
Introduction
Rhodium is a python library built to facilitate the Many Objective Robust Decision Making (MORM) framework. The MORDM framework couples many objective search with robust decision making (RDM) to facilitate decision support for complex, many-objective problems under deep uncertainty (Kasprzyk et al., 2013). A core component of MORDM is the quantification of robustness, which can be defined as “the insensitivity of system design to errors, random or otherwise, in the estimates of those parameters effecting design choice” (Matalas and Fiering, 1977; quote via Herman et al., 2015). While robustness as a concept may sound straightforward, quantifying robustness in mathematical terms is more challenging. As we’ll see later in this post, our choice on how to quantify robustness may have large implications on the decision making process. In this post I’ll demonstrate how to use Rhodium to examine the implications of the choice of robustness measure on the shallow lake problem from environmental systems literature. I’ll first walk through problem formulation and multi-objective optimization steps of MORDM, then implement four robustness metrics presented in Herman et al., (2015) on a set of candidate solutions.
Problem Formulation
The classical shallow lake problem (Carptenter et al,. 1999) presents a hypothetical town that seeks to balance economic benefits of phosphorus (P) emissions with the ecological benefits of a healthy lake. The lake naturally receives inflows of phosphorus from the surrounding area and recycles phosphorus in its system. Under natural conditions, the lake’s phosphorus levels will always return to a healthy (oligotrophic) equilibrium. However, if emissions from the town are too high, the lake will cross an irreversible tipping point into an unhealthy (eutrophic) state. The town seeks to find a policy to regulate phosphorus that will keep its economy prosperous while preserving a healthy ecosystem.
System Model
To facilitate the decision making process, decision makers employ a dimensionless model to abstract phosphorus dynamics in the lake:

Where X is the normalized concentration of P in the lake, a represents the anthropogenic phosphorus inputs from the town, Y ~ LN(mu, sigma) are natural P inputs to the lake, q is a parameter controlling the recycling rate of P from sediment, b is a parameter controlling the rate at which P is removed from the system and t is the time index in years. For details on the lake problem model, see Quinn et al., (2017).
Uncertainties
Decision makers have estimates of model parameters that govern the flux of phosphorus, however, these parameters are uncertain and their probability distributions are unknown, therefore they are treated as deep uncertainties. The assumed values and plausible ranges of these uncertainties are shown in the table below.
| Uncertainty | Base Value | Lower bound | Upper Bound |
| b | 0.42 | 0.1 | 0.45 |
| q | 2.0 | 2.0 | 4.5 |
| delta | 0.98 | 0.93 | 0.99 |
| mu | 0.03 | 0.01 | 0.05 |
| sigma | (10^-5)^.5 | 0.001 | 0.005 |
Objectives
Local stakeholders have identified four objectives they would like to optimize:
- Maximize the average economic benefit of phosphorus emissions
- Minimize the worst case average phosphorus concentration in the lake
- Maximize the inertia of the phosphorus control policy (ie. do not create a policy with large year to year swings in phosphorus emissions)
- Maximize the reliability of a policy staying below the lake’s critical phosphorus threshold
For details on the objective formulations, refer to Quinn et al., (2017).
Decisions
Following Quinn et al., (2017), phosphorus emissions are controlled by a state dependent rule system which uses cubic radial basis functions to determine annual phosphorus emissions based on the phosphorus in the lake.
