored as floating points rather than integers (e.g., 0. rather than 0).
def fib_py_double(n):
a, b = 0., 1.
for i in range(n - 1):
a, b = a + b, a
return a
And here is fib_cy_double.pyx with statically defined types:
def fib_cy_double(int n):
cdef double a = 0.
cdef double b = 1.
cdef int i
for i in range(n - 1):
a, b = a + b, a
return a
In order to run the Cython code, we first have to Cythonize it. This involves two steps: translating our Python-like code into C code, and compiling the C code into an executable. If you want to repeat this process on your own machine, first delete all *.so, *.pyd, *.c, and *.html files, as well as the build/ directory.
To Cythonize, we use a setup file, setup_fibs.py:
from setuptools import setup
from Cython.Build import cythonize
setup(ext_modules = cythonize(['fib_py_cy.py', 'fib_cy.pyx', 'fib_py_cy_double.py', 'fib_cy_double.pyx'], annotate=True, language_level=3))
and run it in Python:
python3 setup_fibs.py build_ext --inplace
We get the following output:
Compiling fib_py_cy.py because it changed.
Compiling fib_cy.pyx because it changed.
Compiling fib_py_cy_double.py because it changed.
Compiling fib_cy_double.pyx because it changed.
[1/4] Cythonizing fib_cy.pyx
[2/4] Cythonizing fib_cy_double.pyx
[3/4] Cythonizing fib_py_cy.py
[4/4] Cythonizing fib_py_cy_double.py
running build_ext
building 'fib_py_cy' extension
creating build
creating build/temp.linux-x86_64-3.8
x86_64-linux-gnu-gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werror=format-security -g -fwrapv -O2 -g -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2 -fPIC -I/usr/include/python3.8 -c fib_py_cy.c -o build/temp.linux-x86_64-3.8/fib_py_cy.o
creating build/lib.linux-x86_64-3.8
x86_64-linux-gnu-gcc -pthread -shared -Wl,-O1 -Wl,-Bsymbolic-functions -Wl,-Bsymbolic-functions -Wl,-z,relro -g -fwrapv -O2 -Wl,-Bsymbolic-functions -Wl,-z,relro -g -fwrapv -O2 -g -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2 build/temp.linux-x86_64-3.8/fib_py_cy.o -o build/lib.linux-x86_64-3.8/fib_py_cy.cpython-38-x86_64-linux-gnu.so
...
copying build/lib.linux-x86_64-3.8/fib_py_cy.cpython-38-x86_64-linux-gnu.so ->
copying build/lib.linux-x86_64-3.8/fib_cy.cpython-38-x86_64-linux-gnu.so ->
copying build/lib.linux-x86_64-3.8/fib_py_cy_double.cpython-38-x86_64-linux-gnu.so ->
copying build/lib.linux-x86_64-3.8/fib_cy_double.cpython-38-x86_64-linux-gnu.so ->
This output has several steps. First, Python checks which of our files has changed since the last Cythonization (in this case, all of them, since we deleted all previous Cython files). Each of these is Cythonized, creating a *.c file. Then each *.c file is compiled using gcc to create a *.so dynamic library, which is able to communicate directly with CPython at runtime (this may be a *.pyd file if you are using Windows without WSL). Finally, the files are copied from the build/ directory to the working directory, where they can be imported by Python scripts.
If you look at the C files, you will notice they are much longer and more complicated than the original Python file, or for that matter, than a true C implementation would be. For example, my version of fib_cy.c is 3179 lines long. The vast majority of this is specialized functions for interfacing between C and Python and handling various errors and exceptions. Thankfully, when programming in Cython we generally don’t have any need to edit or interpret the C files themselves.
Also created is a *.html annotation file that can be opened in the browser. These files highlight regions of the original Cython file based on how much Python interaction they require at runtime. For example, compare the highlighting for fib_py_cy.py and fib_cy.pyx:


The former, which does not include static type information, has significant interaction with the Python interpreter due to the need for dynamic type checking and memory management throughout the loop. The latter, on the other hand, only interacts with Python when calling and returning from the function; the internal computation of the loop is self-contained C code. If you click on particular highlighted lines, you can expand to see the specific C code associated with those lines.
