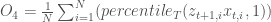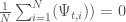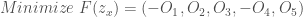In these posts, we explored the complex dynamics of a two-species predator-prey fisheries system. We also visualized various potential scenarios of stability and collapse that result from a variety of system parameter values. We then set up the problem components that include its parameters and their associated uncertainty ranges, performance objectives and the radial basis functions (RBFs) that map the current system state to policy action
Now, we will building off the previous posts and generate the full Pareto-approximate set of performance objectives and their associated decision variable values. We will also specify our robustness multivariate satisficing criteria (Starr, 1963) set by Hadjimichael et al (2020) and use J3, a visualization software, to explore the tradeoff space and identify the solutions that meet these criteria.
To better follow along with our training series, please find the accompanying GitHub repository that contains all the source code here.
A brief recap on decision variables, parameters and performance objectives
In the Fisheries Training series, we describe the system using the following parameters:
and : The prey and predator population densities at time respectively
: The rate at which the predator encounters the prey
: The prey growth rate
: The rate at which the predator converts prey to new predators
: The predator death rate
: The time the predator needs to consume the prey (handling time)
: Environmental carrying capacity
: The level of predator interaction
: The fraction of prey that is harvested
Please refer to Post 0 for further details on the relevance of each parameter.
Our decision variables are the three RBF parameters: the center (), radius () and weights () of each RBF respectively. From Part 1, we opt to use two RBFs where to result in six decision variables.
Next, our objectives are as follows:
Objective 1: Maximize net present value (NPV)
Objective 2: Minimize prey-population deficit
Objective 3: Minimize the longest duration of consecutive low harvest
Objective 4: Minimize worst harvest instance
Objective 5: Minimize harvest variance
Detailed explanation on the formulation and Python execution of the RBFs and objectives can be found in Post 1.
Now that we’ve reviewed the problem setup, let’s get to setting up the code!
Running the full problem optimization
Importing all libraries and setting up the problem
Before beginning, ensure that both Platypus and PyBorg are downloaded and installed as recommended by Post 1. Next, as previously performed, import all the necessary libraries:
# import all required libraries
from platypus import Problem, Real, Hypervolume, Generator
from pyborg import BorgMOEA
from fish_game_functions import *
from platypus import Problem, Real, Hypervolume, Generator
from pyborg import BorgMOEA
import matplotlib.pyplot as plt
import time
import random
We then define the problem by setting the number of variables (nVars), performance objectives (nObjs) and constraints (nCnstr). We also define the upper and lower bounds of each objective. The negative values associated with Objectives 1 and 4 indicate that they are to be maximized.
# Set the number of decision variables, constraints and performance objectives
nVars = 6 # Define number of decision variables
nObjs = 5 # Define number of objectives
nCnstr = 1 # Define number of decision constraints
# Define the upper and lower bounds of the performance objectives
objs_lower_bounds = [-6000, 0, 0, -250, 0]
objs_upper_bounds = [0, 1, 100, 0, 32000]
Then we initialize the algorithm (algorithm) to run over 10,000 function evaluations (nfe) with a starting population of 500 (pop_size):
# initialize the optimization
algorithm = fisheries_game_problem_setup(nVars, nObjs, nCnstr)
nfe = 10000 # number of function evaluations
pop_size = 500 # population size
Storing the Pareto-approximate objectives and decision variables
We are ready to run this (Fisheries) world! But first, we will open two CSV files where we will store the Pareto-approximate objectives (Fisheries2_objs.csv) and their associated decision variables (Fisheries2_vars.csv). These are the (approximately) optimal performance objective values and the RBF () vectors that give rise to them discovered by PyBorg. We also record the total amount of time it takes to optimize the Fisheries over 10,000 NFEs with a population of 500.
# open file in which to store optimization objectives and variables
f_objs = open('Fisheries2_objs.txt', "w+")
f_vars = open('Fisheries2_vars.txt', "w+")
# get number of algorithm variables and performance objectives
nvars = algorithm.problem.nvars
nobjs = algorithm.problem.nobjs
# begin timing the optimization
opt_start_time = time.time()
algorithm = fisheries_game_problem_setup(nVars, nObjs, nCnstr, pop_size=int(pop_size))
algorithm.run(int(nfe))
# get the solution archive
arch = algorithm.archive[:]
for i in range(len(arch)):
sol = arch[i]
# write objectives to file
for j in range(nobjs):
f_objs.write(str(sol.objectives[j]) + " ")
# write variables to file
for j in range(nvars):
f_vars.write(str(sol.variables[j]) + " ")
f.write("\n")
# end timing and print optimization time
opt_end_time = time.time()
opt_total_time = opt_end_time - opt_start_time
f_objs.close()
f_vars.close()
# print the total time to console
print(format"\nTime taken = ", {opt_total_time})
The optimization should take approximately 3,100 seconds or 52 minutes. When the optimization is completed, you should be able to locate the Fisheries2_objs.txt and Fisheries2_vars.txt files in the same folder where the Jupyter notebook is stored.
Post-Processing
To ensure that our output can be used in our following steps, we perform post-processing to convert the .txt files into .csv files.
import numpy as np
# convert txt files to csv
# load the .txt files as numpy matrices
matrix_objs = np.genfromtxt('Fisheries2_objs.txt', delimiter=' ')
matrix_vars = np.genfromtxt('Fisheries2_vars.txt', delimiter=' ')
# reshape the matrices
# the objectives file should have shape (n_solns, nObjs)
# the variables file should have shape (n_solns, nVars)
n_solns = int(matrix_objs.shape[0]/nObjs)
matrix_objs = np.reshape(matrix_objs, (n_solns,nObjs))
matrix_vars = np.reshape(matrix_vars, (n_solns,nVars))
# label the objectives and variables
objs_names = ['NPV', 'Pop_Deficit', 'Low_Harvest', 'Worst_Harvest', 'Variance']
var_names = ['c1', 'r1', 'w1', 'c2', 'r2', 'w2']
# Convert the matrices to dataframes with header names
df_objs = pd.DataFrame(matrix_objs, columns=objs_names)
df_vars = pd.DataFrame(matrix_vars, columns=var_names)
# save the processed matrices as csv files
df_objs.to_csv('Fisheries2_objs.csv', sep=',', index=False)
df_vars.to_csv('Fisheries2_vars.csv', sep=',', index=False)
You should now be able to locate the Fisheries2_objs.csv and Fisheries2_vars.csv within the same folder where you store the Jupyter Notebook.
In the following steps, we will introduce the J3 Visualization Software, which takes .csv files as inputs, to visualize and explore the tradeoff space of the fisheries problem.
Introduction to visualization with J3
J3 is an open-sourced app to produce and share high-dimensional, interactive scientific visualizations. It is part of the larger Project Platypus, which is a collection of libraries that aid in decision-making, optimization, and data visualization. It is influenced by D3.js, which is a JavaScript library for manipulating data using documents (data-driven documents; hence the name). Instead of documents, J3 manipulates data using many-dimensional plots, annotations and animations.
There is a prior post by Antonia Hadjimichael that covers the Python implementation of J3. In this post, we will be exploring the J3 app itself.
Installing and setting up J3
To use J3, you should first install Java. Please follow the directions found on the official Java site to select the appropriate installation package for your operating system.
Next, you can install J3 in either one of two ways:
Download the .zip file from the J3 Github Repository and extract its contents into a desired location on your location machine.
Install using git clone:
cd your-desired-location-path
git clone https://github.com/Project-Platypus/J3.git
You should now see a folder called ‘J3’ located in the path where you chose to extract the repository. Run the J3.exe file within the folder as shown below:
Next, we upload our Fisheries2_objs.csv file into J3:
The GIF below shows the a 3D tradeoff plot that is used to demonstrate the functions that each of the toggles serve. In this 3D plot, the NPV and Harvest Variance are seen on the x- and y-axes, while the Worst-case Harvest is seen on the z-axis. The size of the points represents Lowest Harvest Instance and their colors demonstrate the Population Size.
Other functions not shown above include:
Zooming in by scrolling on your mouse or trackpad
Deleting the annotations by right-clicking on them
Pressing the ‘esc’ key to de-select a point of interest
Next, we can also generate accompanying 2D-scatter and parallel axis plots to this 3D tradeoff figure:
In the parallel axis plot, the direction of preference is upwards. Here, we can visualize the significant tradeoffs between net present cost of the fisheries’ yield and population deficit. If stakeholders wish to maximize the economic value of the fisheries, they may experience unsustainable prey population deficits. The relationship between the remaining objectives is less clear. In J3, you can move the parallel axis plot axes to better visualize the tradeoffs between two objectives:
Here, we observe that there is an additional tradeoff between the minimizing the population deficit and maintaining low occurrences of low-harvest events. From this brief picture, we can observe that the main tradeoffs within the Fisheries system are between ecological objectives such as population deficit and economic objectives such as net present value and harvest.
Note the Brushing tool that appears next to the parallel axis plot. This will be important as we begin our next step, and that is defining our robustness multivariate satisficing criteria.
The multivariate satisficing criteria and identifying robust solutions
The multivariate satisficing criteria is derived from Starr’s domain criterion satisficing measure (Starr, 1962). In Hadjimichael et al. (2020), the multivariate satisficing criteria was selected as it allowed the identification of solutions that meet stakeholders’ competing requirements. In the context of Part 2, we use these criteria to identify the solutions in the Pareto-approximate set that satisfy the expectations of stakeholder. Here, the requirements are as follows:
Net present value (NPV) 1,500
Prey-population deficit 0.5
Longest duration of consecutive low harvest 5
Worst harvest instance 50
Harvest variance 1
Using the brushing tool to highlight only the solutions of interest, we find a pared-down version of the Pareto set. This tells us that not all optimal solutions are realistic, feasible, or satisfactory to decision-makers in the Fisheries system.
Conclusion
Good job with making it this far! Your accomplishments are many:
You ran a full optimization of the Fisheries Problem.
Your downloaded, installed, and learned how to use J3 to visualize and manipulate data to explore the tradeoff space of the Fisheries system.
You learned about Multivariate Satisficing Criteria to identify solution tradeoffs that are acceptable to the stakeholders within the Fisheries system.
In our next post, we will further expand on the concept of the multivariate satisficing criteria and use it to evaluate how 2-3 of the different solutions that were found to initially satisfy stakeholder requirements when tested across more challenging scenarios. But in the meantime, we recommend that you explore the use of J3 on alternative datasets as well, and see if you can come up with an interesting narrative based on your data!
Until then, happy visualizing!
References
Giuliani, M., Castelletti, A., Pianosi, F., Mason, E. and Reed, P., 2016. Curses, Tradeoffs, and Scalable Management: Advancing Evolutionary Multiobjective Direct Policy Search to Improve Water Reservoir Operations. Journal of Water Resources Planning and Management, 142(2).
Hadjimichael, A., Reed, P. and Quinn, J., 2020. Navigating Deeply Uncertain Tradeoffs in Harvested Predator-Prey Systems. Complexity, 2020, pp.1-18.
Starr, M., 1963. Product design and decision theory. Journal of the Franklin Institute, 276(1), p.79.
Our recently published eBook, Addressing Uncertainty in Multisector Dynamics Research, provides several interactive tutorials for hands on training in model diagnostics and uncertainty characterization. This blog post is a preview of an upcoming extension of these trainings featuring an interactive tutorial on time-evolving scenario discovery for the development of adaptive infrastructure pathways for water supply planning. This post builds off the prior tutorial on gradient-boosted trees for scenario discovery.
I’ll first introduce a styled water supply test case featuring two water utilities seeking to develop a cooperative infrastructure investment and management policy over a 45-year planning horizon. I’ll then demonstrate how the utilities can explore evolving vulnerability across the planning period. All code for this demo is available on Github. The code is written in Python, but the workflow is model agnostic and can be paired with simulation models in any language.
Background
The Bedford-Greene metropolitan area (Figure 1) is a stylized water resources test case containing two urban water utilities seeking to develop an infrastructure investment and management strategy to confront growing demands and changing climate. The utilities have agreed to jointly finance and construct a new water treatment plant on Lake Classon, a large regional resource. Both utilities have also identified a set of individual infrastructure options to construct if necessary.
Figure 1: The Bedford-Greene metropolitan area
The utilities have formulated a cooperative and adaptive regional water supply management strategy that uses a risk-of-failure (ROF) metric to trigger both short-term drought mitigation actions (water use restrictions and treated transfers between utilities) and long-term infrastructure investment decisions (Figure 2a). ROFs represent a dynamic measure of the utilities’ evolving capacity-to-demand ratios. Both utilities have specified a set of ROF thresholds to trigger drought mitigation actions and plan to actively monitor their short-term ROF on a weekly basis. When a utility’s ROF crosses a specified threhold, the utility will implement drought mitigation actions in the following week. The utilities will also monitor long-term ROF on an annual basis, and trigger infrastructure investment if long-term risk crosses a threshold dictated by the policy. The utilities have also specified a construction order for available infrastructure options.
Figure 2: a) the regional infrastructure investment and management policy. b) adaptive pathways generated across 2,000 deeply uncertain SOWs
The utilities performed a Monte Carlo simulation to evaluate how this policy responds to a wide array of future states of the world (SOWs), each representing a different sample of uncertainties including demand growth rates, changes to streamflows, and financial variables.
The ROF-based policies respond to each SOW by generating a unique infrastructure pathway – a sequence of infrastructure investment decisions over time. Infrastructure pathways across 2,000 SOWs are shown in Figure 2b. Three clusters summarizing infrastructure pathways are plotted as green lines which represent the median week that options are triggered. The frequency that each option is triggered across all SOWs is plotted as the shading behind the lines. Bedford relies on the Joint Water Treatment facility and short-term measures (water use restrictions and transfers) to maintain supply reliability. Greene constructs the Fulton Creek reservoir in addition to the Joint Treatment plant and does not strongly rely on short-term measures to combat drought.
The utilities are now interested in evaluating the robustness of their proposed policy, characterizing how uncertainties generate vulnerability and understanding how this vulnerability may evolve over time.
Time-evolving robustness
To measure the robustness of the infrastructure investment and management policy, the two utilities employ a satisficing metric, which measures the fraction of SOWs where the policy is able to meet a set of performance criteria. The utilities have specified five performance criteria that measure the policy’s ability to maintain both supply reliability and financial stability. Performance criteria are shown in Table 1.
Performance criteria
Threshold
Reliability
< 99%
Restriction Frequency
>20%
Worst-case cost
>10 % annual revenue
Peak financial cost
> 80% annual revenue
Stranded assets
> $5/kgal unit cost of expansion
Table 1: Satisficing criteria
Figure 3 shows the evolution of robustness over time for the two utilities. While the cooperative policy is very robust after the first ten years of the planning horizon, it degrades sharply for both utilities over time. Bedford meets the performance criteria in nearly 100% of sampled SOWs after the first 10 years of the planning horizon, but its robustness is reduced to around 30% by the end of the 45-year planning period. Greene has a robustness of over 90% after the first 10 years and degrades to roughly 60% after 45 years. These degradations suggest that the cooperative infrastructure investment and management policy is insufficient to successfully maintain long-term performance in challenging future scenarios. But what is really going on here? The robustness metric aggregates performance across the five criteria shown in Table 1, giving us a general picture of evolving performance, but leaving questions about the nature of the utilities’ vulnerability.