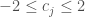




Where 
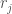
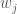
Building the model in Rhodium
Conducting MORDM on your own can be an onerous process, often your model is written in a different language than you post-processing software and each individual script requires data in a different format. Rhodium can make the MORDM process much easier. It has custom built data structures which are tailored for MORDM analysis and a declarative structure which makes plugging in an external model simple. For this demonstration I’ll use a python implementation of the Lake problem which I’ve copied to this Git repository (to save space I’m omitting it from the text of this post). The first step in conducting MORDM with Rhodium is to declare a Rhodium model. This file must be in the same repository as the python file running rhodium, I’ll also need the file RBFpolicy.py, found here.
model = Model(LakeProblemDPS)
To properly declare the model I need to specify model parameters, levers, uncertainties and model responses. Model parameters include any input that will change across model evaluations. I also need to let Rhodium know which parameters are decision variables or “levers” and which are uncertainties. I can do this by explicitly declaring levers, uncertainties and their ranges as shown below.
model.parameters = [Parameter("vars"),
Parameter("b"),
Parameter("q"),
Parameter("mu"),
Parameter("sigma"),
Parameter("delta")]
model.levers = [RealLever("vars", 0.0, 1, length=6)]
model.uncertainties = [UniformUncertainty("b", 0.1, 0.45),
UniformUncertainty("q", 2.0, 4.5),
UniformUncertainty("mu", 0.01, 0.05),
UniformUncertainty("sigma", 0.001, 0.005),
UniformUncertainty("delta", 0.93, 0.99)]
Next, I need to specify model responses. Model responses include any optimization objective and any information needed to assess constraints or other information. When specifying output I also need to tell Rhodium what kind of response each variable represents (ie minimize or maximize etc.).
model.responses = [Response("net_benefits", Response.MAXIMIZE),
Response("max_P", Response.MINIMIZE),
Response("intertia", Response.MAXIMIZE),
Response("reliability", Response.MAXIMIZE)]
Many Objective Search
Now that I’ve defined our model, I’m ready to perform search with an MOEA. In this example I’ll use NSGAII and search over 10,000 function evaluations. This optimization takes a long time when running in serial, so I’ll exploit Rhodium’s parallelization capabilities to utilize 4 core on my desktop computer.
# Use a Process Pool evaluator, which will work on Python 3+
if __name__ == "__main__":
with ProcessPoolEvaluator(4) as evaluator:
RhodiumConfig.default_evaluator = evaluator
paretoSet = optimize(model, "NSGAII", 10000)
The variable paretoSet, is an instantiation of Rhodium’s DataSet class which now contains the Pareto approximate set found by NSGAII. We can visualize the approximate Pareto set using Rhodium’s built in visualization tools. Here I’ll use a Parallel Coordinate plot. Following Quinn et al., 2017, I’ll assume the stakeholders have set performance criteria of Reliability > 0.95 and Net Benefits > 0.2. Using Rhodium’s brushing functionality we can examine which solutions in our Pareto approximate set meet these criteria.
parallel_coordinates(model, paretoSet, target="top",
brush=[Brush("reliability > 0.95 and net_benefits > 0.2"), Brush("reliability <= 0.95 or net_benefits <= 0.2")])

Below, I’ve defined a function to evaluate a solution’s satisficing criteria. We can extract solutions that meet the criteria using the DataSet class’s find function.
criteria = lambda x : x["reliability"] > 0.95 and x["net_benefits"] > 0.2
acceptableSols = paretoSet.find(criteria)
DU Reevaluation
The solutions defined above meet stakeholder criteria if our assumptions about the state of the world (SOW) are correct, but what if the future deviates from our assumptions? To answer this question, I’ll create 1,000 new SOWs using latin hypercube sampling of our model uncertainties. I’ll then use Rhodium to reevaluate the set of acceptable solutions under each SOW (from here out I will refer to this as DU reevaluation). Rhodium has built in tools for both sampling uncertainties and reevaluating a set of solutions.
SOWs = sample_lhs(model, 1000)
reevaluation = [evaluate(model, update(SOWs, policy)) for policy in acceptableSols]
Measuring Robustness
For this exercise, I’ll examine four robustness measures reviewed in Herman et al., (2015). The four metrics include two variants of regret and two variants of satisficing, categories of robustness measures originally defined by Lempert and Collins, (2007). I’ll first show how each measure is calculated and how it can be coded in Rhodium, then I’ll illustrate how and why the choice of robustness metric changes the decision making process. All python implementations of robustness metrics in this post are adaptations of original functions written by Dave Hadka in the Rhodium source code.