So how do the performance of these different versions compare? The time_versions.py script will run 10×100,000 repetitions of each version of our code, given a Fibonacci sequence number (e.g., 30) that is supplied as a command line argument:
$ python3 time_versions.py 30
Pure python: answer = 514229, time = 0.07640906400047243, speedup = 1.0
Cythonized Python: answer = 514229, time = 0.03642013104399666, speedup = 2.0979898152526655
Typed Cython: answer = 514229, time = 0.0032417900511063635, speedup = 23.570022362921193
Pure Python (double): answer = 514229.0, time = 0.06389092199970037, speedup = 1.1959299006646167
Cythonized Python (double): answer = 514229.0, time = 0.016547597013413906, speedup = 4.617532318350108
Typed Cython (double): answer = 514229.0, time = 0.002909799979534, speedup = 26.259215251183424
For each of our six version, the answer calculated is the same, as expected. The “speedup” is calculated as the runtime for the pure Python integer implementation, divided by the runtime for the implementation of interest. The speedup is found to be 2.1 for fib_py_cy.py, the version that was Cythonized without explicitly adding type information. Pretty good for basically no work! However, the speedup for the statically typed version is much larger, at 23.6. This highlights how important dynamic type checking and memory management are as a bottleneck for Python. The double versions are found to be somewhat faster than the integer versions as well.
However, redoing the analysis for n=50 highlights an important lesson:
$ python3 time_versions.py 50
Pure python: answer = 7778742049, time = 0.1132775130099617, speedup = 1.0
Cythonized Python: answer = 7778742049, time = 0.06092342402553186, speedup = 1.8593425241905186
Typed Cython: answer = -811192543, time = 0.003898979048244655, speedup = 29.053121755286153
Pure Python (double): answer = 7778742049.0, time = 0.09670376998838037, speedup = 1.1713867310816608
Cythonized Python (double): answer = 7778742049.0, time = 0.02165580401197076, speedup = 5.2308153946787135
Typed Cython (double): answer = 7778742049.0, time = 0.0044801399926654994, speedup = 25.284369058870908
Notice how the answer produced by the typed Cython integer version is -811192543, rather than the correct answer of 7778742049. The reason for this is that Python3 integers can be unlimited size, while C integers can overflow if they get too big. This fact would typically be accounted for by the Python interpreter when interfacing with C code, by converting to a long integer rather than a standard integer when necessary (notice how the Cythonized Python version got the correct answer). However, in our static Cython code, these types of error checks are not performed. This shows that the speed advantages of Cython are not free – you do lose some of the flexibility & safety of Python, so some care is required. In practice, you may need to introduce manual checks into your function (much like in C) where overflow or other memory errors are possible.
Next steps
I hope this introduction to Cython has been helpful. In my next blog post, I will demonstrate how to use Cython for more complex tasks involving functions, classes, and Numpy arrays, using a reservoir simulation example.
Further reading
For more information, of course see the Cython docs. I also highly recommend Kurt W. Smith’s O’Reilly Media book, “Cython: A Guide for Python Programmers” for those wanting a deeper understanding. It also looks like the author also has a tutorial, but I haven’t tried it yet. Lastly, for information on how to improve the efficiency of your Python code more generally (prior to or in lieu of using Cython), I recommend Micha Gorelick and Ian Ozsvald’s O’Reilly Media book, “High Performance Python: Practical Performant Programming for Humans.”






 is the pollution concentration in the lake,
is the pollution concentration in the lake,  is the anthropogenically pollution discharged from the town,
is the anthropogenically pollution discharged from the town, 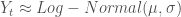 is the natural pollution inflow into the lake and follows a log-normal distribution,
is the natural pollution inflow into the lake and follows a log-normal distribution,  is the rate at which pollution is recycled from the sediment into the water column, and
is the rate at which pollution is recycled from the sediment into the water column, and  is the rate at which the nutrient pollution is removed from the lake due to natural processes.
is the rate at which the nutrient pollution is removed from the lake due to natural processes.  is generated and the policy is evaluated under these conditions. This is repeated 100 times for 100 unique realizations of natural inflow.
is generated and the policy is evaluated under these conditions. This is repeated 100 times for 100 unique realizations of natural inflow.  ) for an increasingly large number of realizations:
) for an increasingly large number of realizations:


 .
.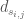 , the historic weekly demand mean,
, the historic weekly demand mean,  , and standard deviation,
, and standard deviation,  , are applied to convert to a synthetic unit demand,
, are applied to convert to a synthetic unit demand,  .
.