Figure 3: Robustness over time
Figure 4 provides some insight into how utility vulnerability evolves over time. Figure 4 shows the fraction of failure SOWs that can be attributed to each performance criterion when performance is measured in the near term (next 10 years), mid-term (next 22 years), and long-term (next 45 years). Figure 4 reveals that the vulnerability of the two utilities evolves in very different ways over the planning period. Early in the planning period, all of Bedford’s failures can be attributed to supply reliability. As the planning horizon progresses, Bedford’s failures diversify into failures in restriction frequency and worst-case drought management cost, indicating that the utility is generally unable to manage future drought. Bedford likely needs more infrastructure investment than is specified by the policy to maintain supply reliability.
In contrast to Bedford’s performance, Greene begins with vulnerability to supply reliability, but its vulnerability shifts over time to become dominated by failures in peak financial cost and stranded assets – measures of the utility’s financial stability. This shift indicates that while the infrastructure investments specified by the cooperative policy mitigate supply failures by the end of the planning horizon, these investments drive the utility into financial failure in many future scenarios.
Figure 4: Failures over time
Factor mapping and factor ranking
To understand how and why the vulnerability evolves over time, we perform factor mapping. Figure 5 below, shows the uncertainty space projected onto the two most influential factors for Bedford, across three planning horizons. Each point represents a sampled SOW, red points represent SOWs that resulted in failure, while white points represent SOWs that resulted in success. The color in the background shows the predicted regions of success and failure from the boosted trees classification.
Figure 4 indicates that Bedford’s vulnerability is primarily driven by rapid and sustained demand growth and this vulnerability increases over time. When evaluated using a 22-year planning horizon, the utility only appears vulnerable to extreme values of near-term demand growth, combined with low values of restriction effectiveness. This indicates that the utility is relying on restrictions to mitigate supply failures, and is vulnerable when they do not work as anticipated. When evaluated over the 45-year planning horizon, Bedford’s failure is driven by rapid and sustained demand growth. If near-term demand grows faster than anticipated (scaling factor > 1.0 on the horizontal axis), the utility will likely fail to meet its performance criteria. If near-term demand is lower than anticipated, the utility may still fail to meet performance criteria if under conditions of high mid-term demand growth. These results provide further evidence that the infrastructure investment and management policy is insufficient to meet Bedford’s long-term water supply needs.
Figure 5: Time-evolving factor maps for Bedford
Greene’s vulnerability (Figure 6) evolves very differently from Bedford’s. Greene is vulnerable to high-demand scenarios in the near term, indicating that its current infrastructure is insufficient to meet rapidly growing demands. Greene can avoid this failure under scenarios where the construction permitting time multiplier is the lowest, indicating that new infrastructure investment can meet the utility’s near-term supply needs. When evaluated across a 22-year planning horizon, the utility fails when near-term demand is high and restriction effectiveness is low, a similar failure mode to Bedford. However, the 22-year planning horizon reveals a second failure mode – low demand growth. This failure mode is responsible for the stranded assets failures shown in Figure 3. This failure mode increases when evaluated across the 45-year planning horizon, and is largely driven by low-demand futures when the utility does not generate the revenue to cover debt service payments needed to fund infrastructure investment.
Figure 6: Time-evolving factor maps for Greene
The factor maps in Figures 5 and 6 only show the two most influential factors determined by gradient boosted trees, however, the utilities are vulnerable to other sampled uncertainties. Figure 7 shows the factor importance as determined by gradient boosted trees for both utilities across the three planning horizons. While near-term demand growth is important for both utilities under all three planning horizons, the importance of other factors evolves over time. For example, restriction effectiveness plays an important role for Greene under the 22-year planning horizon but disappears under the 45-year planning horizon. In contrast, the bond interest rate is important for predicting success over the 45-year planning horizon, but does not appear important over the 10- or 22-year planning horizons. These findings highlight how assumptions about the planning period can have a large impact on modeling outcomes.
Welcome to the second post in the Fisheries Training Series, in which we are studying decision making under deep uncertainty within the context of a complex harvested predator-prey fishery. The accompanying GitHub repository, containing all of the source code used throughout this series, is available here. The full, in-depth Jupyter Notebook version of this post is available in the repository as well.
A brief re-cap of the harvested predator-prey model
Formulation of the harvesting policy and an overview of radial basis functions (RBFs)
Formulation of the policy objectives
A simulation model for the harvested system
Optimization of the harvesting policy using the PyBorg MOEA
Installation of Platypus and PyBorg*
Optimization problem formulation
Basic MOEA diagnostics
Note *The PyBorg MOEA used in this demonstration is derived from the Borg MOEA and may only be used with permission from its creators. Fortunately, it is freely available for academic and non-commercial use. Visit BorgMOEA.org to request access.
Now, onto the tutorial!
Harvested predator-prey model
In the previous post, we introduced a modified form of the Lotka-Volterra system of ordinary differential equations (ODEs) defining predator-prey population dynamics.
This modified version includes a non-linear predator population growth dynamic original proposed by Arditi and Akçakaya (1990), and includes a harvesting parameter, . This system of equations is defined in Hadjimichael et al. (2020) as:
Where is the prey population being harvested and is the predator population. Please refer to Post 0 of this series for the rest of the parameter descriptions, and for insights into the non-linear dynamics that result from these ODEs. It also demonstrates how the system alternates between ‘basins’ of stability and population collapse.
Harvesting policy
In this post, we instead focus on the generation of harvesting policies which can be operated safely in the system without causing population collapse. Rather than assigning a deterministic (specific, pre-defined) harvest effort level for every time period, we instead design an adaptive policy which is a function of the current state of the system:
The problem then becomes the optimization of the control rule, , rather than specific parameter values, . The process of optimizing the parameters of a state-aware control rule is known as Direct Policy Search (DPS; Quinn et al, 2017).
Previous work done by Quinn et al. (2017) showed that an adaptive policy, generated using DPS, was able to navigate deeply uncertain ecological tipping points more reliably than intertemporal policies which prescribed specific efforts at each timestep.
Radial basis functions
The core of the DPS method are radial basis functions (RBFs), which are flexible, parametric function formulations that map the current state of the system to policy action. A previous study by Giuliani et al (2015) demonstrated that RBFs are highly effective in generating Pareto-approximate sets of solutions, and that they perform well when applied to horizons different from the optimized simulation horizon.
There are various RBF approaches available, such as the cubic RBF used by Quinn et al. (2017). Here, we use the Gaussian RBF introduced by Hadjimichael et al. (2020), where the harvest effort during the next timestep, , is mapped to the current prey population levels, by the function:
In this formulation and are the center, radius, and weights of each RBF respectively. Additionally, is the number of RBFs used in the function; in this study we use RBFs. With two RBFs, there are a total of 6 parameters. Increasing the number of RBFs allows for more flexible function forms to be achieved. However, two RBFs have been shown to be sufficient for this problem.
The sum of the weights must be equal to one, such that:
The function harvest_streategy() is contained within the fish_game_functions.py script, which can be accessed here in the repository.
A simplified rendition of the harvest_strategy() function, evaluate_RBF(), is shown below and uses the RBF parameter values (i.e., ), and the current prey population, to calculate the next year’s harvesting effort.
import numpy as np
import matplotlib.pyplot as plt
def evaluate_RBF(x, RBF_params, nRBFs):
"""
Parameters:
-----------
x : float
The current state of the system.
RBF_params : list [3xnRBFs]
The RBF parameters in the order of [c, r, w,...,c, r, w].
nRBFs : int
The number of RBFs used in the mapping function.
Returns:
--------
z : float
The policy action.
"""
c = RBF_params[0::3]
r = RBF_params[1::3]
w = RBF_params[2::3]
# Normalize the weights
w_norm = []
if np.sum(w) != 0:
for w_i in w:
w_norm.append(w_i / np.sum(w))
else:
w_norm = (1/nRBFs)*np.ones(len(w))
z = 0.0
for i in range(nRBFs):
# Avoid division by zero
if r[i] != 0:
z = z + w[i] * np.exp(-((x - c[i])/r[i])**2)
else:
z = z + w[i] * np.exp(-((x - c[i])/(10**-6))**2)
# Impose limits on harvest effort
if z < 0:
z = 0
elif z > 1:
z = 1
return z
To better understand the nature of the harvesting policy, it is helpful to visualize the policy function, .
For some arbitrary selection of RBF parameters:
The following function will plot the harvesting strategy:
def plot_RBF_policy(x_range, x_label, y_range, y_label, RBF_params, nRBFs):
"""
Parameters:
-----------
RBF_params : list [3xnRBFs]
The RBF parameters in the order of [c, r, w,...,c, r, w].
nRBFs : int
The number of RBFs used in the mapping function.
Returns:
--------
None.
"""
# Step size
n = 100
x_min = x_range[0]
x_max = x_range[1]
y_min = y_range[0]
y_max = y_range[1]
# Generate data
x_vals = np.linspace(x_min, x_max, n)
y_vals = np.zeros(n)
for i in range(n):
y = evaluate_RBF(x_vals[i], RBF_params, nRBFs)
# Check that assigned actions are within range
if y < y_min:
y = y_min
elif y > y_max:
y = y_max
y_vals[i] = y
# Plot
fig, ax = plt.subplots(figsize = (5,5), dpi = 100)
ax.plot(x_vals, y_vals, label = 'Policy', color = 'green')
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_title('RBF Policy')
plt.show()
return
Let’s take a look at the policy that results from the random RBF parameters listed above. Setting my problem-specific inputs, and running the function:
This policy does not make much intuitive sense… why should harvesting efforts be decreased when the fish population is large? Well, that’s because we chose these RBF parameter values randomly.
To demonstrate the flexibility of the RBF functions and the variety of policy functions that can result from them, I generated a few (n = 7) policies using a random sample of parameter values. The parameter values were sampled from a uniform distribution over each parameters range: . Below is a plot of the resulting random policy functions:
Fig: Many random RBF policies, showing flexibility of RBFs.
Finding the sets of RBF parameter values that result in Pareto-optimal harvesting policies is the next step in this process!
Harvest strategy objectives
We take a multi-objective approach to the generation of a harvesting strategy. Given that the populations are vulnerable to collapse, it is important to consider ecological objectives in the problem formulation.
Here, we consider five objectives, described below.
Objective 1: Net present value
The net present value (NPV) is an economic objective corresponding to the amount of fish harvested.
During the simulation-optimization process (later in this post), we simulate a single policy times, and take the average objective score over the range of simulations. This method helps to account for variability in expected outcomes due to natural stochasticity. Here, we use realizations of stochasticity.
With that in mind, the NPV () is calculated as:
where is the discount rate which converts future benefits to present economic value, here .
Objective 2: Prey population deficit
The second objective aims to minimize the average prey population deficit, relative to the prey population carrying capacity, :
Objective 3: Longest duration of consecutive low harvest
In order to maintain steady harvesting levels, we minimize the longest duration of consecutive low harvests. Here, a subjective definition of low harvest is imposed. In a practical decision making process, this threshold may be solicited from the relevant stakeholders.
Objective 3 is defined as:
where
And the low harvest limit is: .
Objective 4: Worst harvest instance
In addition to avoiding long periods of continuously low harvest, the stakeholders have a desire to limit financial risks associated with very low harvests. Here, we minimize the worst 1% of harvest.
The fourth objective is defined as:
Objective 5: Harvest variance
Lastly, policies which result in low harvest variance are more easily implemented, and can limit corresponding variance in fish populations.
The last objective minimizes the harvest variance, with the objective score defined as:
Constraint: Avoid collapse of predator population
During the optimization process, we are able to include constraints on the harvesting policies.
Since population collapse is a stable equilibrium point, from which the population will not regrow, it is imperative to consider policies which prevent collapse.
With this in mind, the policy must not result in any population collapse across the realizations of environmental stochasticity. Mathematically, this is enforced by:
where
Problem formulation
Given the objectives described above, the optimization problem is:
Simulation model of the harvested system
Here, we provide an overview of the fish_game_5_objs() model which combines many of the preceding topics. The goal for this model is to take a set of RBF parameters, which define the harvesting strategy, simulate the policy for some length of time, and then return the objective scores resulting from the policy.
Later, this model will allow for the optimization of the harvesting policy RBF parameters through a Multi-Objective Evolutionary Algorithm (MOEA). The MOEA will evaluate many thousands of policies (RBF parameter combinations) and attempt to find, through evolution, those RBF parameters which yield best objective performance.
A brief summary of the model process is described here, but the curious learner is encouraged to take a deeper look at the code and dissect the process.
The model can be understood as having three major sections:
Initialization of storage vectors, stochastic variables, and assumed ODE parameters.
Simulation of policy and fishery populations over time period T.