Regret Type 1
The first metric, regret type 1 (R1), measures a solution’s deviation from its performance in the baseline SOW. Examples of this metric’s use can be found in Kasprzyk et al., (2013) and Lempert and Collins, (2007). As defined by Herman et al., (2015), R1 measures robustness as the 90th percentile deviation in objective performance across SOWs, maximized across all objectives. The 90th percentile is used to capture tail performance while reducing susceptibility to outliers.
![R1 = \max_i[D_{i,90}:P(D_i\leq D_{i,90}=0.90]](https://s0.wp.com/latex.php?latex=R1+%3D+%5Cmax_i%5BD_%7Bi%2C90%7D%3AP%28D_i%5Cleq+D_%7Bi%2C90%7D%3D0.90%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Where:
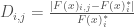
Where 
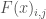
Below I’ve coded a function which utilizes Rhodium’s built in data structures to calculate R1 for a given solution. The variable results is a Rhodium DataSet object containing the full set of DU reevaluations for one member of the Pareto approximate set. baseline is a DataSet containing the solution’s performance in the baseline state of the world.
def regret_type1(model, results, baseline, percentile=90):
quantiles = []
for response in model.responses:
if response.dir == Response.MINIMIZE or response.dir == Response.MAXIMIZE:
values = [abs((result[response.name] - baseline[response.name]) / baseline[response.name]) for result in results]
quantiles.append(np.percentile(values, percentile))
return max(quantiles)
Regret Type 2
Regret Type 2 (R2), is a variant of Savage regret introduced by Savage, 1951. R2 measures a decision maker’s regret for choosing a given solution over other available solutions by comparing the chosen solution’s performance in each SOW against the best performing option for that SOW. Like R1, R2 utilizes the 90th percentile deviation to capture tail behavior while reducing susceptibility to outliers:
![R2 = \max_i[D_{i,90}:P(D_i\leq D_{i,90}=0.90]](https://s0.wp.com/latex.php?latex=R2+%3D+%5Cmax_i%5BD_%7Bi%2C90%7D%3AP%28D_i%5Cleq+D_%7Bi%2C90%7D%3D0.90%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Where:
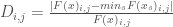
if objective i is to be minimized and

if objective i is to be maximized.
The best value of each objective i is taken across the set of all solutions s. The deviation in R2 is normalized by the objective value itself rather than the best value, since this objective often approaches zero for minimization problems.
The function below again utilizes Rhodium’s data structures to efficiently implement a function for R2 in python. all_results is a list of DataSet objects, each containing the full set of DU reevaluations for one member of the Pareto approximate set. results is a DataSet containing the full set of DU reevaluations for the member of the Pareto approximate set being evaluated by this function.
def regret_type2(model, all_results, results, percentile=90):
# for each uncertainty sampling, find the best value
best = []
for i in range(len(all_results[0])):
entry = {}
for response in model.responses:
if response.dir == Response.MINIMIZE:
entry[response.name] = min([result[response.name] for result in all_results])
elif response.dir == Response.MAXIMIZE:
entry[response.name] = max([result[response.name] for result in all_results])
best.append(entry)
# then compute the regret from the best value
quantiles = []
for response in model.responses:
if response.dir == Response.MINIMIZE or response.dir == Response.MAXIMIZE:
values = []
for i in range(len(all_results[0])):
values.append(abs((results[i][response.name] - best[i][response.name]) / results[i][response.name]))
quantiles.append(np.percentile(values, percentile))
return max(quantiles)
Satisficing Type 1
Satisficing metrics quantify a solution’s ability to meet prespecified performance criteria across deeply uncertain SOWs. Satisficing type 1, an approximation of Starr’s domain criterion (Starr 1962; Schneller and Sphicas, 1983) , represents the fraction of states of the world that a solution meets a set of performance criteria.

