
Principle Component Analysis (PCA) is a powerful tool that can be used to create parsimonious representations of a multivariate data set. In this post I’ll code up an example from Dan Wilks’ book Statistical Methods in the Atmospheric Sciences to visually illustrate the PCA process. All code can be found at the bottom of this post.
As with many of the examples in Dr. Wilks’ excellent textbook, we’ll be looking at minimum temperature data from Ithaca and Canandaigua, New York (if anyone is interested, here is the distance between the two towns). Figure 1 is a scatter plot of the minimum temperature anomalies at each location for the month of January 1987.

Figure 1: Minimum temperature anomalies in Ithaca and Canandaigua, New York in January 1987
As you can observe from Figure 1, the two data sets are highly correlated, in fact, they have a Pearson correlation coefficient of 0.924. Through PCA, we can identify the primary mode of variability within this data set (its largest “principle component”) and use it to create a single variable which describes the majority of variation in both locations. Let x define the matrix of our minimum temperature anomalies in both locations. The eigenvectors (E) of the covariance matrix of x describe the primary modes variability within the data set. PCA uses these eigenvectors to create a new matrix, u, whose columns contain the principle components of the variability in x.

Each element in u is a linear combination of the original data, with eigenvectors in E serving as a kind of weighting for each data point. The first column of u corresponds to the eigenvector associated with the largest eigenvalue of the covariance matrix. Each successive column of u represents a different level of variability within the data set, with u1 describing the direction of highest variability, u2 describing the direction of the second highest variability and so on and so forth. The transformation resulting from PCA can be visualized as a rotation of the coordinate system (or change of basis) for the data set, this rotation is shown in Figure 2.

Figure 2: Geometric interpretation of PCA
As can be observed in Figure 2, each data point can now be described by its location along the newly rotated axes which correspond to its corresponding value in the newly created matrix u. The point (16, 17.8), highlighted in Figure 2, can now be described as (23, 6.6) meaning that it is 23 units away from the origin in the direction of highest variability and 6.6 in the direction of second highest variability. As shown in Figure 2, the question of “how different from the mean” each data point is can mostly be answered by looking at its corresponding u1 value.
Once transformed, the original data can be recovered through a process known as synthesis. Synthesis can be thought of as PCA in reverse. The elements in the original data set x, can be approximated using the eigenvalues of the covariance matrix and the first principle component, u1.

Where:
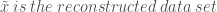
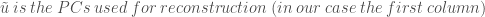

For our data set, these reconstructions seem to work quite well, as can be observed in Figure 3.

Data compression through PCA can be a useful alternative tolerant methods for dealing with multicollinearity, which I discussed in my previous post. Rather than running a constrained regression, one can simply compress the data set to eliminate sources of multicollinearity. PCA can also be a helpful tool for identifying patterns within your data set or simply creating more parsimonious representations of a complex set of data. Matlab code used to create the above plots can be found below.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Ithaca_Canandagua_PCA
% By: D. Gold
% Created: 3/20/17
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% This script will perform Principle Component analysis on minimum
% temperature data from Ithaca and Canadaigua in January, 1987 provided in
% Appendix A of Wilks (2011). It will then estimate minimum temperature
% values of both locations using the first principle component.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%% create data sets
clear all
% data from appendix Wilks (2011) Appendix A.1
Ith = [19, 25, 22, -1, 4, 14, 21, 22, 23, 27, 29, 25, 29, 15, 29, 24, 0,...
2, 26, 17, 19, 9, 20, -6, -13, -13, -11, -4, -4, 11, 23]';
Can = [28, 28, 26, 19, 16, 24, 26, 24, 24, 29, 29, 27, 31, 26, 38, 23,...
13, 14, 28, 19, 19, 17, 22, 2, 4, 5, 7, 8, 14, 14, 23]';
%% center the data, plot temperature anomalies, calculate covariance and eigs
% center the data
x(:,1) = Ith - mean(Ith);
x(:,2) = Can - mean(Can);
% plot anomalies
figure
scatter(x(:,1),x(:,2),'Filled')
xlabel('Ithaca min temp anomaly ({\circ}F)')
ylabel('Canandagua min temp anomaly ({\circ}F)')
% calculate covariance matrix and it's corresponding Eigenvalues & vectors
S = cov(x(:,1),x(:,2));
[E, Lambda]=eigs(S);
% Identify maximum eigenvalue, it's column will be the first eigenvector
max_lambda = find(max(Lambda)); % index of maximum eigenvalue in Lambda
idx = max_lambda(2); % column of max eigenvalue
%% PCA
U = x*E(:,idx);
%% synthesis
x_syn = E(:,idx)*U'; % reconstructed values of x
% plot the reconstructed values against the original data
figure
subplot(2,1,1)
plot(1:31,x(:,1) ,1:31, x_syn(1,:),'--')
xlim([1 31])
xlabel('Time (days)')
ylabel('Ithaca min. temp. anomalies ({\circ}F)')
legend('Original', 'Reconstruction')
subplot(2,1,2)
plot(1:31, x(:,2),1:31, x_syn(2,:)','--')
xlim([1 31])
xlabel('Time (days)')
ylabel('Canadaigua min. temp. anomalies ({\circ}F)')
legend('Original', 'Reconstruction')
Sources:
Wilks, D. S. (2011). Statistical methods in the atmospheric sciences. Amsterdam: Elsevier Academic Press.


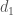 ,
,  , and
, and 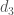 ). The utilities are connected via some infrastructure, as shown in Figure 1. When our total available water (
). The utilities are connected via some infrastructure, as shown in Figure 1. When our total available water ( ) is in excess of the demand (
) is in excess of the demand (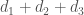 ), no rationing is needed. When we do need to ration, we want to allocate the water to minimize the percent supply deficits across the three utilities:
), no rationing is needed. When we do need to ration, we want to allocate the water to minimize the percent supply deficits across the three utilities:



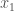 for instance, into many decision variables, representing different ranges of the actual allocation
for instance, into many decision variables, representing different ranges of the actual allocation  ,
, 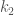 , and
, and  ), and the contribution to the objective function from that release can be approximated by:
), and the contribution to the objective function from that release can be approximated by:

 and
and  . Of course the constraints from the original optimization problem would need to be translated into terms of the new decision variables.
. Of course the constraints from the original optimization problem would need to be translated into terms of the new decision variables. .For this reason, the algorithm will increase
.For this reason, the algorithm will increase 