Calculation of objective scores.
def fish_game_5_objs(vars):
"""
Defines the full, 5-objective fish game problem to be solved
Parameters
----------
vars : list of floats
Contains the C, R, W values
Returns
-------
objs, cnstr
"""
# Get chosen strategy
strategy = 'Previous_Prey'
# Define variables for RBFs
nIn = 1 # no. of inputs (depending on selected strategy)
nOut = 1 # no. of outputs (depending on selected strategy)
nRBF = 2 # no. of RBFs to use
nObjs = 5
nCnstr = 1 # no. of constraints in output
tSteps = 100 # no. of timesteps to run the fish game on
N = 100 # Number of realizations of environmental stochasticity
# Define assumed system parameters
a = 0.005
b = 0.5
c = 0.5
d = 0.1
h = 0.1
K = 2000
m = 0.7
sigmaX = 0.004
sigmaY = 0.004
# Initialize storage arrays for populations and harvest
x = np.zeros(tSteps+1) # Prey population
y = np.zeros(tSteps+1) # Predator population
z = np.zeros(tSteps+1) # Harvest effort
# Create array to store harvest for all realizations
harvest = np.zeros([N,tSteps+1])
# Create array to store effort for all realizations
effort = np.zeros([N,tSteps+1])
# Create array to store prey for all realizations
prey = np.zeros([N,tSteps+1])
# Create array to store predator for all realizations
predator = np.zeros([N,tSteps+1])
# Create array to store metrics per realization
NPV = np.zeros(N)
cons_low_harv = np.zeros(N)
harv_1st_pc = np.zeros(N)
variance = np.zeros(N)
# Create arrays to store objectives and constraints
objs = [0.0]*nObjs
cnstr = [0.0]*nCnstr
# Create array with environmental stochasticity for prey
epsilon_prey = np.random.normal(0.0, sigmaX, N)
# Create array with environmental stochasticity for predator
epsilon_predator = np.random.normal(0.0, sigmaY, N)
# Go through N possible realizations
for i in range(N):
# Initialize populations and values
x[0] = prey[i,0] = K
y[0] = predator[i,0] = 250
z[0] = effort[i,0] = harvest_strategy([x[0]], vars, [[0, K]], [[0, 1]], nIn, nOut, nRBF)
NPVharvest = harvest[i,0] = effort[i,0]*x[0]
# Go through all timesteps for prey, predator, and harvest
for t in range(tSteps):
# Solve discretized form of ODE at subsequent time step
if x[t] > 0 and y[t] > 0:
x[t+1] = (x[t] + b*x[t]*(1-x[t]/K) - (a*x[t]*y[t])/(np.power(y[t],m)+a*h*x[t]) - z[t]*x[t])* np.exp(epsilon_prey[i]) # Prey growth equation
y[t+1] = (y[t] + c*a*x[t]*y[t]/(np.power(y[t],m)+a*h*x[t]) - d*y[t]) *np.exp(epsilon_predator[i]) # Predator growth equation
# Solve for harvesting effort at next timestep
if t <= tSteps-1:
if strategy == 'Previous_Prey':
input_ranges = [[0, K]] # Prey pop. range to use for normalization
output_ranges = [[0, 1]] # Range to de-normalize harvest to
z[t+1] = harvest_strategy([x[t]], vars, input_ranges, output_ranges, nIn, nOut, nRBF)
# Store values in arrays
prey[i,t+1] = x[t+1]
predator[i,t+1] = y[t+1]
effort[i,t+1] = z[t+1]
harvest[i,t+1] = z[t+1]*x[t+1]
NPVharvest = NPVharvest + harvest[i,t+1]*(1+0.05)**(-(t+1))
# Solve for objectives and constraint
NPV[i] = NPVharvest
low_hrv = [harvest[i,j]<prey[i,j]/20 for j in range(len(harvest[i,:]))] # Returns a list of True values when there's harvest below 5%
count = [ sum( 1 for _ in group ) for key, group in itertools.groupby( low_hrv ) if key ] # Counts groups of True values in a row
if count: # Checks if theres at least one count (if not, np.max won't work on empty list)
cons_low_harv[i] = np.max(count) # Finds the largest number of consecutive low harvests
else:
cons_low_harv[i] = 0
harv_1st_pc[i] = np.percentile(harvest[i,:],1)
variance[i] = np.var(harvest[i,:])
# Average objectives across N realizations
objs[0] = -np.mean(NPV) # Mean NPV for all realizations
objs[1] = np.mean((K-prey)/K) # Mean prey deficit
objs[2] = np.mean(cons_low_harv) # Mean worst case of consecutive low harvest across realizations
objs[3] = -np.mean(harv_1st_pc) # Mean 1st percentile of all harvests
objs[4] = np.mean(variance) # Mean variance of harvest
cnstr[0] = np.mean((predator < 1).sum(axis=1)) # Mean number of predator extinction days per realization
# output should be all the objectives, and constraint
return objs, cnstr
The next section shows how to optimize the harvest policy defined by vars, using the PyBorg MOEA.
A (Very) Brief Overview of PyBorg
PyBorg is the secondary implementation of the Borg MOEA written entirely in Python by David Hadka and Andrew Dircks. It is made possible using functions from the Platypus optimization library, which is a Python evolutionary computing framework.
As PyBorg is Borg’s Python wrapper and thus derived from the original Borg MOEA, it can only be used with permission from its creators. To obtain permission for download, please visit BorgMOEA and complete the web form. You should receive an email with the link to the BitBucket repository shortly.
Installation
The repository you have access to should be named ‘Serial Borg MOEA’ and contain a number of folders, including one called Python/. Within the Python/ folder, you will be able to locate a folder called pyborg. Once you have identified the folder, please follow these next steps carefully:
Check your current Python version. Python 3.5 or later is required to enable PyBorg implementation.
Download the pyborg folder and place it in the folder where this Jupyter Notebook all other Part 1 training material is located.
Install the platypus library. This can be in done via your command line by running one of two options:
Make sure the following training startup files are located within the same folder as this Jupyter Notebook: a) fish_game_functions.py: Contains all function definitions to setup the problem, run the optimization, plot the hypervolume, and conduct random seed analysis. b) Part 1 - Harvest Optimization and MOEA Diagnostics.ipynb: This is the current notebook and where the Fisheries fame will be demonstrated.
We are now ready to proceed!
Optimization of the Fisheries Game
Import all libraries
All functions required for this post can be found in the fish_game_functions.py file. This code is adapted from Antonia Hadjimichael’s original post on exploring the Fisheries Game dynamics using PyBorg.
# import all required libraries
from platypus import Problem, Real, Hypervolume, Generator
from pyborg import BorgMOEA
from fish_game_functions import *
from platypus import Problem, Real, Hypervolume, Generator
from pyborg import BorgMOEA
import time
import random
Formulating the problem
Define number of decision variables, constraints, and specify problem formulation:
# Set the number of decision variables, constraints and performance objectives
nVars = 6 # Define number of decision variables
nObjs = 5 # Define number of objectives
nCnstr = 1 # Define number of decision constraints
# Define the upper and lower bounds of the performance objectives
objs_lower_bounds = [-6000, 0, 0, -250, 0]
objs_upper_bounds = [0, 1, 100, 0, 32000]
Initialize the problem for optimization
We call the fisheries_game_problem_setup.py function to set up the optimization problem. This function returns a PyBorg object called algorithm in this exercise that will be optimized in the next step.
def fisheries_game_problem_setup(nVars, nObjs, nCnstr, pop_size=100):
"""
Sets up and runs the fisheries game for a given population size
Parameters
----------
nVars : int
Number of decision variables.
nObjs : int
Number of performance objectives.
nCnstr : int
Number of constraints.
pop_size : int, optional
Initial population size of the randomly-generated set of solutions.
The default is 100.
Returns
-------
algorithm : pyBorg object
The algorthm to optimize with a unique initial population size.
"""
# Set up the problem
problem = Problem(nVars, nObjs, nCnstr)
nVars = 6 # Define number of decision variables
nObjs = 5 # Define number of objective -- USER DEFINED
nCnstr = 1 # Define number of decision constraints
problem = Problem(nVars, nObjs, nCnstr)
# set bounds for each decision variable
problem.types[0] = Real(0.0, 1.0)
problem.types[1] = Real(0.0, 1.0)
problem.types[2] = Real(0.0, 1.0)
problem.types[3] = Real(0.0, 1.0)
problem.types[4] = Real(0.0, 1.0)
problem.types[5] = Real(0.0, 1.0)
# all values should be nonzero
problem.constraints[:] = "==0"
# set problem function
if nObjs == 5:
problem.function = fish_game_5_objs
else:
problem.function = fish_game_3_objs
algorithm = BorgMOEA(problem, epsilons=0.001, population_size=pop_size)
return algorithm
# initialize the optimization
algorithm = fisheries_game_problem_setup(nVars, nObjs, nCnstr)
Define parameters for optimization
Before optimizing, we have to define our desired population size and number of function evaluations (NFEs). The NFEs correspond to the number of evolutions of the set of solutions. For complex, many-objective problems, it may be necessary for a large NFE.
Here, we start with a small limit on NFE, to test the speed of the optimization. Limiting the optimization to 100 NFE is going to produce relatively poor performing solutions, however it is a good starting point for our diagnostic tests.
init_nfe = 100
init_pop_size = 100
Begin the optimization
In addition to running the optimization, we also time the optimization to get a general estimate on the time the full hypervolume analysis will require.
# begin timing the Borg run
borg_start_time = time.time()
algorithm = fisheries_game_problem_setup(nVars, nObjs, nCnstr, pop_size=int(init_pop_size))
algorithm.run(int(init_nfe))
# end timing and print optimization time
borg_end_time = time.time()
borg_total_time = borg_end_time - borg_start_time
print(f"borg_total_time={borg_total_time}s")
Output: borg_total_time=33.62936472892761s
NOTICE: Running the PyBrog MOEA 100 times took ~34 seconds (on the machine which this was written on…). Keep this in mind, that increasing the NFE will require correspondingly more time. If you increase the number too much, your machine may take a long time to compute the final Pareto-front.
Plot the tradeoff surface
Here, we plot a 3-dimensional plot showing the tradeoff between a select number of objectives. If you have selected the 5-objective problem formulation, you should select the three objectives you would like to analyze the tradeoff surface for. Please select the (abbreviated) objective names from the following list:
Objective 1: Mean NPV Objective 2: Mean prey deficit Objective 3: Mean WCLH Objective 4: Mean 1% harvest Objective 5: Mean harvest variance
# Plot objective tradeoff surface
fig_objs = plt.figure(figsize=(8,8))
ax_objs = fig_objs.add_subplot(111, projection='3d')
# Select the objectives to plot from the list provided in the description above
obj1 = 'Mean NPV'
obj2 = 'Mean prey deficit'
obj3 = 'Mean 1% harvest'
plot_3d_tradeoff(algorithm, ax_objs, nObjs, obj1, obj2, obj3)
Fig: Pareto-approximate solutions generated with 100 function evaluations. The star is an ideal solution.
The objectives scores arn’t very good, but that is because the number of function evaluations is so low. In order to get a better set of solutions, we need to run the MOEA for many function evaluations.
The next section demonstrates the change in objective performance with respect to the number of function evaluations.
MOEA Diagnostics
A good MOEA is assessed by it’s ability to quickly converge to a set of solutions (the Pareto-approximate set) that is also diverse. This means that the final set of solutions is close to the true set, as well as covers a large volume of the multi-dimensional problem space. There are three quantitative metrics via which convergence and diversity are evaluated:
Generational distance approximates the average distance between the true Pareto front and the Pareto-approximate reference set that your MOEA identifies. It is the easiest metric to meet.
Epsilon indicator is a harder metric than generational distance to me et. A high-performing MOEA will have a low epsilon indicator value when the distance of its worst-performing approximate solution from the true Pareto set is small.
Hypervolume measures the ‘volume’ that a Pareto front covers across all dimensions of a problem. It is the hardest metric to meet and the most computationally intensive.
Both the generational distance and epsilon indicator metrics require a reference set, which is the known, true Pareto front. Conversely, the hypervolume does not have such a requirement. Given that the Fisheries Game is a complex, multi-dimensional, many-stakeholder problem with no known solution, the hypervolume metric is thus the most suitable to evaluate the ability of PyBorg to quickly converge to a diverse Pareto-approximate set of solutions.
The hypervolume is a measure of the multi-dimensional volume dominated by the approximated Pareto front. As the Pareto front advances toward the “ideal” solution, this value approaches 1.
The efficiency of an MOEA in optimizing a solution can be considered by measuring the hypervolume with respect to the number of function evaluations. This allows the user to understand how quickly the MOEA is converging to a good set of solutions, and how many function evaluations are needed to achieve a good set of solutions.
Defining hypervolume parameters
First, we define the maximum number of function evaluations (maxevals) and the NFE step size (frequency) for which we would like to evaluate the problem hypervolume over. Try modifying these values to see how the plot changes.
Mind that the value of maxevals should always be more than that of your initial NFE, and that the value of frequency should be less than that of the initial NFE. Both values should be integer values.
Also be mindful that increasing the maxevals > 1000 is going to result in long runtimes.
maxevals = 500
frequency = 100
Plotting the hypervolume
Using these parameters, we then plot the hypervolume graph, showing the change in hypervolume value over the NFEs.
Generally, RSA is performed to track an algorithm’s performance during search. In addition, it is also done to determine if an algorithm has discovered an acceptable approximation of the true Pareto set. More details on RSA can be found here in a blog post by Dave Gold.
For the Fisheries Game, we conduct RSA to determine if PyBorg’s performance is sensitive to the size of its initial population. We do this using the folllowing steps:
Run an ensemble of searches, each starting with a randomly sampled set of initial conditions (aka “random seeds”)
Combine search results across all random seeds to generate a “reference set” that contains only the best non-dominated solutions across the ensemble
Repeat steps 1 and 2 for an initial population size of 200, 400, etc.
pop_size_list = [100, 200, 400, 800, 1000]
fig_rand_seed = plt.figure(figsize=(10,7))
ax_rand_seed = fig_rand_seed.add_subplot()
for p in range(len(pop_size_list)):
fisheries_game_problem_setup(nVars, nObjs, nCnstr, pop_size_list[p])
algorithm = fisheries_game_problem_setup(nVars, nObjs, nCnstr, pop_size=int(init_pop_size))
algorithm.run(int(init_nfe))
plot_hvol(algorithm, maxevals, frequency, objs_lower_bounds, objs_upper_bounds,
ax_rand_seed, pop_size_list[p])
plt.title('PyBorg Random Seed Analysis')
plt.xlabel('Number of Function Evaluations')
plt.ylabel('Hypervolume')
plt.legend()
plt.show()
Notice that the runs performed with different initial population sizes tend to converge toward a similar hypervolume value after 500 NFEs.
This reveals that the PyBorg MOEA is not very sensitive to the specific initial parameters; it is adaptable enough to succeed under different configurations.
Conclusion
A classic decision-making idiom says ‘defining the problem is the problem’. Hopefully, this post has revealed that to be true; we have shown that changes to the harvesting strategy functions, simulation model, or objective scores can result in changes to the resulting outcomes.
And if you’ve made it this far, congratulations! Take a minute to think back on the progression of this post: we revisited the harvested predator-prey model, formulated the harvesting policy using RBFs, and formulated the policy objectives and its associated simulation model. Next, we optimized the harvesting policy using the PyBorg MOEA and performed basic MOEA diagnostics using hypervolume as our measure, and executed random seed analysis.
If you’ve progressed through this tutorial using the Jupyter Notebook, we encourage you to re-visit the source code involved in this process. The next advisable step is to re-produce this problem from scratch, as this is the best way to develop a detailed understanding of the process.
Next time, we will explore the outcomes of this optimization, by considering the tradeoffs present across the Pareto set of solutions.
In the previous blog post, we performed a simple sensitivity analysis using the Delta Moment-Independent Global Sensitivity Analysis method to identify the decision variables that will most likely cause changes in performance should their recommended values change. In this post, we will end out the MORDM series by performing scenario discovery to identify combinations of socioeconomic and/or hydroclimatic scenarios that result in the utilities being unable to meet their satisficing using Gradient Boosted Trees (Boosted Trees).
Revisiting the concept of the satisficing criteria
The satisficing criteria method is one of three approaches for defining robust strategies as outlined by Lempert and Collins (2007). It defines a robust strategy as a portfolio or set of actions that, according to a set of predetermined criteria outlined by the decision-maker(s), perform reasonably well across a wide range of possible scenarios. It does not have to be optimal (Simon, 1959). In the context of the Research Triangle, this approach is quantified using the domain criterion method (Starr, 1962) where robustness is calculated as the fraction of states of the world (SOWs) in which a portfolio meets or exceeds the criteria (Herman et al, 2014). This approach was selected for two reasons: the nature of the visualization used to communicate alternatives and uncertainty for the test case, and the elimination of the need to know the probability distributions of the uncertain SOWs.
The remaining two approaches are the regret-based approach (choosing a solution that minimizes performance degradation relative to degree of uncertainty in SOWs) and the open options approach (choosing a portfolio that keeps as many options open as possible).
For the Research Triangle, the satisficing criteria are as follows:
Supply reliability (Reliability) should be at least 98% in all SOWs.
The frequency of water-use restrictions (Restriction frequency) should be no more than 10% across all SOWS.