Where N is the number of sampled SOWs and 
In python, we can express the performance criteria in a lambda function, as shown in the criteria function defined above. The function below calculates S1 for a solution whose DU reevaluation results have been stored in a DataSet objected called results.
def satisficing_type1(model, results, expr=None):
# if no criteria are defined, check the feasibility across SOWs
if expr is None:
return mean(check_feasibility(model, results))
# otherwise, return the number of SOWs that meet the specified criteria
else:
satisfactory = [expr(result) for result in results]
return sum(satisfactory)/len(results)
Satisficing Type 2
Satisficing type 2 (S2) is a measure of robustness derived from Info-Gap literature (Ben-Haim, 2004). S2 represents the uncertainty horizon that can be withstood before a solution fails to meet a set of performance criteria.
![S2 = \hat{\alpha} = max \big[\alpha:min_{j \in U(\alpha)} F(x)_j \geq r^* \big]](https://s0.wp.com/latex.php?latex=S2+%3D+%5Chat%7B%5Calpha%7D+%3D+max+%5Cbig%5B%5Calpha%3Amin_%7Bj+%5Cin+U%28%5Calpha%29%7D+F%28x%29_j+%5Cgeq+r%5E%2A+%5Cbig%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Where 
def satisficing_type2(model, results, baseline, uncertainties_max, uncertainties_min, expr=None):
distances = []
# ensure all default parameters are defined in baseline
baseline = baseline.copy()
populate_defaults(model, baseline)
normalized_baseline = [baseline[u.name] for u in model.uncertainties]
normalized_baseline = (np.array(uncertainties_max)-np.array(normalized_baseline))/(np.array(uncertainties_max)-np.array(uncertainties_min))
for i, result in enumerate(results):
if (expr is None and _is_feasible(model, result)) or (expr is not None and expr(result)==False):
normalized_point = (np.array(uncertainties_max)- np.array([result[u.name] for u in model.uncertainties]))/(np.array(uncertainties_max)-np.array(uncertainties_min))
distances.append(sp.distance.euclidean(
normalized_point,
normalized_baseline))
return 0.0 if len(distances) == 0 else min(distances)
Examining the results

Figure 2: The top ranked solution according to each robustness measure along with each solution’s corresponding ranking across all other measures. Crossing lines indicate contrasting ordinal rankings of solution robustness between two measures. The preferablility of a solution is highly dependent on the choice of robustness metric.
Figure 2 shows the top ranked solution according to each robustness measure along with its corresponding rank across the other three measures. The four measures each provide different rankings of solution robustness. The top ranked solutions for the two regret based measures both preform poorly when evaluated under any of the other three measures, while the best solution according to S1 is tied for the best solution in S2 and ranks in the middle according to the two regret based solution. The second solution selected by S2 ranks at the bottom according to the other three metrics.
The disparity in ranking underscores the differences between the robustness measures. The wide difference in ranking between S2’s best solution and it’s ranking by the other three metrics indicates that while the uncertainties can deviate “far” from the base SOW before this solution fails, its performance is likely to be quite poor once this horizon is crossed. It’s poor ranking in S1 indicates that it will likely fail in many SOWs and it’s R1 ranking suggests that failures in the tail its performance are likely to be quite severe. Finally it’s low ranking in R2 means that there are other solutions that perform better across SOWs.
A solution that performs well by measure S2 may be preferable if decision makers have confidence that their assumptions about the base SOW are correct, however, this is rarely the case in conditions of deep uncertainty, so the solution recommended by S2 alone is likely undesirable. Furthermore, while S2 provides an aggregated measure of “distance to failure” this measure does not indicate which uncertainties drive failure or how far each individual uncertainty must deviate from the base SOW before the solution fails. A better way to understand a solution’s sensitivity to deeply uncertainties is through scenario discovery, which seeks to define vulnerable regions of the uncertainty space for a given solution. Rhodium has a set of built in scenario discovery tools, for details see this post by Julie.
