
The purpose of this blog post is to introduce dynamic emulation in the context of applications to hydrology. Hydrologic modelling involves implementing mathematical equations to represent physical processes such as precipitation, runoff, and evapotranspiration and to characterize energy and water flux within the hydrologic system (Abbott et al., 1986). Users of a model might be interested in using it to approach a variety of problems related to, for instance, modeling the rainfall-runoff process in a river basin. The user might try to validate the model, perform sensitivity or uncertainty analysis, determine optimal planning and management of the basin, or test how hydrology of the basin is affected by different climate scenarios. Each of these problems requires a numerically intensive Monte Carlo style approach for which a physical model is not conducive. A solution to this problem is to create an emulator for the physical model. An emulator is a computationally efficient model whose response characteristics mimic those of a complex model as closely as possible. This model can then replace the more complicated model in computationally intensive exercises (Tych & Young, 2012).
There are many different approaches to creating an emulator; one particularly unified approach is Dynamic Emulation Modelling (DEMo) (Castelletti et al., 2012). DEMo seeks to accomplish three goals when creating an emulator:
- The emulator is less computationally intensive than the physical model.
- The emulator’s input-output behavior approximates as well as possible the behavior of the physical model.
- The emulator is credible to users.
DEMo has five main steps:
-
- Design of Computer Experiments: Determine a set of input data to build the emulator off of that will cover the range of responses of the physical model
- Variable Aggregation: Reduce dimensionality of the input data
- Variable Selection: Select components of the reduced inputs that are most relevant to explaining the output data
- Structure Identification and Parameter Estimation: In the case of a rainfall runoff model, choose a set of appropriate black box models that can capture the complex, non-linear process and fit the parameters of these models accordingly.
- Evaluation and Physical Interpretation: Evaluate the model on a validation set and determine how well the model’s behavior and structure can be explained or attributed to physical processes.
The next section outlines two data-driven style models that can be used for hydrologic emulation.
Artificial Neural Networks (ANNs)
Rainfall-runoff modelling is one of the most complex and non-linear hydrologic phenomena to comprehend and model. This is due to tremendous spatial and temporal variability in watershed characteristics. Because ANNs can mimic high-dimensional non-linear systems, they are a popular choice for rainfall-runoff modeling (Maier at al., 2010). Depending on the time step of interest as well as the complexity of the hydrology of the basin, a simple feedforward network may be sufficient for accurate predictions. However, the model may benefit from having the ability to incorporate memory that might be inherent in the physical processes that dictate the rainfall-runoff relationship. Unlike feedforward networks, recurrent neural networks are designed to understand temporal dynamics by processing inputs in sequential order (Rumelhart et al., 1986) and by storing information obtained from previous outputs. However, RNNs have trouble learning long-term dependencies greater than 10 time steps (Bengio, 1994). The current state of the art is Long Short-Term Memory (LSTM) models. These RNN style networks contain a cell state that has the ability of learn long-term dependencies as well as gates to regulate the flow of information in and out the cell, as shown in Figure 1.

Figure 1: Long Short-Term Memory Module Architecture1
LSTMs are most commonly used in speech and writing recognition but have just begun to be implemented in hydrology applications with success especially in modelling rainfall-runoff in snow-influenced catchments. Kratzert et al., 2018, show that the LSTM is able to outperform the Sacramento Soil Moisture Accounting Model (SAC-SMA) coupled with a Snow-17 routine to compute runoff in 241 catchments.
Support Vector Regression (SVR)
Support vector machines are commonly used for classification but have been successfully implemented for working with continuous values prediction in a regression setting. Support vector regression relies on finding a function within a user specified level of precision, ε, from the true value of every data point, shown in Figure 2.