The worst-case cost of drought mitigation actions (Worst-case cost) should be no more than 10% across all SOWs.
This brings us to the following questions: under what conditions do the portfolios fail to meet these satisficing criteria?
Gradient Boosted Trees for scenario discovery
One drawback of using ROF metrics to define the portfolio action rules within the system is the introduction of SOW combinations that cause failure (failure regions) that are non-linear and non-convex (Trindade et al, 2019). It thus becomes necessary to use an model-free, unbiased approach that can classify non-linear success-failure regions while remaining easy to interpret.
Cue Gradient Boosted Trees, or Boosted Trees. This is a tree-based, machine-learn method that uses “rough and moderately inaccurate rules or thumb” to generate “a single, highly-accurate prediction rule”. This aggregation of rough rules of thumb is referred to as a ‘weak learning model’ (Freund and Shapire, 1999), and the final prediction rule is the ‘strong learning model’ that is the result of the boosting process. The transformation from a weak to strong model is conducted via a process of creating weak classifier algorithms that are only slightly better than random guessing and forcing them to continue classifying the scenarios that they previously classified incorrectly. These algorithms are iteratively updated to improve their ability to classify regions of success or failure, turning them into strong learning models.
In this post, we will implement Boosted Trees using the GradientBoostingClassifier function from the SKLearn Python library. Before beginning, we should first install the SKLearn library. In the command line, type in the following:
pip install sklearn
Done? Great – let’s get to the code!
# -*- coding: utf-8 -*-
"""
Created on Sun June 19 18:29:04 2022
@author: Lillian Lau
"""
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
from copy import deepcopy
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
sns.set(style='white')
'''
FUNCTION to check whether performance criteria are met
'''
def check_satisficing(objs, objs_col, satisficing_bounds):
meet_low = objs[:, objs_col] >= satisficing_bounds[0]
meet_high = objs[:, objs_col] <= satisficing_bounds[1]
meets_criteria = np.hstack((meet_low, meet_high)).all(axis=1)
return meets_criteria
Here, we import all required libraries and define a function, check_satisficing, that evaluates the performance of a given objective to see if it meets the criteria set above.
Next, we define shorthand names for the performance objectives and the DU SOWs (here referred to as ‘robust decision-making parameters’, or RDMs. One SOW is defined by a vector that contains one sampled parameter from deeply uncertain demand, policy implementation and hydroclimatic realizations. But how are these SOWs generated?
The RDM files shown in the code block above actually lists multipliers for the baseline input parameters. These multipliers scale the input up or down, widening the envelope of uncertainty and enabling the generate of more challenging scenarios as shown in the figure above. Next, remember how we used 1000 different hydroclimatic realizations to perform optimization with Borg? We will use the same 1000 realizations and pair each of them with one set of these newly-generated, more extreme scenarios as visualized in the image below. This will result in a total of (1000 x 100) different SOWs.
Each portfolio discovered during the optimization step is then evaluated over these SOWs (shown above) to identify if they meet or violate the satisficing criteria. The procedure to assess the ability of a portfolio to meet the criteria is performed below:
Following this, we apply the GradientBoostingClassifier to extract the parameters that most influence the ability of a portfolio to meet the satisficing criteria:
'''
Fit a boosted tree classifier and extract important features
'''
for j in range(len(utils)):
gbc = GradientBoostingClassifier(n_estimators=200,
learning_rate=0.1,
max_depth=3)
# fit the classifier to each utility's sd
# change depending on utility being analyzed!!
criteria_analyzed = utils[j]
df_to_fit = satisficing_dict[criteria_analyzed]
gbc.fit(all_params, df_to_fit)
feature_ranking = deepcopy(gbc.feature_importances_)
feature_ranking_sorted_idx = np.argsort(feature_ranking)
feature_names_sorted = [factor_names[i] for i in feature_ranking_sorted_idx]
feature1_idx = len(feature_names_sorted) - 1
feature2_idx = len(feature_names_sorted) - 2
feature_figpath = 'YourFilePath/WaterPaths/post_processing/BT_Figures/'
print(feature_ranking_sorted_idx)
feature_figname = feature_figpath + 'BT_' + criteria_analyzed + '.jpg'
fig = plt.figure(figsize=(8, 8))
ax = fig.gca()
ax.barh(np.arange(len(feature_ranking)), feature_ranking[feature_ranking_sorted_idx])
ax.set_yticks(np.arange(len(feature_ranking)))
ax.set_yticklabels(feature_names_sorted)
ax.set_xlim([0, 1])
ax.set_xlabel('Feature ranking')
plt.tight_layout()
plt.savefig(feature_figname)
'''
7 - Create factor maps
'''
# select top 2 factors
fm_figpath = 'YourFilePath/WaterPaths/post_processing/BT_Figures/'
fm_figname = fm_figpath + 'factor_map_' + criteria_analyzed + '.jpg'
selected_factors = all_params[:, [feature_ranking_sorted_idx[feature1_idx],
feature_ranking_sorted_idx[feature2_idx]]]
gbc_2_factors = GradientBoostingClassifier(n_estimators=200,
learning_rate=0.1,
max_depth=3)
# change this one depending on utility and compSol being analyzed
gbc_2_factors.fit(selected_factors, df_to_fit)
x_data = selected_factors[:, 0]
y_data = selected_factors[:, 1]
x_min, x_max = (x_data.min(), x_data.max())
y_min, y_max = (y_data.min(), y_data.max())
xx, yy = np.meshgrid(np.arange(x_min, x_max*1.001, (x_max-x_min)/100),
np.arange(y_min, y_max*1.001, (y_max-y_min)/100))
dummy_points = list(zip(xx.ravel(), yy.ravel()))
z = gbc_2_factors.predict_proba(dummy_points)[:,1]
z[z<0] = 0
z = z.reshape(xx.shape)
fig_factormap = plt.figure(figsize = (10,8))
ax_f = fig_factormap.gca()
ax_f.contourf(xx, yy, z, [0, 0.5, 1], cmap='RdBu', alpha=0.6, vmin=0, vmax=1)
ax_f.scatter(selected_factors[:,0], selected_factors[:,1],
c=df_to_fit, cmap='Reds_r', edgecolor='grey',
alpha=0.6, s=100, linewidths=0.5)
ax_f.set_xlabel(factor_names[feature_ranking_sorted_idx[feature1_idx]], size=16)
ax_f.set_ylabel(factor_names[feature_ranking_sorted_idx[feature2_idx]], size=16)
ax_f.legend(loc='upper center', bbox_to_anchor=(0.5, -0.08),
fancybox=True, shadow=True, ncol=3, markerscale=0.5)
plt.savefig(fm_figname)
The code will result in the following four factor maps:
These factor maps all agree on one thing: the demand growth rate (evaluated via the demand growth multiplier, DMP) is the DU factor that the system is most vulnerable to. This means three things:
Each utility’s success is contingent upon different degrees of demand growth. Cary and Durham, being the smaller utilities with fewer resources, are the most susceptible to changes in demand beyond baseline projections. Raleigh can accommodate a 20% high demand growth rate than initially planned for, likely due to a larger reservoir capacity.
The utilities should be wary of their demand growth projections. Planning and operating their water supply system solely based on the baseline projection of demand growth could be catastrophic both for individual utilities and the region as a whole. This is because as a small deviation from projected demand or the failure to account for uncertainty in planning for demand growth could result in the utility permanently failing to meet its satisficing criteria
MORDM Series Summary
We have come very far since the beginning of our MORDM tutorial using the Research Triangle test case. Here’s a brief recap:
Designing and generating states of the world
We first generated a series of synthetic streamflows using the Kirsch Method to enable the simulation of multiple scenarios to generate more severe, deeply uncertain hydroclimatic events within the region.
The individual and regional performance of these Pareto-approximate actions were then visualized and explored using parallel axis plots.
Defining robustness measures and identifying controls
We defined robustness using the satisficing criteria and calculated the robustness of these set of actions (portfolios) against the effects of challenging states of the world (SOWs) to discover how they fail.
We then performed a simple sensitivity analysis across the average performance of all sixty-nine portfolios of actions, and identified that each utility’s use of water use restrictions, investment in new supply infrastructure, coupled with uncertain demand growth rates most strongly affect performance.
Finally, we used Boosted Trees to discover consequential states of the world that most affect a portfolio’s ability to succeed in meeting all criteria, or to fail catastrophically.
This brings us to the end of our MORDM series! As usual, all files used in this series can be found in the Git Repository here. Hope you found this useful, and happy coding!
References
Freund, Y., Schapire, R., Abe, N., 1999. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 14 (771–780), 1612
Herman, J., Zeff, H., Reed, P., & Characklis, G. (2014). Beyond optimality: Multistakeholder robustness tradeoffs for regional water portfolio planning under deep uncertainty. Water Resources Research, 50(10), 7692-7713. doi: 10.1002/2014wr015338
Lempert, R., & Collins, M. (2007). Managing the Risk of Uncertain Threshold Responses: Comparison of Robust, Optimum, and Precautionary Approaches. Risk Analysis, 27(4), 1009-1026. doi: 10.1111/j.1539-6924.2007.00940.x
Simon, H. A. (1959). Theories of Decision-Making in Economics and Behavioral Science. The American Economic Review, 49(3), 253–283. http://www.jstor.org/stable/1809901
Starr, M. (1963). Product design and decision theory. Journal Of The Franklin Institute, 276(1), 79. doi: 10.1016/0016-0032(63)90315-6
Trindade, B., Reed, P., & Characklis, G. (2019). Deeply uncertain pathways: Integrated multi-city regional water supply infrastructure investment and portfolio management. Advances In Water Resources, 134, 103442. doi: 10.1016/j.advwatres.2019.103442
In the previous post, we defined robustness using the satisficing metric where (1) reliability should be at least 98%, (2) restriction frequency should be not more than 10% and (3) worst-case cost of drought mitigation action should not be more than 10% of annual net volumetric income. To calculate the robustness of these set of actions (portfolios) against the effects of challenging states of the world (SOWs) on the initial set of actions, we once again re-simulated them to discover how they fail.
In this penultimate post, we will perform simple sensitivity analysis across the average performance of all sixty-nine portfolios of actions to understand which uncertainties control the performance of each utility (Raleigh, Durham and Cary) and the regions across all uncertain SOWs.
Calculating average performance across 100 DU SOWs
First, we create a new folder to hold the output of the next few post-processing steps. Navigate to the WaterPaths/ folder and create a folder called post_processing. Now, let’s calculate the average performance of each of the sixty-nine initial portfolios across the 100 DU SOWs that we previously simulated them over. The code for this can be found in the post_processing_code folder under gather_objs.py file and should look like this:
# -*- coding: utf-8 -*-
"""
Created on Mon April 26 2022 11:12
@author: Lillian Bei Jia Lau
Organizes output objectives by mean across RDMs and across solutions
"""
import numpy as np
obj_names = ['REL_C', 'RF_C', 'INF_NPC_C', 'PFC_C', 'WCC_C', \
'REL_D', 'RF_D', 'INF_NPC_D', 'PFC_D', 'WCC_D', \
'REL_R', 'RF_R', 'INF_NPC_R', 'PFC_R', 'WCC_R', \
'REL_reg', 'RF_reg', 'INF_NPC_reg', 'PFC_reg', 'WCC_reg']
'''
Performs regional minimax
'''
def minimax(N_SOLNS, objs):
for i in range(N_SOLNS):
for j in range(5):
if j == 0:
objs[i,15] = np.min([objs[i,0],objs[i,5], objs[i,10]])
else:
objs[i, (j+15)] = np.max([objs[i,j],objs[i,j+5], objs[i,j+10]])
return objs
'''
Calculates the mean performance acorss all SOWs
'''
def mean_performance_across_rdms(objs_by_rdm_dir, N_RDMS, N_SOLNS):
objs_matrix = np.zeros((N_SOLNS,20,N_RDMS), dtype='float')
objs_means = np.zeros((N_SOLNS,20), dtype='float')
for i in range(N_RDMS):
filepathname = objs_by_rdm_dir + str(i) + '_sols0_to_' + str(N_SOLNS) + '.csv'
objs_file = np.loadtxt(filepathname, delimiter=",")
objs_matrix[:,:15,i] = objs_file
objs_file_wRegional = minimax(N_SOLNS, objs_matrix[:,:,i])
objs_matrix[:,:,i] = objs_file_wRegional
array_has_nan = np.isnan(np.mean(objs_matrix[:,3,i]))
if(array_has_nan == True):
print('NaN found at RDM ', str(i))
for n in range(N_SOLNS):
for n_objs in range(20):
objs_means[n,n_objs] = np.mean(objs_matrix[n,n_objs,:])
return objs_means
'''
Calculates the mean performance acorss all SOWs
'''
def mean_performance_across_solns(objs_by_rdm_dir, N_RDMS, N_SOLNS):
objs_matrix = np.zeros((N_SOLNS,20,N_RDMS), dtype='float')
objs_means = np.zeros((N_RDMS,20), dtype='float')
for i in range(N_RDMS):
filepathname = objs_by_rdm_dir + str(i) + '_sols0_to_' + str(N_SOLNS) + '.csv'
objs_file = np.loadtxt(filepathname, delimiter=",")
objs_matrix[:,:15,i] = objs_file
objs_file_wRegional = minimax(N_SOLNS, objs_matrix[:,:,i])
objs_matrix[:,:,i] = objs_file_wRegional
array_has_nan = np.isnan(np.mean(objs_matrix[:,3,i]))
if(array_has_nan == True):
print('NaN found at RDM ', str(i))
for n in range(N_RDMS):
for n_objs in range(20):
objs_means[n,n_objs] = np.mean(objs_matrix[:,n_objs,n])
return objs_means
# change number of solutions available depending on the number of solutions
# that you identified
N_SOLNS = 69
N_RDMS = 100
# change the filepaths
objs_by_rdm_dir = '/yourFilePath/WaterPaths/output/Objectives_RDM'
objs_og_dir = '/yourFilePath/WaterPaths/'
fileoutpath = '/yourFilePath/WaterPaths/post_processing/'
fileoutpath_byRDMs = fileoutpath + 'meanObjs_acrossRDM.csv'
fileoutpath_bySoln = fileoutpath + 'meanObjs_acrossSoln.csv'
# should have shape (N_SOLNS, 20)
objs_byRDM = mean_performance_across_rdms(objs_by_rdm_dir, N_RDMS, N_SOLNS)
# should have shape (N_RDMS, 20)
objs_bySoln = mean_performance_across_solns(objs_by_rdm_dir, N_RDMS, N_SOLNS)
np.savetxt(fileoutpath_byRDMs, objs_byRDM, delimiter=",")
np.savetxt(fileoutpath_bySoln, objs_bySoln, delimiter=",")
This will output two .csv files: meanObjs_acrossRDM.csv contains the average performance of each of the sixty-nine objectives evaluated over 100 DU SOWs, while meanObjs_acrossSoln.csv contains the average performance of all solutions within one SOW. Take some time to understand this difference, as this will be important when performing sensitivity analysis and scenario discovery.