The difference in robustness ranking between measures R1, R2 and S1 leave the decision makers with a choice regarding how they would like a solution to perform. Solutions that perform well in S1 maintain performance across the widest range of potential SOWs, but the metric provides no information on the severity of failure when the criteria is not met. Solutions that perform well in R1 are likely to have the least severe failures in the tails of their performance, but the metric does not measure the fraction of states of the world that result in poor performance. Measure R2 yields information about a solution’s performance relative to other options, but does not provide information about performance criteria or failure severity. As is often the case in decision making problems, the choice of measure should reflect a decision maker’s particular risk tolerance and preferences and must be tailored to each problem individually.
Final thoughts
This example has demonstrated how to use Rhodium to perform the first two steps of MORDM on a four objective formulation of the shallow lake problem. The results indicate that the choice of robustness metric changes which solutions are favored by decision makers. While I’ll wrap up this post here, this should not be the end of an MORDM analysis. After using the robustness metrics to select candidate policies, decision makers should perform scenario discovery to examine which uncertainties control solution performance and how these vulnerabilities differ between candidate solutions. Next, they should visualize each candidate policy to understand how it responds to various system states. Finally, they should think about whether these results necessitate any changes to the original problem formulation. If they choose to reformulate the problem, then the whole process starts back at the beginning. Luckily, Rhodium makes this process easy, allowing decision makers to examine problem formulations quickly and easily.
References
Ben-Haim, Y. (2004). “Uncertainty, probability and information-gaps.” Reliab. Eng. Syst. Saf., 85(1), 249–266.
Carpenter, S.R., Ludwig, D., Brock, W.A., 1999. Management of eutrophication for lakes subject to potentially irreversible change. Ecol. Appl. 9, 751e771.
Groves, D. G., and Lempert, R. J. (2007). “A new analytic method for finding policy-relevant scenarios.” Global Environ. Change, 17(1), 73–85.
Hall, J. W., Lempert, R. J., Keller, K., Hackbarth, A., Mijere, C., and
McInerney, D. J. (2012). “Robust climate policies under uncertainty:
A comparison of robust decision making and info-gap methods.”
Risk Anal., 32(10), 1657–1672
Herman, J.D., Reed, P.M., Zeff, H.B., Characklis, G.W., 2015. How should robustness be defined for water systems planning under change? J. Water Resour. Plan. Manag. 141, 04015012.
Kasprzyk, J. R., Nataraj, S., Reed, P. M., and Lempert, R. J. (2013). “Many objective robust decision making for complex environmental systems
undergoing change.” Environ. Modell. Softw., 42, 55–71.
Lempert, R. J., and Collins, M. (2007). “Managing the risk of an uncertain
threshold response: Comparison of robust, optimimum, and precaution-
ary approaches.” Risk Anal., 27(4), 1009–1026.
Matalas, N. C., and Fiering, M. B. (1977). “Water-resource systems
planning.” Climate, climatic change, and water supply, studies in geo-
physics, National Academy of Sciences, Washington, DC, 99–110.
Quinn, J. D., Reed, P. M., & Keller, K. (2017). Direct policy search for robust multi-objective management of deeply uncertain socio-ecological tipping points. Environmental Modelling & Software, 92, 125-141.
Savage, L. J. (1951). “The theory of statistical decision.” J. Am. Stat. Assoc., 46(253), 55–67.
Schneller, G., and Sphicas, G. (1983). “Decision making under uncertainty: Starr’s domain criterion.” Theory Decis., 15(4), 321–336.
Starr, M. K. (1962). Product design and decision theory, Prentice-Hall, Englewood Cliffs, NJ.

Pingback: MORDM using Rhodium – the lake problem workflow – Water Programming: A Collaborative Research Blog
Pingback: Writing sharable Python code part II: Unit Testing – Water Programming: A Collaborative Research Blog