![E[D|Q_{s_i}]](https://s0.wp.com/latex.php?latex=E%5BD%7CQ_%7Bs_i%7D%5D&bg=ffffff&fg=444444&s=0&c=20201002) , given a specific synthetic streamflow,
, given a specific synthetic streamflow,  , is:
, is:![E[D|Q_{s_i}] = E[D] + \rho \frac{\sigma_Q}{\sigma_D} (Q_i - \mu_Q)](https://s0.wp.com/latex.php?latex=E%5BD%7CQ_%7Bs_i%7D%5D+%3D+E%5BD%5D+%2B+%5Crho+%5Cfrac%7B%5Csigma_Q%7D%7B%5Csigma_D%7D+%28Q_i+-+%5Cmu_Q%29+&bg=ffffff&fg=444444&s=0&c=20201002)
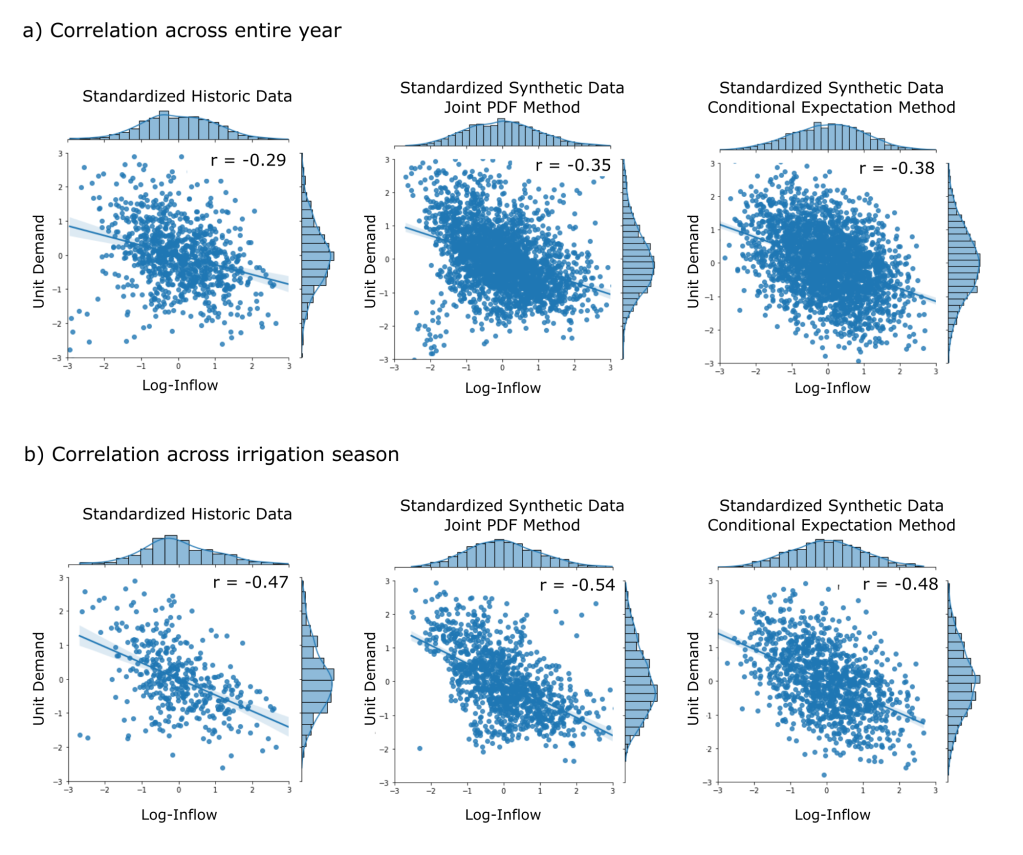
 is the Pearson correlation coefficient of the weekly standardized historic inflow and demand data. Since the data is standardized, (
is the Pearson correlation coefficient of the weekly standardized historic inflow and demand data. Since the data is standardized, ( ![E[d] = 0](https://s0.wp.com/latex.php?latex=E%5Bd%5D+%3D+0&bg=ffffff&fg=444444&s=0&c=20201002) and
and 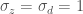 ) the above form of the equation simplifies to:
) the above form of the equation simplifies to:![E[d|Z_{s_i}] = \rho (Z_{s_i})](https://s0.wp.com/latex.php?latex=E%5Bd%7CZ_%7Bs_i%7D%5D+%3D+%5Crho+%28Z_%7Bs_i%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)
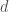 is standard synthetic demand and
is standard synthetic demand and 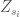 is the standard synthetic streamflow for the
is the standard synthetic streamflow for the 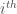 week. The variance of the standard demand conditional upon the standard streamflow is then:
week. The variance of the standard demand conditional upon the standard streamflow is then:
 , is then randomly sampled from a normal distribution centered around the conditional expectation with standard deviation equal to the square root of the conditional variance.
, is then randomly sampled from a normal distribution centered around the conditional expectation with standard deviation equal to the square root of the conditional variance.![d_{s_i} \approx N(E[d|Z_{s_i}], Var(d|Z_{s_i})^{1/2})](https://s0.wp.com/latex.php?latex=d_%7Bs_i%7D+%5Capprox+N%28E%5Bd%7CZ_%7Bs_i%7D%5D%2C+Var%28d%7CZ_%7Bs_i%7D%29%5E%7B1%2F2%7D%29&bg=ffffff&fg=444444&s=0&c=20201002)