Calculate the robustness of each portfolio to deep uncertainty
Now, let’s identify how each of these solutions perform under a set of more challenging SOWs. Within post_processing_code/, identify the file called calc_robustness_across_rdms.py. It should look like this:
# -*- coding: utf-8 -*-
"""
Created on Mon April 26 2022 11:12
@author: Lillian Bei Jia Lau
Calculates the fraction of RDMs over which each perturbed version of the solution meets all four satisficing criteria
"""
import numpy as np
import pandas as pd
obj_names = ['REL_C', 'RF_C', 'INF_NPC_C', 'PFC_C', 'WCC_C', \
'REL_D', 'RF_D', 'INF_NPC_D', 'PFC_D', 'WCC_D', \
'REL_R', 'RF_R', 'INF_NPC_R', 'PFC_R', 'WCC_R', \
'REL_reg', 'RF_reg', 'INF_NPC_reg', 'PFC_reg', 'WCC_reg']
utilities = ['Cary', 'Durham', 'Raleigh', 'Regional']
'''
Performs regional minimax
'''
def minimax(N_SOLNS, objs):
for i in range(N_SOLNS):
for j in range(5):
if j == 0:
objs[i,15] = np.min([objs[i,0],objs[i,5], objs[i,10]])
else:
objs[i, (j+15)] = np.max([objs[i,j],objs[i,j+5], objs[i,j+10]])
return objs
'''
For each rdm, identify if the perturbed solution version x satisfies the satisficing criteria
'''
def satisficing(df_objs):
for i in range(4):
df_objs['satisficing_C'] = (df_objs['REL_C'] >= 0.98).astype(int) *\
(df_objs['WCC_C'] <= 0.10).astype(int) *\
(df_objs['RF_C'] <= 0.10).astype(int)
df_objs['satisficing_D'] = (df_objs['REL_D'] >= 0.98).astype(int) *\
(df_objs['WCC_D'] <= 0.10).astype(int) *\
(df_objs['RF_D'] <= 0.10).astype(int)
df_objs['satisficing_R'] = (df_objs['REL_R'] >= 0.98).astype(int) *\
(df_objs['WCC_R'] <= 0.10).astype(int) *\
(df_objs['RF_R'] <= 0.10).astype(int)
df_objs['satisficing_reg'] = np.max(df_objs.iloc[:, 20:23])
return df_objs
def calc_robustness(objs_by_rdm_dir, N_RDMS, N_SOLNS):
# matrix structure: (N_SOLNS, N_OBJS, N_RDMS)
objs_matrix = np.zeros((N_SOLNS,20,N_RDMS), dtype='float')
satisficing_matrix = np.zeros((N_SOLNS,4,N_RDMS), dtype='float')
solution_robustness = np.zeros((N_SOLNS,4), dtype='float')
for i in range(N_RDMS):
# get one perturbed instance's behavior over all RDMs
filepathname = objs_by_rdm_dir + str(i) + '_sols0_to_' + str(N_SOLNS) + '.csv'
objs_file = np.loadtxt(filepathname, delimiter=",")
objs_matrix[:,:15,i] = objs_file
objs_file_wRegional = minimax(N_SOLNS, objs_matrix[:,:,i])
objs_matrix[:,:,i] = objs_file_wRegional
# NaN check
array_has_nan = np.isnan(np.mean(objs_matrix[:,3,i]))
if(array_has_nan == True):
print('NaN found at RDM ', str(i))
# for the perturbed instances
for r in range(N_RDMS):
df_curr_rdm = pd.DataFrame(objs_matrix[:, :, r], columns = obj_names)
df_curr_rdm = satisficing(df_curr_rdm)
satisficing_matrix[:N_SOLNS,:,r] = df_curr_rdm.iloc[:,20:24]
for n in range(N_SOLNS):
solution_robustness[n,0] = np.sum(satisficing_matrix[n,0,:])/N_RDMS
solution_robustness[n,1] = np.sum(satisficing_matrix[n,1,:])/N_RDMS
solution_robustness[n,2] = np.sum(satisficing_matrix[n,2,:])/N_RDMS
solution_robustness[:,3] = np.min(solution_robustness[:,:3], axis=1)
return solution_robustness
'''
Change number of solutions available depending on the number of solutions
that you identified and the number of SOWs that you are evaluating them over.
'''
N_RDMS = 100
N_SOLNS = 69
objs_by_rdm_dir = '/scratch/lbl59/blog/WaterPaths/output/Objectives_RDM'
fileoutpath_robustness = '/scratch/lbl59/blog/WaterPaths/post_processing/' + \
'robustness_' + str(N_RDMS) + '_SOWs.csv'
robustness = calc_robustness(objs_by_rdm_dir, N_RDMS, N_SOLNS)
np.savetxt(fileoutpath_robustness, robustness, delimiter=",")
When you run this script from the terminal, you should have a .csv file called ‘robustness_100_SOWs.csv‘ appear in your post_processing/ folder. Now, let’s get onto some sensitivity analysis!
Delta moment-independent sensitivity analysis
The Delta moment-independent (DMI) method (Borgonovo, 2007) is sensitivity analysis method that compares the entire probability distribution of both input and output parameters to estimate the sensitivity of the output to a specific input parameter. It is one of many global sensitivity analysis methods, which in itself is one of two main categories of sensitivity analysis that enables the assessment of the degree to which uncertainty in model inputs map to the degree of uncertainty in model output. For purposes of this test case, the DMI is preferable as it does not rely on any one statistical moment (variance, mean and skew) to describe the dependence of model output to its input parameters. It is also time-sensitive, reflecting the current state of knowledge within the system, which philosophically pairs well with our use of the ROF triggers. More information on alternative global sensitivity methods can be found here.
Within the context of our test case, we will be using the DMI method to identify uncertainties in our decision variables that most strongly influence our performance over the 100 DU SOWs. To perform DMI sensitivity analysis, first navigate to the post_processing/ folder. Within the folder, create two sub-folders called delta_output_DV/ and delta_output_DUF/. This is where all your DMI output will be stored. Next, locate the delta_sensitivity.py file within the post_processing_code/ folder. The code should look similar to the script provided below:
The code above identifies the sensitivity of the average values of all sixty-nine performance objective sets over all 100 deeply-uncertain SOWs to the decision variables. This is why we use the meanObjs_acrossRDM.csv file – this file contains sixty-nine mean values of the performance objectives, where each set of performance objectives inversely maps to their corresponding portfolio of actions.
To identify the sensitivity of performance objectives to the DU factors, change lines 121 to 127 to the following:
# to change depending on whether DV or DUF is being analyzed
dec_vars = duf_numpy[:100,:]
measured_outcomes = objs_mean_soln_df
names = duf_names
mo_names = obj_names
bounds = duf_bounds[:100,:]
rdm = 'DUF'
mode = 'objs'
###
The code above identifies the sensitivity of the average values of all twenty performance objectives over each of the sixty-nine different portfolios to the set of deeply uncertain hydroclimatic and demand scenarios. This is why we use the meanObjs_acrossSoln.csv file – this file contains one hundred mean values of the performance objectives, where each set of performance objectives inversely maps to their corresponding DU SOW.
Great job so far! Now let’s visualize the sensitivity of our output to our input parameters using heatmaps. Before being able to visualize each utility’s performance sensitivity, we must first organize the sensitivity indices of the decision variables into a file containing the indices over all objectives for each utility. The gather_delta.py script does this. Simply change the value of mode on line 11 to ‘DUF‘ to gather the indices for the DU factors.
Running this for the sensitivity to decision variables and DU factors will generate the following images:
Sensitivity of performance objectives to decision variables.
In the figure above, the color of each box represents the sensitivity of a performance objective (y-axis) to a specific decision variable (x-axis). It is interesting to note that the restriction triggers (RT) of all utilities strongly influence each of their individual and regional reliability and restriction frequency. This indicates the potential for regional conflict, as possible errors is operating one utility’s restriction trigger may adversely affect other utilities’ reliabilities and ability to maintain full control over their own use of water-use restrictions. Furthermore, Raleigh’s performance is sensitive to more decision variables than its remaining two counterparts, with it’s worst-case cost (WCC) being affected most by Cary’s infrastructure investments. This observation highlights the importance of careful cooperation between a region’s member utilities to ensure that all partners play their part in maintaining both their own and their counterparts’ performance.
Sensitivity of performance objectives to DU factors.
In this next figure, we observe that uncertainty in demand growth is the only DU factor that significantly drives changes in individual and regional performance. This finding can thus help utilities to focus on demand management programs, or formulate operations and management policies that enable them to more quickly adapt to changes in consumer and industrial demand growth.
Overall, in this post, we have performed a simple sensitivity analysis to identify uncertainties in the decision variables and DU factors that control regional and individual performance. All the code for processing the output data can be found in this GitHub repository here. In the next post, we will end the MORDM blogpost series by performing scenario discovery to map regions of success and failure as defined by our robustness metrics.
References
Borgonovo, E. (2007). A new uncertainty importance measure. Reliability Engineering &Amp; System Safety, 92(6), 771-784. doi: 10.1016/j.ress.2006.04.015
Herman, J. D., Reed, P. M., Zeff, H. B., & Characklis, G. W. (2015). How should robustness be defined for water systems planning under change? Journal of Water Resources Planning and Management,141(10), 04015012. doi:10.1061/(asce)wr.1943-5452.0000509
Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B, & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
Our recently published eBook, Addressing Uncertainty in Multisector Dynamics Research, provides several interactive tutorials for hands on training in model diagnostics and uncertainty characterization. The purpose of this post is to expand upon these trainings by providing a tutorial demonstrating gradient boosted trees for scenario discovery. I’ll first provide some brief background on scenario discovery and gradient boosted trees, then demonstrate a Python implementation on a water supply planning problem. All code here is written in Python, but the workflow is model agnostic, and can be paired with simulation models in any language. I’ve included my code within the text below, but all code and data for this post can also be found in this git repository.
Scenario discovery gradient boosted trees
In water resources planning and management, decision makers are often faced with uncertainty about how their system will change in the future. Traditionally, planners have confronted this uncertainty by developing prespecified narrative scenarios, which reduce the multitude of possible future conditions into a small subset of important future states of the world (a prominent example is the ‘scenario matrix framework’ used to evaluate climate change (O’Neill et al., 2014)). While this approach provides intuitive appeal, it may increase system vulnerability if future conditions do not evolve as decision makers expect (for a detailed critique of scenario based planning see Reed et al., 2022). This vulnerability is especially apparent for systems facing deep uncertainty, where decision makers do not know or cannot agree upon the probability density functions of key system inputs (Kwakkel et al., 2016).
Scenario discovery (Groves and Lempert, 2007) is an exploratory modeling centered approach that seeks to discover consequential future scenarios using computational experiments rather than relying on prespecified information. To perform scenario discovery, decision makers first identify a set of relevant uncertainties and their plausible ranges. Next, an ensemble of these uncertainties is developed by sampling across parameter ranges. Candidate policies are then evaluated across this ensemble and machine learning or data mining algorithms are used to examine which combinations of uncertainties generate vulnerability in the system. These combinations can then be used to develop narrative scenarios to inform implementation and monitoring efforts or new policy development.
A core element of the scenario discovery process is the algorithm used to classify future states of the world. Popular algorithms include the PRIM, CART and logistic regression. Recently, gradient boosted trees have been applied as an alternative classificiation algorithm. Gradient boosted trees have advantages over other scenario discovery algorithms because they can easily capture nonlinear and non-differentiable boundaries in the uncertainty space (which are particularly prevalent in water supply planning problems that have discrete capacity expansion options), are highly resistant to overfitting and provide a clear means of ranking the importance of uncertain factors (Trindade et al., 2020). For a comprehensive overview of gradient boosted trees, see Bernardo’s post here.
Test case: the Sedento Valley
To demonstrate gradient boosted trees for scenario discovery we’ll use the Sedento Valley water supply planning test case (Trindade et al., 2020). In the Sedento Valley, three water utilities seek to discover cooperative water supply managment and infrastructure investment portfolios to meet several conflicting objectives in a system facing deep uncertainty. In this post, we’ll investigate how these deep uncertainties (which include demand growth, the efficacy of water use restrictions, financial variables and parameters governing infrastructure permitting and construction time) impact a utility’s ability to maintain three performance criteria: keeping reliability > 98%, restriction frequency < 20% and worst case cost less than 10% of annual revenue. For simplicity, we’ll focus on one regional water utility named Watertown.
Step 1: create a sample of deeply uncertain states of the world
To start the scenario discovery process, we generate an ensemble of deep uncertainties that represent future states of the world (SOWs). Here, we’ll use Latin Hypercube Sampling with an implementation I found in the Surrogate Modeling Toolbox.
import numpy as np
from smt.sampling_methods import LHS
'''
This script will generate 1000 Latin Hypercube Samples (LHS)
of deeply uncertain system parameters for the Sedento Valley
'''
# create an array storing the ranges of deeply uncertain parameters
DU_factor_limits = np.array([
[0.9, 1.1], # Watertown restriction efficacy
[0.9, 1.1], # Dryville restriction efficacy
[0.9, 1.1], # Fallsland restriction efficacy
[0.5, 2.0], # Demand growth rate multiplier
[1.0, 1.2], # Bond term
[0.6, 1.0], # Bond interest rate
[0.6, 1.4], # Discount rate
[0.75, 1.5], # New River Reservoir permitting time
[1.0, 1.2], # New River Reservoir construction time
[0.75, 1.5], # College Rock Reservoir (low) permitting time
[1.0, 1.2], # College Rock Reservoir (low) construction time
[0.75, 1.5], # College Rock Reservoir (high) permitting time
[1.0, 1.2], # College Rock Reseroir (high) construction time
[0.75, 1.5], # Water Reuse permitting time
[1.0, 1.2], # Water Reuse construction time
[0.8, 1.2], # Inflow amplitude
[0.2, 0.5], # Inflow frequency
[-1.57, 1.57]]) # Inflow phase
# Use the smt package to set up the LHS sampling
sampling = LHS(xlimits=DU_factor_limits)
# We will create 1000 samples
num = 1000
# Create the actual sample
x = sampling(num)
# save to a csv file
np.savetxt('DU_factors.csv', x, delimiter=',')
Step 2: Evaluate performance across SOWs
Next, we’ll evaluate the performance of our policy across the LHS sample of DU factors. For the Sedento Valley test case, we use WaterPaths, an open-source simulation system for integrated water supply portfolio management and infrastructure investment planning (for more see Trindade et al., 2020). This step is not included in the git repository as it requires high-performance computing for this system, but results can be found in the “Model_output.csv” file. For simulation details, see Gold et al., 2022.
Step 3: Convert model output into a boolean array for classification
To perform classification, we need to convert the results of our simulations to a binary array classifying each SOW as a “success” or “failure” based on whether the policy met the performance criteria under the SOW. First, we define a small function to determine if an SOW meets a set of criteria, then we apply this function to our results. We also load the DU factor LHS sample.
