
Motivation
Onboarding new students, staff, or collaborators can be a challenge in highly technical fields. Often, the knowledge needed to run complex experiments or computing workflows is spread across multiple individuals or teams based on their unique experiences, and training of new team members tends to occur in an ad hoc and inefficient manner. These challenges are compounded by the inevitable turnover of students, postdocs, and external collaborators in academic research settings.
Over the years, the Reed Group has developed a large bank of training materials to help streamline the onboarding process for new team members. These materials introduce concepts and tools related to water systems modeling, multi-objective evolutionary algorithms, global sensitivity analysis, synthetic streamflow generation, etc. However, these materials are still spread across a variety of sources (academic papers, GitHub repositories, blog posts, etc.) and team members, and there has been growing recognition of the need to catalogue and compile relevant resources and trainings in a more structured way.
For this reason, we have begun to create a lab manual for the Reed group. This will include a wide variety of information relevant to new students and researchers – everything from training exercises and code snippets, to reading lists and coursework suggestions, to a code of conduct outlining our values and expectations. The goal is for this to be a collaborative, living document created and maintained by students and postdocs. Ideally this will continue to evolve for years along with the evolving state-of-the-art in methodology, software, and literature.
After considering a number of different platforms for constructing websites, we settled on the Jupyter Book package for Python. You can find our lab manual here, and the source code used to create it here – note that this is still very much in development, a skeleton waiting to be fleshed out. In the remainder of this blog post, I will highlight the major elements of a Jupyter Book website, using our skeleton lab manual as an example. Then in a future blog post, I will outline the Continuous Integration and Continuous Delivery (CI/CD) strategy we are using to manage versioning and platform dependency issues across multiple developers.
Intro to Jupyter Book
Jupyter Book is a Python package for creating static websites. The package is built on the popular Sphinx engine used to create documentation for many of your favorite Python packages. Sphinx was also used to create the ebook for “Addressing Uncertainty in MultiSector Dynamics Research“, as described in two recent blog posts by Rohini Gupta and Travis Thurber. The ebook was a source of inspiration for our lab manual and the reason we initially considered Sphinx-based workflows. However, Jupyter Books layers several additional functionalities on top of Sphinx. First, it supports use of the MyST Markdown language, which is more familiar and intuitive to most researchers than the reStructured Text format favored by Sphinx. And second, it allows for pages to be built from executable Jupyter Notebooks, a powerful tool for combining text and equations with formatted code blocks, program output, and generated figures.
The Jupyter Book documentation contains tutorials, examples, and references, and is an excellent resource for anyone looking to build their own site. The documentation itself is, of course, created using the Jupyter Book package, and interested readers can check out the source code here.
Designing the website structure
The hierarchical structure of a Jupyter Book is defined in a simple YAML-style Table of Contents file, which should be named _toc.yml. Here is the TOC for our lab manual at present:
format: jb-book
root: intro.md
parts:
- chapters:
- file: ExamplePages/ExamplePages.md
sections:
- file: ExamplePages/mdExample.md
- file: ExamplePages/nbExample.ipynb
- file: Resources/Resources.md
sections:
- file: Resources/ClusterBasics.md
- file: Resources/Computing.md
- file: Resources/Courses.md
- file: Resources/DataVisualization.md
- file: Resources/LifeAtCornell.md
- file: Resources/ReedGroupTools.md
- file: Resources/WritingProcess.md
- file: Resources/CitationNetworkandDiscovery.md
- file: Training/Training.md
sections:
- file: Training/Schedule.md
- file: Training/Reading.md
- file: Training/LakeProblem.md
- file: Training/Training_Fisheries_Part1.md
- file: Training/Linux_MOEAs_HPC.md
The “root” defines the landing page, in this case the intro.md markdown file. That landing page will link to three “chapters” called ExamplePages, Resources, and Training. Each of these chapters has it’s own landing page as well as multiple child “sections.” Each page can either be written as a Markdown file (.md) or a Jupyter Notebook (.ipynb).
The other important YAML file for all Jupyter Books is _config.yml:
title: Reed group lab manual
author: The Reed Group at Cornell CEE
logo: logo.png
# Force re-execution of notebooks on each build.
# See https://jupyterbook.org/content/execute.html
execute:
execute_notebooks: force
# Define the name of the latex output file for PDF builds
latex:
latex_documents:
targetname: book.tex
# Add a bibtex file so that we can create citations
bibtex_bibfiles:
- references.bib
# Information about where the book exists on the web
repository:
url: https://github.com/reedgroup/reedgroup.github.io # Online location of your book
path_to_book: docs # Optional path to your book, relative to the repository root
# Add GitHub buttons to your book
# See https://jupyterbook.org/customize/config.html#add-a-link-to-your-repository
html:
use_issues_button: true
use_repository_button: true
We first define our website’s title and author, as well as an image logo to display. The line “execute_notebooks: force” means that we want to reexecute all Jupyter Notebooks each time the site is built (see docs for other options). The url gives the web address where we want to host our site – in this case the GitHub Pages address associated with the GitHub repository for the site. The path_to_book defines “docs” as the folder in the repository where all source code is to be held. Finally, the last two options are used to create buttons at the top of our site that link to the GitHub repository in case readers want to browse the source code or report an issue. For now, we are using the default vanilla style, but there are many ways to customize the structural and aesthetic style of the site. You would need to point to custom style files from this configuration file – see the Jupyter Book gallery for inspiration.
Building pages with Markdown and Jupyter Notebooks
Jupyter Book makes it very easy to write new pages using either Markdown or Jupyter Notebooks. For context, here is a screenshot of the site’s homepage:

The main content section for this page is built from the “root” file, intro.md:
# Welcome to our lab manual!
```{warning}
This site is still under construction
```
The purpose of this site is to help new students and collaborators get up to speed on the research methods/tools used by the Reed Group. This page is designed and maintained by other graduate students and post docs, and is intended to serve as a living document.
This manual was created using the Jupyter Books Python package, and is hosted with GitHub Pages. You can find our source code at https://github.com/reedgroup/reedgroup.github.io.
```{tableofcontents}```
As you can see, this uses a very human-readable and intuitive Markdown-based file structure. Jupyter Book provides simple functionality for warning labels and other emphasis boxes, as well as a Table of Contents that is automatically rendered from the _toc.yml file. The tableofcontents command can be used from anywhere in the hierarchical page tree and will automatically filter to include only children of the current page. The separate sidebar TOC will also expand to show “sections” as you navigate into different “chapters.” For example, here is the Markdown and rendered webpage for the “ExamplePages” chapter:
# Example Pages with JupyterBooks
```{tableofcontents}```

For more detailed pages, you can also apply standard Markdown syntax to add section headers, bold/italic font, code blocks, lists, Latex equations, images, etc. For example, here is ExamplePages/mdExample.md:
# Markdown example
This is an example page using just markdown
### Subsection 1
Here is a subsection
### Subsection 2
Here is another subsection.
:::{note}
Here is a note!
:::
And here is a code block:
```
e = mc^2
```
And here comes a cute image!


Lastly, and most importantly for purposes of building a training manual, we can create pages using Jupyter Notebooks. For example, here are two screenshots of the webpage rendered from ExamplePages/nbExample.ipynb:


As you can see, the Notebook functionality allows us to combine text and equations with rendered Python code. We can also execute Bash, R, or other programs using Jupyter Notebook’s “magic” commands. Note that the Jupyter-based website is not interactive – for that you’ll need Binder, as demonstrated in this blog post by David Gold.
Nevertheless, the Notebook is reexecuted each time we rebuild the website, which should really streamline collaborative lab manual development. For example, once we have developed a code bank of visualization examples (stay tuned!), it will be straightforward to edit the existing examples and/or add new examples, with the rendered visualizations being automatically updated rather than needing to manually upload the new images. Additionally, reexecuting the Notebooks each time we rebuild the site will force us to maintain the functionality of our existing code bank rather than letting portions become obsolete due to package dependencies or other issues.
Next steps
You now have the basic building blocks to create your own lab manual or ebook using a collection of YAML files, Markdown files, and Jupyter Notebooks. The last two critical steps are to actually build the static site (e.g., the html files) using Jupyter Book, and then host the site using GitHub pages. I will demonstrate these steps, as well as our CI/CD strategy based on GitHub Actions, in my next blog post.

 and
and 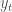 : The prey and predator population densities at time
: The prey and predator population densities at time  respectively
respectively : The rate at which the predator encounters the prey
: The rate at which the predator encounters the prey : The prey growth rate
: The prey growth rate : The rate at which the predator converts prey to new predators
: The rate at which the predator converts prey to new predators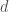 : The predator death rate
: The predator death rate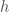 : The time the predator needs to consume the prey (handling time)
: The time the predator needs to consume the prey (handling time) : Environmental carrying capacity
: Environmental carrying capacity : The level of predator interaction
: The level of predator interaction : The fraction of prey that is harvested
: The fraction of prey that is harvested ), radius (
), radius ( ) and weights (
) and weights (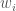 ) of each RBF
) of each RBF  respectively. From Part 1, we opt to use two RBFs where
respectively. From Part 1, we opt to use two RBFs where ![i \in [1,2]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5B1%2C2%5D&bg=ffffff&fg=444444&s=0&c=20201002) to result in six decision variables.
to result in six decision variables.  ) vectors that give rise to them discovered by PyBorg. We also record the total amount of time it takes to optimize the Fisheries over 10,000 NFEs with a population of 500.
) vectors that give rise to them discovered by PyBorg. We also record the total amount of time it takes to optimize the Fisheries over 10,000 NFEs with a population of 500. 




 1,500
1,500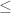 0.5
0.5