Figure 2: Support Vector Regression Model2
It is possible that this function may not exist, and so slack variables, ξ , are introduced which allow errors up to ξ to still exist. Errors that lie within the epsilon bounds are treated as 0, while points that lie outside of the bounds will have a loss equal to the distance between the point and the ε bound. Training an SVR model requires solving the following optimization problem:

Where w is the learned weight vector and xi and yi are training points. C is a penalty parameter imposed on observations that lie outside the epsilon margin and also serves as a method for regularization. In the case that linear regression is not sufficient for the problem, the inner products in the dual form of the problem above can be substituted with a kernel function that maps x to a higher dimensional space, This allows for estimation of non-linear functions. Work by Granata et al., 2016 compares an SVR approach with EPA’s Storm Water Management Model (SWMM) and finds comparable results in terms of RMSE and R2 value.
References
Abbott, M.b., et al. “An Introduction to the European Hydrological System — Systeme Hydrologique Europeen, ‘SHE’, 1: History and Philosophy of a Physically-Based, Distributed Modelling System.” Journal of Hydrology, vol. 87, no. 1-2, 1986, pp. 45–59., doi:10.1016/0022-1694(86)90114-9.
Bengio, Y., et al. “Learning Long-Term Dependencies with Gradient Descent Is Difficult.” IEEE Transactions on Neural Networks, vol. 5, no. 2, 1994, pp. 157–166., doi:10.1109/72.279181.
Castelletti, A., et al. “A General Framework for Dynamic Emulation Modelling in Environmental Problems.” Environmental Modelling & Software, vol. 34, 2012, pp. 5–18., doi:10.1016/j.envsoft.2012.01.002.
Castelletti, A., et al. “A General Framework for Dynamic Emulation Modelling in Environmental Problems.” Environmental Modelling & Software, vol. 34, 2012, pp. 5–18., doi:10.1016/j.envsoft.2012.01.002.
Granata, Francesco, et al. “Support Vector Regression for Rainfall-Runoff Modeling in Urban Drainage: A Comparison with the EPA’s Storm Water Management Model.” Water, vol. 8, no. 3, 2016, p. 69., doi:10.3390/w8030069.
Kratzert, Frederik, et al. “Rainfall–Runoff Modelling Using Long Short-Term Memory (LSTM) Networks.” Hydrology and Earth System Sciences, vol. 22, no. 11, 2018, pp. 6005–6022., doi:10.5194/hess-22-6005-2018.
Maier, Holger R., et al. “Methods Used for the Development of Neural Networks for the Prediction of Water Resource Variables in River Systems: Current Status and Future Directions.” Environmental Modelling & Software, vol. 25, no. 8, 2010, pp. 891–909., doi:10.1016/j.envsoft.2010.02.003.
Rumelhart, David E., et al. “Learning Representations by Back-Propagating Errors.” Nature, vol. 323, no. 6088, 1986, pp. 533–536., doi:10.1038/323533a0.
Tych, W., and P.c. Young. “A Matlab Software Framework for Dynamic Model Emulation.” Environmental Modelling & Software, vol. 34, 2012, pp. 19–29., doi:10.1016/j.envsoft.2011.08.008.
Figures:
(1) https://colah.github.io/posts/2015-08-Understanding-LSTMs/
(2) Kleynhans, Tania, et al. “Predicting Top-of-Atmosphere Thermal Radiance Using MERRA-2 Atmospheric Data with Deep Learning.” Remote Sensing, vol. 9, no. 11, 2017, p. 1133., doi:10.3390/rs9111133.


 that maximize our economic benefits, but also increase P in the lake. If we increase P too much, and we cross a tipping point of no return. Even though this is vital to the design of the best possible management policy, this value of P is hard to know exactly because:
that maximize our economic benefits, but also increase P in the lake. If we increase P too much, and we cross a tipping point of no return. Even though this is vital to the design of the best possible management policy, this value of P is hard to know exactly because: 
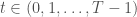 . This strategy necessitates 100 decision variables.
. This strategy necessitates 100 decision variables.  , to a decision
, to a decision  . This strategy necessitates 6 decision variables.
. This strategy necessitates 6 decision variables. 