# First, define a function to check whether performance criteria are met
def check_criteria(objectives, crit_objs, crit_vals):
"""
Determines if an objective meets a given set of criteria for a set of SOWs
inputs:
objectives: np array of all objectives across a set of SOWs
crit_objs: the column index of the objective in question
crit_vals: an array containing [min, max] of the values
returns:
meets_criteria: an numpy array containing the SOWs that meet both min and max criteria
"""
# check max and min criteria for each objective
meet_low = objectives[:, crit_objs] >= crit_vals[0]
meet_high = objectives[:, crit_objs] <= crit_vals[1]
# check if max and min criteria are met at the same time
meets_criteria = np.hstack((meet_low, meet_high)).all(axis=1)
return meets_criteria
##### Load data and pre-process #####
# load objectives and create input array of boolean values for SD input
Reeval_objectives = np.loadtxt('Model_output.csv', skiprows=1, delimiter=',')
REL = check_criteria(Reeval_objectives, [0], [.979, 1])
RF = check_criteria(Reeval_objectives, [1], [0, 0.10])
WCC = check_criteria(Reeval_objectives, [2], [0, 0.10])
SD_input = np.vstack((REL, RF, WCC)).SD_input(axis=0)
# load DU factors
DU_factors = np.loadtxt('DU_factors.csv', skiprows=1, delimiter=',')
DU_names = ['Watertown Rest. Eff.', 'Dryville Rest. Eff.', 'FSD_inputsland Rest. Eff.',
'Demand Growth Rate', 'Bond Term', 'Bond Interest',
'Discount Rate', 'NRR Perm', 'NRR Const', 'CRR L Perm',
'CRR L Const.', 'CRR H Perm.', 'CRR H Const.', 'WR1 Perm.',
'WR1 Const.', 'Inflows A', 'Inflows m','Inflows p']
Step 4: Fit a boosted trees classifier
After we’ve formatted the data, we’re ready to perform boosted trees classification. There are several packages for boosted trees in Python, here we’ll use the implementation from scikit-learn. We’ll use an ensemble of 200 trees with depth 3 and a learning rate of 0.1. These parameters need to be tuned for the individual problem, I found this nice post that goes into detail on parameter tuning.
##### Boosted Tree Classification #####
from sklearn.ensemble import GradientBoostingClassifier
# create a gradient boosted classifier object
gbc = GradientBoostingClassifier(n_estimators=200,
learning_rate=0.1,
max_depth=3)
# fit the classifier
gbc.fit(DU_factors, SD_input)
Step 5: Examine which DU factors have the most impact on performance criteria
Now we’re ready to examine the results of our classification. First, we’ll examine how important each DU factor is to the classification results generated by boosted trees. To rank the imporance of each DU factor, we examine the percentage decrease in impurity of the ensemble of trees that is associated with each factor. In plain english, this is a measure of how helpful each DU factor is to correctly classifying SOWs. This infromation is generated during the fit of the classifier above and is easily accessible as an attribute of our scikit-learn classifier.
For our example, one deep uncertainty, demand growth rate, clearly stands out as the most influential, as shown in the figure below. A second, the restriction efficacy for Watertown (the utility we’re focusing on), also stands out as a higher level of importance. All other DU factors have little impact on the classification in this case.
##### Factor Ranking #####
# Extract the feature importances
feature_importances = deepcopy(gbc.feature_importances_)
# rank the feature importances and plot
importances_sorted_idx = np.argsort(feature_importances)
sorted_names = [DU_names[i] for i in importances_sorted_idx]
fig = plt.figure(figsize=(8,8))
ax = fig.gca()
ax.barh(np.arange(len(feature_importances)), feature_importances[importances_sorted_idx])
ax.set_yticks(np.arange(len(feature_importances)))
ax.set_yticklabels(sorted_names)
ax.set_xlim([0,1])
ax.set_xlabel('Feature Importance')
plt.tight_layout()
Step 6: Create factor maps
Finally, we visualize the results of our classification through factor mapping. In the plot below, we show the uncertainty space projected onto the two most influential factors, demand growth rate and restriciton efficacy. Each point represents a sampled SOW, red points represent SOWs that resulted in failure, while white points represent SOWs that resulted in success. The color in the background shows the predicted regions of success and failure from the boosted trees classification.
Here we observe that high levels of demand growth are the primary source of vulnerability for the water utility. When restriction efficacy is lower than our estimate (multiplier < 1), the utility faces failures at demand growth levels of about 1.7 times the estimated values. When restriction effectiveness is at or above estimates, the acceptable scaling of demand growth raises to about 1.8.
Taken as a whole, these results provide valueable insights for decision makers. From our original 18 deep uncertainties, we have discovered that two are critical for the success of our water supply management policy. Further, we have defined thresholds within the uncertainty space that define scenarios that lead to failure. We can use this information to inform monitoring efforts for the water supply policy, or to inform a new problem formulation that tailors actions to mitigate these vulnerabilities.
##### Factor Mapping #####
# Select the top two factors discovered above
selected_factors = DU_factors[:, [3,0]]
# Fit a classifier using only these two factors
gbc_2_factors = GradientBoostingClassifier(n_estimators=200,
learning_rate=0.1,
max_depth=3)
gbc_2_factors.fit(selected_factors, SD_input)
# plot prediction contours
x_data = selected_factors[:,0]
y_data = selected_factors[:,1]
x_min, x_max = (x_data.min(), x_data.max())
y_min, y_max = (y_data.min(), y_data.max())
# create a grid to makes predictions on
xx, yy = np.meshgrid(np.arange(x_min, x_max * 1.001, (x_max - x_min) / 100),
np.arange(y_min, y_max * 1.001, (y_max - y_min) / 100))
dummy_points = list(zip(xx.ravel(), yy.ravel()))
z = gbc_2_factors.predict_proba(dummy_points)[:, 1]
z[z < 0] = 0.
z = z.reshape(xx.shape)
# plot the factor map
fig = plt.figure(figsize=(10,8))
ax = fig.gca()
ax.contourf(xx, yy, z, [0, 0.5, 1.], cmap='RdBu',
alpha=.6, vmin=0.0, vmax=1)
ax.scatter(selected_factors[:,0], selected_factors[:,1],\
c=SD_input, cmap='Reds_r', edgecolor='grey',
alpha=.6, s= 100, linewidth=.5)
ax.set_xlim([.5, 2])
ax.set_ylim([.9,1.1])
ax.set_xlabel('Demand Growth Multiplier')
ax.set_ylabel('Restriction Eff. Multiplier')
References
Gold, D. F., Reed, P. M., Gorelick, D. E., & Characklis, G. W. (2022). Power and Pathways: Exploring Robustness, Cooperative Stability, and Power Relationships in Regional Infrastructure Investment and Water Supply Management Portfolio Pathways. Earth’s Future, 10(2), e2021EF002472.
Groves, D. G., & Lempert, R. J. (2007). A new analytic method for finding policy-relevant scenarios. Global Environmental Change, 17(1), 73-85.
Kwakkel, J. H., Walker, W. E., & Haasnoot, M. (2016). Coping with the wickedness of public policy problems: approaches for decision making under deep uncertainty. Journal of Water Resources Planning and Management, 142(3), 01816001.
O’Neill, B. C., Kriegler, E., Riahi, K., Ebi, K. L., Hallegatte, S., Carter, T. R., … & van Vuuren, D. P. (2014). A new scenario framework for climate change research: the concept of shared socioeconomic pathways. Climatic change, 122(3), 387-400.
Reed, P.M., Hadjimichael, A., Malek, K., Karimi, T., Vernon, C.R., Srikrishnan, V., Gupta, R.S., Gold, D.F., Lee, B., Keller, K., Thurber, T.B., & Rice, J.S. (2022). Addressing Uncertainty in Multisector Dynamics Research [Book]. Zenodo. https://doi.org/10.5281/zenodo.6110623
Trindade, B. C., Gold, D. F., Reed, P. M., Zeff, H. B., & Characklis, G. W. (2020). Water pathways: An open source stochastic simulation system for integrated water supply portfolio management and infrastructure investment planning. Environmental Modelling & Software, 132, 104772.
In the previous post, we conducted a basic WaterPaths tutorial in which we ran a simulation-optimization of the North Carolina Research Triangle test case (Trindade et al, 2019); across 1000 possible futures, or states of the world (SOWs). To briefly recap, the Research Triangle test case consists of three water utilities in Cary (C), Durham (D) and Raleigh (R). Cary is the main supplier, having a water treatment plant of its own. Durham and Raleigh purchase water from Cary via treated transfers.
Having obtained the .set file containing the Pareto-optimal decision variables and their respective performance objective values, we will now walk through the .set file processing and visualize the decision variables and performance objective space.
Understanding the .set file
First, it is important that the .set file makes sense. The NC_output_MS_S3_N1000.set file should have between 30-80 rows, and a total of 35 columns. The first 20 columns contain values of the decision variables. Note that only Durham and Raleigh have water transfer triggers as they purchase treated water from Cary.
Restriction trigger, RT (C, D, R)
Transfer trigger, TT (D, R)
Jordan Lake allocation, JLA (C, D, R)
Reserve fund contribution as a percentage of total annual revenue, RC (C, D, R)
Insurance trigger, IT (C, D, R)
Insurance payments as a percentage of total annual revenue, IP (C, D, R)
Infrastructure trigger, INF (C, D, R)
The last 15 columns contain the objective values for the following performance objectives of all three utilities:
Reliability (REL) to be maximized
Restriction frequency (RF) to be minimized
Infrastructure net present cost (INF_NPC) to be minimized
Peak financial cost of drought mitigation actions (PFC) to be minimized
Worst-case financial cost of drought mitigation actions (WCC) to be minimized
This reference set needs to be processed to output a .csv file to enable reevaluation for robustness analysis. To do so, run the post_processing.py file found in this GitHub repository in the command line:
python post_processing.py
In addition to post-processing the optimization output files, this file also conduct regional minimax operation, where each regional performance objective is taken to be the objective value of the worst-performing utility (Gold et al, 2019).
This should output two files:
NC_refset.csv No header row. This is the file that will be used to run the re-evaluation for robustness analysis in the next blog post.
NC_dvs_objs.csv Contains a header row. This file that contains the labeled decision variables and objectives, including the minimax regional performance objectives. Will be used for visualizing the reference set’s decision variables and performance objectives.
Visualizing the reference set
Due to the higher number of decision variables, we utilize parallel axis plots to identify how varying the decision variables can potentially affect certain performance objectives. Here, we use the regional reliability performance objective, REL, as an example. Figure 1 below demonstrates how all decision variables vary with regional reliability.
Figure 1: All decision variables for the three utilities. A darker blue indicates a higher degree of reliability.
From Figure 1, most solutions found via the optimization conducted in the previous blog post seem to have relatively high reliability across the full range of decision variable values. It is unclear as to how each decision variable might affect regional reliability. It is thus more helpful to identify specific sets of decision variables (or policies) that enable the achievement of reliability beyond a certain threshold.
With this in mind, we assume that all members of the Triangle require that their collective reliability be at least 98%. This results in the following figure:
Figure 2: All decision variables across the three utilities. The dark lines represent the policies that are at least 98% reliable.
Figure 2 has one clear takeaway: Pareto-optimality does not indicate satisfactory performance. In addition, setting this threshold make the effects of each decision variable clearer. It can be seen that regional reliability is significantly affected by both Durham and Raleigh’s infrastructure trigger (INF). Desirable levels of regional reliability can be achieved when Durham sets a high INF value. Conversely, Raleigh can set lower INF values to benefit from satisfactory reliability. Figure 2 also shows having Durham set a high insurance trigger (IT) may benefit the regional in terms of reliability.
However, there are caveats. Higher INF and IT values for Durham implies that the financial burden of investment and insurance payments are being borne by Raleigh and Cary, as Durham is able to withstand more risk without having to trigger an investment or infrastructure payment. This may affect how each member utility perceives their individual risks and benefits by forming a cooperative contract.
The code to plot these figures can be found under ‘refset_parallel.py’ in the repository.
Robustness analysis and what’s next
So how is setting a threshold value of regional reliability significant?
Within the MORDM framework, robustness is defined using a multivariate satisficing metric (Gold et al, 2019). Depending on the requirements of the stakeholders, a set of criteria is defined that will then be used distinguish between success (all criteria are met) and failure (at least one criteria is not met). Using these criteria, the rest of Pareto-optimal policies are simulated across a number of uncertain SOWs. Each policy’s robustness is then represented by the percent of SOWs in which it meets the minimum performance criteria that has been set.
In this post, we processed the reference set and visualized its decision variable space with respect to each variable’s effect on the reliability performance objective. A similar process can be repeated across all utilities for all performance objectives.
Using the processed reference set, we will conduct multi-criterion robustness analysis using two criteria:
Regional reliability should be at least 98%
Regional restriction frequency should be less than or equal to 20%
We will also conduct sensitivity analysis to identify the the decision variables that most impact regional robustness. Finally, we will conduct scenario discovery to identify SOWs that may cause the policies to fail.
References
Gold, D. F., Reed, P. M., Trindade, B. C., & Characklis, G. W. (2019). Identifying actionable compromises: Navigating multi‐city robustness conflicts to discover cooperative safe operating spaces for regional water supply portfolios. Water Resources Research, 55(11), 9024–9050. https://doi.org/10.1029/2019wr025462
Trindade, B. C., Reed, P. M., & Characklis, G. W. (2019). DEEPLY UNCERTAIN PATHWAYS: Integrated multi-city Regional Water Supply Infrastructure Investment and portfolio management. Advances in Water Resources, 134, 103442. https://doi.org/10.1016/j.advwatres.2019.103442
The previous post described a simple, two-objective test case in which the city of Cary employed risk-of-failure (ROF) triggers as levers to adjust for its preferred tradeoff level between its objectives. The example given showed how ROF triggers allowed Cary to account for future uncertainty in its system inputs, thus enabling it to visualize how their risk appetite would affect their desired outcomes.
In meeting these objectives, different risk thresholds would have affected Cary’s response to extreme events such as floods and droughts, and its ability to fulfill demand. Simply analyzing the tradeoffs between objectives that result from a range of ROF trigger values only presents one side of the story. It is vital to visualize how these performance objectives and tradeoffs manifest in the system’s capacity (pun intended) to store enough water in times of scarcity, and by extension, its ability to fulfill its customers’ demand for water.
Using ROFs allow us to more concretely measure how the dynamics of both storage and demand fulfillment evolve and change over time for a given risk tolerance. In the long term, these dynamics will influence when and where new water infrastructure is built to cope with storage requirements and demand growth, but this is a topic for a future blog post. This week, we will focus on unpacking the dynamic evolution of storage and demand in response to different ROF trigger values.
As a quick refresher, our system is a water supply utility located in Cary, which is a city within the Research Triangle region in North Carolina (Trindade et al, 2017). Cary uses water-use restrictions when a weekly ROF exceeds the threshold of risk that Cary is willing to tolerate (α) during which only 50% of demand is met. More frequent water use restrictions help to maintain the reservoir levels and ensure reliability, which was defined in the previous blog post. However, the decision to implement restrictions (or not) will impact the storage levels of the system. With this in mind, we will first examine storage responds to the triggering of a water use restriction. For context, we consider a scenario in which Cary’s inflow timeseries is only 20% of the original levels. Figure 1 below shows the inflow, demand and storage timeseries for this scenario.
Figure 1: The hydrologic timeseries for Cary given that no water restrictions are implemented in a scenario where inflows are 20% of the original levels.
Cary’s challenge becomes apparent in Figure 1. While inflow decreases over time (fewer peaks), demand is steadily growing and has effectively tripled by the end of the period. This results in periods during which storage levels drop to zero, which occurs once past 2040. Also note that the frequency of low storage peaks have increased in the second half of the period. The following questions can thus be posed:
How does the system’s ROF change with increasing demand and decreasing supply?
How does risk tolerance affect the implementation of water-use restrictions during drought?
How will the system reservoir levels respond to different levels of risk tolerance?
Figure 2: The length of the pink bars denote the nth-week during which the first water use restriction was implemented for a given α-value. This is an indicator of the responsiveness of the system to a drought, or decrease in storage levels. The blue line indicates the percent of storage filled with water.
To answer the first question, it is useful to identify how different values of α affect the first instance of a water-use restriction. Figure 2, generated using ‘rof_dynamics.py‘, demonstrates that lower risk tolerances result in earlier implementations of restrictions. This is reasonable, as an actor who more risk-averse will quickly implement water-use restrictions to maintain reliable levels of storage during a drought. However, an actor who is more willing to tolerate the change of low reservoir levels will delay implementing water use restrictions. The blue line juxtaposed on top of the bars indicates the inflows to the reservoir. After the first period of low flows between weeks 30-40, the plot shows that the amount of inflows do not recover, and is likely insufficient to fill the reservoir to initial levels. With a lower α, an actor is more likely to implement restrictions almost immediately after observing merely a few weeks of low inflows. In contrast, an actor who opts for a higher α will only resort to restrictions after seeing an extended period of low flows during which they can be more certain that restrictions are absolutely necessary.
Answering the second and third questions first require that periods of drought are more definitively quantified. To do this, the standardized streamflow indicator (SSI6) was used. The SSI6 is a method that identifies time periods during which the standardized inflow is less than the 6-month rolling mean (Herman et al, 2016). It detects a drought period when the value of the SSI6 < 0 for three consecutive months and SSI6 < -1 at least once during the three-month period. The juxtaposition of storage-restrictions and the periods of drought will allow us to see where restrictions were imposed and its impacts on reservoir levels for a given demand timeseries.
Figure 3 and Figure 4 are a visualization of how the system’s storage levels responds to drought (the red bars in the lower subplot) by implementing water-use restrictions (the dark red lines in the upper subplot) given α = 1% and α = 15% respectively. Predictably, restrictions coincide with periods of drought as defined by the SSI6. However, with a lower risk tolerance, period of restrictions are longer and more frequent. As Figure 3 shows, an actor with a lower risk tolerance may implement restrictions where only a slight risk of failure exists.
Figure 3: Storage dynamics given α=1%. (Upper subplot) The blue lines indicate the reservoir storage levels in billion gallons per week. The yellow lines are the weekly ROF values, or the likelihood that the percent of water stored will drop below 20% of the reservoir levels. The grey lines indicate where water use restrictions are implemented, and the red dashed line denotes α=2%. (Lower subplot) The zones are where droughts were detected using the SSI6 (Herman et al, 2016) method are highlighted in red.
Compared to α = 1%, an actor who is willing to tolerate higher ROF values (Figure 4 as an example) will implement restrictions less frequently and for shorter periods of time. Although this means that demands are less likely to get disrupted, this also puts water supplies at a higher risk of dropping to critical levels (<20%), as restrictions may not get implemented even during times of drought.
Figure 4: Storage dynamics given α=15%. (Upper subplot) The blue lines indicate the reservoir storage levels in billion gallons per week. The yellow lines are the weekly ROF values, or the likelihood that the percent of water stored will drop below 20% of the reservoir levels. The grey lines indicate where water use restrictions are implemented, and the red dashed line denotes α=15%. (Lower subplot) The zones are where droughts were detected using the SSI6 (Herman et al, 2016) method are highlighted in red.
There is one important thing to note when comparing Figures 3 and 4. When the periods water use restrictions coincide for both α-values (between 2040 and 2050), the actor with a lower tolerance implements water use restrictions at the beginning of both drought periods. This decision makes the biggest difference in terms of the reservoir storage levels. By implementing water use restrictions early and for a longer period of time, Cary’s reservoir levels are consistently kept at levels above 50% of full capacity (given full capacity of 7.45 BG). A different actor with higher risk tolerance resulted in water levels that dropped below the 30% of full capacity during periods of drought.
Although this seems undesirable, recall that the system is said to have failed if the capacity drops below 20% of full capacity. Herein lies the power of using an ROF metric – questions 2 and 3 can be answered by generating storage-restriction response figures as shown in the above figures, which allows an actor to examine the consequences of being varying levels of risk tolerance on their ability to fulfill demand while maintaining sufficient water levels. This ability can improve judgement on how much risk a utility can actually tolerate without adversely impacting the socioeconomic aspects of the systems dependent on a water supply utility. In addition, using ROFs enable a utility to better estimate when new infrastructure really needs to be built, instead of making premature investments as a result of unwarranted risk aversion.
To briefly summarize this blog post, we have shown how different risk tolerance levels affect the decisions made by an actor, and how these decisions in turn impact the system. Not shown here is the ability of an ROF to evolve over time given climate change and the building of new water supply infrastructure. In the next blog post, we will briefly discuss the role of ROFs in mapping out adaptation pathways for a utility, how ROFs form the basis of a dynamic and adaptive pathway and their associated operation policies, and connect this to the concept of the soft path (Gleick, 2002) in water supply management.
References
Gleick, P., 2002. Water management: Soft water paths. Nature, 418(6896), pp.373-373.
Herman, J., Zeff, H., Lamontagne, J., Reed, P. and Characklis, G., 2016. Synthetic Drought Scenario Generation to Support Bottom-Up Water Supply Vulnerability Assessments. Journal of Water Resources Planning and Management, 142(11), p.04016050.
Trindade, B., Reed, P., Herman, J., Zeff, H. and Characklis, G., 2017. Reducing regional drought vulnerabilities and multi-city robustness conflicts using many-objective optimization under deep uncertainty. Advances in Water Resources, 104, pp.195-209.
We recently covered an introduction to the concept of risk of failure (ROF), ROF triggers and ROF table generation. To provide a brief recap, an ROF is the probability that the system will fail to meet its performance objectives, whereas an ROF trigger is a measure of the amount of risk that a stakeholder is willing to take before initiating mitigating or preventive action. We also discussed the computational drawbacks of iteratively evaluating the ROF for each hydrologic scenario, and generated ROF tables as a way to circumvent those drawbacks.
In this post, we will explore the use of ROF metrics and triggers as levers to adjust for preferred levels of tradeoffs between two tradeoffs. Once again, we will revisit Cary, a city located in the Research Triangle region of North Carolina whose stakeholders would like to develop a robust water management policy.
To clarify, we will be generating ROF metrics while evaluating the performance objectives and will not be using the ROF tables generated in the previous blog post. Hence, as stated Bernardo’s blog post, we will begin generating ROF metrics using data from the weeks immediately prior to the current week. This is because performance metrics reflect current (instead of historical) hydrologic dynamics. To use ROF tables for performance metrics, a table update must be performed. This is a step that will possibly be explored in a future methodological blog post.
The test case
The city of Cary (shown in the image below) is supplied by the Jordan Lake. It has 50 years of historical streamflow and evaporation rate data, which can be found in the first 2600 columns of the data files found in the GitHub repository. In addition, these files contain 45 years of synthetically-generated projected streamflow and evaporation data obtained from Cary’s stakeholders. They also have 45 years of projected demand, and would like to use a combination of historical and synthetic streamflow and evaporation to explore how their risk tolerance will affect their water utility’s performance over 45 years.
Cary is located in the red box shown in the figure above (source: Trindade et. al., 2019).
Performance objectives
Two performance objectives have been identified as measures of Cary’s water utility’s performance:
Maximize reliability: Cary’s stakeholders would like to maximize the reliability of the city’s water supply. They have defined failure as at least one event in which the Jordan Lake reservoir levels drop below 20% of full capacity in a year. Reliability is calculated as the following:
Reliability = 1 – (Total number of failures over all realizations/Total number of realizations)
Minimize water use restrictions: Water use restrictions are triggered every time the ROF for a current week exceed the ROF trigger (or threshold) that has been set by Cary’s stakeholders. Since water use restrictions have negative political and social implications, the average number water use restrictions frequency per realization should be minimized and is calculated as follows:
Average water use restriction frequency = Total number of restrictions per realization per year / Total number of realizations
Visualizing tradeoffs
Here, we will begin with a moderate scenario in which the Jordan Lake reservoir is 40% full. We will examine the response of average reliability and restriction frequency over 1000 realizations for varying values of the ROF trigger.
Since the risk tolerance of a stakeholder will affect how often they choose to implement water use restrictions, this will, by extension, affect the volume of storage in the reservoir. Intuitively, a less risk-averse stakeholder would choose to prioritize supply reliability (i.e., consistent reservoir storage levels), resulting in them requiring more frequent water use restrictions. The converse is also true.
The code to generate this tradeoff plot can be found under tradeoff.py in the GitHub folder. This Python script contains the following helper functions:
check_failure: Checks if current storage levels are below 20% of full reservoir capacity.
rof_evaluation: Evaluates the weekly ROF metrics for current demands, streamflows, and evaporation rates.
restriction_check: Checks if the current weekly ROF exceeds the threshold set by the stakeholder.
storage_r: Calculates the storage based on the ROF metrics. If a restriction is triggered during, only 90% of total weekly demands are met for the the smaller of either the next 4 weeks (one month of water use restrictions) or the remaining days of the realization.
reliability_rf_check: Checks the reliability and the restriction frequency over all realizations for a given ROF trigger.
Send help – what is going on here?
Picture yourself as Cary. Knowing that you cannot take certain actions without adversely affecting the performance of your other system objectives, you would like an intuitive, straightforward way to ‘feel around’ for your risk tolerance. More traditionally, this would be done by exploring different combinations of your system’s decision variables (DVs) – desired reservoir storage levels, water use restriction frequency, etc – to search for a policy that is both optimal and robust. However, this requires multiple iterations of setting and tuning these DVs.
In contrast, the use of ROF metrics is more akin to a ‘set and forget’ method, in which your risk appetite is directly reflected in the dynamic between your performance objectives. Instead of searching for specific (ranges of) DV values that map to a desired policy, ROF metrics allow you to explore the objective tradeoffs by setting a threshold of acceptable risk. There are a couple of conveniences that this affords you.
Firstly, the number of DVs can be reduced. The examples of DVs given previously simply become system inputs, and ROF trigger values instead become your DVs, with each ROF trigger an reflection of the risk threshold that an objective should be able to tolerate. Consequently, this allows a closed-loop system to be approximated. Once an ROF trigger is activated, a particular action is taken, which affects the performance of the system future timesteps. These ‘affected’ system states then become the input to the next timestep, which will be used to evaluate the system performance and if an ROF trigger should be activated.
An example to clear the air
The closed-loop approximation of Cary’s water supply system.
In the Python code shown above, there is only one DV – the ROF trigger for water use restrictions. If the ROF for the current week exceeds this threshold, Cary implements water use restrictions for the next 30 days. This in turn will impact the reservoir storage levels, maintaining a higher volume of water in the Jordan Lake and improving future water supply reliability. More frequent water restrictions implies a higher reliability, and vice versa. Changing the ROF trigger value can be thought of as a dial that changes the degree of tradeoff between your performance objectives (Gold et. al., 2019). The figure on the right summarizes this process:
This process also allows ROF triggers to account for future uncertainty in the system inputs (storage levels, streamflow, demand growth rates and evaporation rates) using present and historical observations of the data. This is particularly useful when making decisions under deep uncertainty (Marchau et. al., 2019) where the uncertainty in the system inputs and internal variability can be difficult to characterize. Weekly ROFs dynamically change to reflect a posteriori system variations, enabling adaptivity and preventing the decision lock-in (Haasnoot et. al., 2013) characteristic of more a priori methods of decision-making.
Summary
Here we have shown how setting different ROF triggers can affect a system’s performance objective tradeoffs. In simpler terms, a stakeholder with a certain policy preference can set an ROF trigger value that results in their desired outcomes. Using ROF triggers also allows stakeholders the ease and flexibility to explore a range of risk tolerance levels through simulations, and discover vulnerabilities (and even opportunities) that they may have previously not been privy to.
Coming up next, we will cover how ROF triggers can be used to approximate a closed-loop system by examining the changing storage dynamics under a range of ROF trigger values. To do this, we will generate inflow and storage time series, and examine where water use restrictions were activated under different ROF trigger values. These figures will also be used to indicate the effect of ROF triggers on a utility’s drought response.
References
Gold, D. F., Reed, P. M., Trindade, B. C., & Characklis, G. W. (2019). Identifying actionable compromises: Navigating multi‐city robustness conflicts to discover cooperative safe operating spaces for regional water supply portfolios. Water Resources Research,55(11), 9024-9050. doi:10.1029/2019wr025462
Haasnoot, M., Kwakkel, J. H., Walker, W. E., & Ter Maat, J. (2013). Dynamic adaptive policy pathways: A method for crafting robust decisions for a deeply uncertain world. Global Environmental Change,23(2), 485-498. doi:10.1016/j.gloenvcha.2012.12.006
Marchau, V., Walker, W. E., M., B. P., & Popper, S. W. (2019). Decision making under deep uncertainty: From theory to practice. Cham, Switzerland: Springer.
Trindade, B., Reed, P., & Characklis, G. (2019). Deeply uncertain pathways: Integrated multi-city regional water supply infrastructure investment and portfolio management. Advances in Water Resources,134, 103442. doi:10.1016/j.advwatres.2019.103442
In this post, we will break down the key concepts underlying synthetic streamflow generation, and how it fits within the Many Objective Robust Decision Making (MORDM) framework (Kasprzyk, Nataraj et. al, 2012). This post is the first in a series on MORDM which will begin here: with generating and validating the data used in the framework. To provide some context as to what we are about to attempt, please refer to this post by Jon Herman.
What is synthetic streamflow generation?
Synthetic streamflow generation is a non-parametric, direct statistical approach used to generate synthetic streamflow timeseries from a reasonably long historical record. It is used when there is a need to diversify extreme event scenarios, such as flood and drought, or when we want to generate flows to reflect a shift in the hydrologic regime due to climate change. It is favored as it relies on a re-sampling of the historical record, preserving temporal correlation up to a certain degree, and results in a more realistic synthetic dataset. However, its dependence on a historical record also implies that this approach requires a relatively long historical inflow data. Jon Lamontagne’s post goes into further detail regarding this approach.
Why synthetic streamflow generation?
An important step in the MORDM framework is scenario discovery, which requires multiple realistic scenarios to predict future states of the world (Kasprzyk et. al., 2012). Depending solely on the historical dataset is insufficient; we need to generate multiple realizations of realistic synthetic scenarios to facilitate a comprehensive scenario discovery process. As an approach that uses a long historical record to generate synthetic data that has been found to preserve seasonal and annual correlation (Kirsch et. al., 2013; Herman et. al., 2016), this method provides us with a way to:
Fully utilize a large historical dataset
Stochastically generate multiple synthetic datasets while preserving temporal correlation
Explore many alternative climate scenarios by changing the mean and the spread of the synthetic datasets
The basics of synthetic streamflow generation in action
To better illustrate the inner workings of synthetic streamflow generation, it is helpful to use a test case. In this post, the historical dataset is obtained from the Research Triangle Region in North Carolina. The Research Triangle region consists of four main utilities: Raleigh, Durham, Cary and the Orange County Water and Sewer Authority (OWASA). These utilities are receive their water supplies from four water sources: the Little River Reservoir, Lake Wheeler, Lake Benson, and the Jordan Lake (Figure 1), and historical streamflow data is obtained from ten different stream gauges located at each of these water sources. For the purpose of this example, we will be using 81 years’ worth of weekly streamflow data available here.
Figure 1: The Research Triangle region (Trindade et. al., 2019).
The statistical approach that drive synthetic streamflow generation is called the Kirsch Method (Kirsch et. al., 2013). In plain language, this method does the following:
Converts the historical streamflows from real space to log space, and then standardize the log-space data.
Bootstrap the log-space historical matrix to obtain an uncorrelated matrix of historical data.
Obtain the correlation matrix of the historical dataset by performing Cholesky decomposition.
Impose the historical correlation matrix upon the uncorrelated matrix obtained in (2) to generate a standardized synthetic dataset. This preserves seasonal correlation.
De-standardize the synthetic data, and transform it back into real space.
Repeat steps (1) to (5) with a historical dataset that is shifted forward by 6 months (26 weeks). This preserves year-to-year correlation.
This post by Julie Quinn delves deeper into the Kirsch Method’s theoretical steps. The function that executes these steps can be found in the stress_dynamic.m Matlab file, which in turn is executed by the wsc_main_rate.m file by setting the input variable p = 0 as shown on Line 27. Both these files are available on GitHub here.
However, this is simply where things get interesting. Prior to this, steps (1) to (6) would have simply generated a synthetic dataset based on only historical statistical characteristics as validated here in Julie’s second blog post on a similar topic. Out of the three motivations for using synthetic streamflow generation, the third one (exploration of multiple scenarios) has yet to be satisfied. This is a nice segue into out next topic:
Generating multiple scenarios using synthetic streamflow generation
The true power of synthetic streamflow generation lies in its ability to generate multiple climate (or in this case, streamflow) scenarios. This is done in stress_dynamic.m using three variables:
Input variable
Data type
p
The lowest x% of streamflows
n
A vector where each element ni is the number of copies of the p-lowest streamflow years to be added to the bootstrapped historical dataset.
m
A vector where each element mi is the number of copies of the (1-p)-highest streamflow years to be added to the bootstrapped historical dataset.
Table 1: The input variables to the stress_dynamic function.
These three variables bootstrap (increase the length of) the historical record while allow us to perturb the historical streamflow record streamflows to reflect an increase in frequency or severity of extreme events such as floods and droughts using the following equation:
The stress_dynamic.m file contains more explanation regarding this step.
This begs the question: how do we choose the value of p? This brings us to the topic of the standardized streamflow indicator (SSI6).
The SSI6 is the 6-month moving average of the standardized streamflows to determine the occurrence and severity of drought on the basis of duration and frequency (Herman et. al., 2016). Put simply, this method determines the occurrence of drought if the the value of the SSI6 < 0 continuously for at least 3 months, and SSI6 < -1 at least once during the 6-month interval. The periods and severity (or lack thereof) of drought can then be observed, enabling the decision on the length of both the n and m vectors (which correspond to the number of perturbation periods, or climate event periods). We will not go into further detail regarding this method, but there are two important points to be made:
The SSI6 enables the determination of the frequency (likelihood) and severity of drought events in synthetic streamflow generation through the values contained in p, n and m.
This approach can be used to generate flood events by exchanging the values between the n and m vectors.
A good example of point (2) is done in this test case, in which more-frequent and more-severe floods was simulated by ensuring that most of the values in m where larger than those of n. Please refer to Jon Herman’s 2016 paper titled ‘Synthetic drought scenario generation to support bottom-up water supply vulnerability assessments’ for further detail.
A brief conceptual letup
Now we have shown how synthetic streamflow generation satisfies all three factors motivating its use. We should have three output folders:
synthetic-data-stat: contains the synthetic streamflows based on the unperturbed historical dataset
synthetic-data-dyn: contains the synthetic streamflows based on the perturbed historical dataset
Comparing these two datasets, we can compare how increasing the likelihood and severity of floods has affected the resulting synthetic data.
Validation
To exhaustively compare the statistical characteristics of the synthetic streamflow data, we will perform two forms of validation: visual and statistical. This method of validation is based on Julie’s post here.
Visual validation
Done by generating flow duration curves (FDCs) . Figure 2 below compares the unperturbed (left) and perturbed (right) synthetic datasets.
Figure 2: (Above) The FDC of the unperturbed historical dataset (pink) and its resulting synthetic dataset (blue). (Below) The corresponsing perturbed historical and synthetic dataset.
The bottom plots in Figure 2 shows an increase in the volume of weekly flows, as well as an smaller return period, when the the historical streamflows were perturbed to reflect an increasing frequency and magnitude of flood events. Together with the upper plots in Figure 2, this visually demonstrates that the synthetic streamflow generation approach (1) faithfully reconstructs historical streamflow patterns, (2) increases the range of possible streamflow scenarios and (3) can model multiple extreme climate event scenarios by perturbing the historical dataset. The file to generate this Figure can be found in the plotFDCrange.py file.
Statistical validation
The mean and standard deviation of the perturbed and unperturbed historical datasets are compared to show if the perturbation resulted in significant changes in the synthetic datasets. Ideally, the perturbed synthetic data would have higher means and similar standard deviations compared to the unperturbed synthetic data.
Figure 3: (Above) The unperturbed synthetic (blue) and historical (pink) streamflow datasets for each of the 10 gauges. (Below) The perturbed counterpart.
The mean and tails of the synthetic streamflow values of the bottom plots in Figure 3 show that the mean and maximum values of the synthetic flows are significantly higher than the unperturbed values. In addition, the spread of the standard deviations of the perturbed synthetic streamflows are similar to that of its unperturbed counterpart. This proves that synthetic streamflow generation can be used to synthetically change the occurrence and magnitude of extreme events while maintaining the periodicity and spread of the data. The file to generate Figure 3 can be found in weekly-moments.py.
Synthetic streamflow generation and internal variability
The generation of multiple unperturbed realizations of synthetic streamflow is vital for characterizing the internal variability of a system., otherwise known as variability that arises from natural variations in the system (Lehner et. al., 2020). As internal variability is intrinsic to the system, its effects cannot be eliminated – but it can be moderated. By evaluating multiple realizations, we can determine the number of realizations at which the internal variability (quantified here by standard deviation as a function of the number of realizations) stabilizes. Using the synthetic streamflow data for the Jordan Lake, it is shown that more than 100 realizations are required for the standard deviation of the 25% highest streamflows across all years to stabilize (Figure 4). Knowing this, we can generate sufficient synthetic realizations to render the effects of internal variability insignificant.
Figure 4: The highest 25% of synthetic streamflows for the Jordan Lake gauge.
How does this all fit within the context of MORDM?
So far, we have generated synthetic streamflow datasets and validated them. But how are these datasets used in the context of MORDM?
Synthetic streamflow generation lies within the domain of the second part of the MORDM framework as shown in Figure 5 above. Specifically, synthetic streamflow generation plays an important role in the design of experiments by preserving the effects of deeply uncertain factors that cause natural events. As MORDM requires multiple scenarios to reliably evaluate all possible futures, this approach enables the simulation of multiple scenarios, while concurrently increasing the severity or frequency of extreme events in increments set by the user. This will allow us to evaluate how coupled human-natural systems change over time given different scenarios, and their consequences towards the robustness of the system being evaluated (in this case, the Research Triangle).
Figure 4: The taxonomy of robustness frameworks. The bold-outlined segments highlight where MORDM fits within this taxonomy (Herman et. al., 2015).
Typically, this evaluation is performed in two main steps:
Generation and evaluation of multiple realizations of unperturbed annual synthetic streamflow. The resulting synthetic data is used to generate the Pareto optimal set of policies. This step can help us understand how the system’s internal variability affects future decision-making by comparing it with the results in step (2).
Generation and evaluation of multiple realizations of perturbed annual synthetic streamflow. These are the more extreme scenarios in which the previously-found Pareto-optimal policies will be evaluated against. This step assesses the robustness of the base state under deeply uncertain deviations caused by the perturbations in the synthetic data and other deeply uncertain factors.
Conclusion
Overall, synthetic streamflow generation is an approach that is highly applicable in the bottom-up analysis of a system. It preserves historical characteristics of a streamflow timeseries while providing the flexibility to modify the severity and frequency of extreme events in the face of climate change. It also allows the generation of multiple realizations, aiding in the characterization and understanding of a system’s internal variability, and a more exhaustive scenario discovery process.
This summarizes the basics of data generation for MORDM. In my next blog post, I will introduce risk-of-failure (ROF) triggers, their background, key concepts, and how they are applied within the MORDM framework.
References
Herman, J. D., Reed, P. M., Zeff, H. B., & Characklis, G. W. (2015). How should robustness be defined for water systems planning under change? Journal of Water Resources Planning and Management,141(10), 04015012. doi:10.1061/(asce)wr.1943-5452.0000509
Herman, J. D., Zeff, H. B., Lamontagne, J. R., Reed, P. M., & Characklis, G. W. (2016). Synthetic drought scenario generation to support bottom-up water supply vulnerability assessments. Journal of Water Resources Planning and Management,142(11), 04016050. doi:10.1061/(asce)wr.1943-5452.0000701
Kasprzyk, J. R., Nataraj, S., Reed, P. M., & Lempert, R. J. (2013). Many objective robust decision making for complex environmental systems undergoing change. Environmental Modelling & Software,42, 55-71. doi:10.1016/j.envsoft.2012.12.007
Kirsch, B. R., Characklis, G. W., & Zeff, H. B. (2013). Evaluating the impact of alternative hydro-climate scenarios on transfer agreements: Practical improvement for generating synthetic streamflows. Journal of Water Resources Planning and Management,139(4), 396-406. doi:10.1061/(asce)wr.1943-5452.0000287
Mankin, J. S., Lehner, F., Coats, S., & McKinnon, K. A. (2020). The value of initial condition large ensembles to Robust Adaptation Decision‐Making. Earth’s Future,8(10). doi:10.1029/2020ef001610
Trindade, B., Reed, P., Herman, J., Zeff, H., & Characklis, G. (2017). Reducing regional drought vulnerabilities and multi-city robustness conflicts using many-objective optimization under deep uncertainty. Advances in Water Resources,104, 195-209. doi:10.1016/j.advwatres.2017.03.023

and
: The prey and predator population densities at time
respectively
: The rate at which the predator encounters the prey
: The prey growth rate
: The rate at which the predator converts prey to new predators
: The predator death rate
: The time the predator needs to consume the prey (handling time)
: Environmental carrying capacity
: The level of predator interaction
: The fraction of prey that is harvested


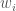

![i \in [1,2]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5B1%2C2%5D&bg=ffffff&fg=444444&s=0&c=20201002)






1,500
0.5









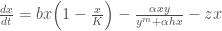

 is the prey population being harvested and
is the prey population being harvested and  is the predator population. Please refer to
is the predator population. Please refer to 
 , rather than specific parameter values,
, rather than specific parameter values, ![z = [z_1, z_2, ..., z_t]](https://s0.wp.com/latex.php?latex=z+%3D+%5Bz_1%2C+z_2%2C+...%2C+z_t%5D&bg=ffffff&fg=444444&s=0&c=20201002) . The process of optimizing the parameters of a state-aware control rule is known as Direct Policy Search (DPS; Quinn et al, 2017).
. The process of optimizing the parameters of a state-aware control rule is known as Direct Policy Search (DPS; Quinn et al, 2017).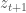 , is mapped to the current prey population levels,
, is mapped to the current prey population levels,  by the function:
by the function:![z_{t+1} = \sum_{i=1}^n w_i \Big[exp\Big[-\Big(\frac{x_t-c_i}{b_i}\Big)^2\Big]\Big]](https://s0.wp.com/latex.php?latex=z_%7Bt%2B1%7D+%3D+%5Csum_%7Bi%3D1%7D%5En+w_i+%5CBig%5Bexp%5CBig%5B-%5CBig%28%5Cfrac%7Bx_t-c_i%7D%7Bb_i%7D%5CBig%29%5E2%5CBig%5D%5CBig%5D&bg=ffffff&fg=444444&s=0&c=20201002)
 and
and  are the center, radius, and weights of each RBF
are the center, radius, and weights of each RBF  is the number of RBFs used in the function; in this study we use
is the number of RBFs used in the function; in this study we use 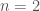 RBFs. With two RBFs, there are a total of 6 parameters. Increasing the number of RBFs allows for more flexible function forms to be achieved. However, two RBFs have been shown to be sufficient for this problem.
RBFs. With two RBFs, there are a total of 6 parameters. Increasing the number of RBFs allows for more flexible function forms to be achieved. However, two RBFs have been shown to be sufficient for this problem.
![[c_1, b_1, w_1, c_2, b_2, w_2]](https://s0.wp.com/latex.php?latex=%5Bc_1%2C+b_1%2C+w_1%2C+c_2%2C+b_2%2C+w_2%5D&bg=ffffff&fg=444444&s=0&c=20201002) ), and the current prey population, to calculate the next year’s harvesting effort.
), and the current prey population, to calculate the next year’s harvesting effort. .
.![[c_1, b_1, w_1, c_2, b_2, w_2] = [0.2, 1.1, 0.41, 0.34,0.7, 0.59]](https://s0.wp.com/latex.php?latex=%5Bc_1%2C+b_1%2C+w_1%2C+c_2%2C+b_2%2C+w_2%5D+%3D+%5B0.2%2C+1.1%2C+0.41%2C+0.34%2C0.7%2C+0.59%5D+&bg=ffffff&fg=444444&s=0&c=20201002)

![c_i, b_i, w_i \in [0,1]](https://s0.wp.com/latex.php?latex=c_i%2C+b_i%2C+w_i+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=444444&s=0&c=20201002) . Below is a plot of the resulting random policy functions:
. Below is a plot of the resulting random policy functions: times, and take the average objective score over the range of simulations. This method helps to account for variability in expected outcomes due to natural stochasticity. Here, we use
times, and take the average objective score over the range of simulations. This method helps to account for variability in expected outcomes due to natural stochasticity. Here, we use  realizations of stochasticity.
realizations of stochasticity. ) is calculated as:
) is calculated as:
 is the discount rate which converts future benefits to present economic value, here
is the discount rate which converts future benefits to present economic value, here  .
.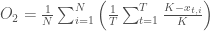


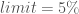 .
.