
In the fourth installment of our intro to machine learning series, I’ll introduce Support Vector Machines, a powerful tool for classification and regression. In my last post on Perceptron, we examined a procedure for finding a hyperplane that is an effective linear classifier and not subject to the curse of dimensionality. To review, our task during binary classification is to find a classifier that can predict the label of a data point using a vector of the point’s characteristic features. The Perceptron algorithm finds a hyperplane that is able to separate points of different classifications within the feature space. An example of a linear classifier found using perceptron for a data set with 3 features is shown in Figure 1 below.

Figure 1: A hyperplane for binary classification of a linearly separable data set
While Perceptron is a useful conceptual tool for understanding classification problems, it suffers from several flaws that limit its usefulness in most classification problems. First, Perceptron will never converge if the data is not linearly separable, limiting its utility to well-behaved data sets. Second, while Perceptron is guaranteed to converge to a separating hyperplane if the data is linearly separable, such a hyperplane may take infinitely many possible forms and there is no guarantee that Perceptron will find the “best” one (more on what “best” means later). Support Vector Machines (SVM) overcome these problems to find an “optimal” hyperplane that may be fit to data sets that are not linearly separable. SVMs may also be kernalized to fit non-linear decision boundaries and extended to regression contexts. In this post we’ll look into how and why SVMs work and discuss an example of SVMs in water resources systems literature. I would like to note that the main body of content in this post was derived from course notes of CS 4780 by Dr. Kilian Weinberger at Cornell. For deeper coverage of machine learning content, check out the course page here.
The Maximum Margin Hyperplane
Let’s define the features of point i as xi, and its label as yi. If the data is linearly separable, Perceptron will find a hyperplane, H, such that:

Where w is an orthogonal vector that defines the orientation of hyperplane H, and b represents and offset from the origin.
While a hyperplane found by Perceptron will accurately separate the two classes, it likely will not find the hyperplane that does the “best” job bisecting the classes. So how do we define what makes a good hyperplane for classification? In machine learning we train classifiers on a set of training data hoping that the classifiers will generalize to a broader set of data; we seek classifiers that not only have low training error, but will also have low generalization error. It turns out the best way to reduce generalization error is to find the hyperplane that is most in the “middle” of the two classes in the training set. We can define the middle of the two data sets as the hyperplane that has the largest margin, or distance between the closest points in the two classes. This is known as the maximum margin hyperplane. The advantages of using the maximum margin hyperplane are easy to visualize. Figure 2 shows three hyperplanes attempting to classify a set of binary test data with two features, x1 and x2. Plane H1 does not separate the two data sets. Planes H2 and H3 are both able to correctly classify the data set, but plane H3, the maximum margin classifier, is the more natural partition. The two closest training points to the hyperplane H3, which define the maximum margin, are known as “support vectors”.

Figure 2: Three hyperplanes, plane H1 does not separate the two data sets, plane H2 separates the two but with a small margin, H3 is the maximum margin hyperplane (Image source: Wikimedia commons under the creative commons license)
SVM changes the classification problem from “find a hyperplane that correctly classifies all training points” to “find a the maximum margin hyperplane”, which allows us to formulate the problem as an optimization. Here, will denote the margin of a hyperplane as γ, which is a function of the hyperplane’s weight vector w and intercept b. The optimization is thus:
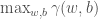

With a little math (if you’re interested, see these notes), we can simplify this problem to a quadratic optimization problem that can be efficiently solved with a Quadratically Constrained Quadratic Program (QCQP) solver.

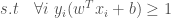
Soft Margin SVM
By finding the maximum margin classifier, SVM is guaranteed to find the optimal hyperplane for the given data and can do so using an out of the box QCQP solver. However, thus far, our treatment of SVM (known as “hard margin SVM”) will only work for linearly separable data. SVM can be extended to training sets that are not linearly separable by incorporating the optimization’s constraint as a penalty into the objective function:
![\min_{w,b} \quad w^Tw+C\sum^{n}_{i=1}max[1-y_{i}(w^Tx+b),0]](https://s0.wp.com/latex.php?latex=%5Cmin_%7Bw%2Cb%7D+%5Cquad+w%5ETw%2BC%5Csum%5E%7Bn%7D_%7Bi%3D1%7Dmax%5B1-y_%7Bi%7D%28w%5ETx%2Bb%29%2C0%5D&bg=ffffff&fg=444444&s=0&c=20201002)
Where C represents a penalty coefficient that can be set by the user. This formulation is known as “soft margin SVM”. Instead of only finding hyperplanes that perfectly divide the data, soft margin SVM allows misclassification at a penalty. When C is very large, soft margin SVM will find the same hyperplane as hard margin SVM. For more info on the derivation of soft margin SVM, see these notes.
An example of SVM in Water Resources Literature
So SVM is a linear classifier that finds the maximum margin hyperplane and can be applied to data that is not linearly separable, but how might one apply it in water resources systems? One example of SVM in water resources literature is by Herman et al., 2016, who use SVM for scenario discovery. Scenario discovery (Groves and Lempert, 2007) assists decision makers in finding key uncertainties that represent vulnerability for a planning alternative. Herman et al., 2016, used SVM to examine the performance of a water supply portfolio under future demand growth and drought scenarios. Figure 7 of Herman et al., 2016, plots factor maps of drought frequency vs. demand growth scaling factor, and shows SVM classification of future states of the world based on whether they met stakeholder performance criteria. Each point on the plot represents a unique drought and demand scenario and the point’s color represents it classification. The classification predicted by soft margin SVM is shown as the shading of the plots. The hyperplanes discovered by SVM allow decision makers to discover what ranges of uncertainties are likely to cause the chosen alternative to fail and can assist in the development of narrative scenarios for future planning purposes.
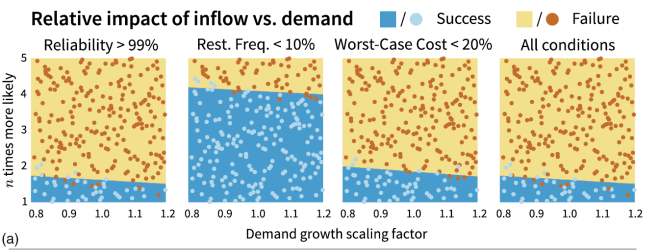
Figure 3: Figure 7 from Herman et al., 2016. Each point represents a sampled uncertainty, demand growth is shown on the horizontal axis and drought frequency (n times more likely) is shown on the vertical axis. The color of each point represents its classification (success or failure to meet stakeholder criteria) and the shading of the plots represents the predicted classification by soft margin SVM.
SVMs are also commonly used for regression in hydrology and downscaling of climate models. SVMs in a regression context are beyond the scope of this post, but see Asefa et al., 2006 for an example of SVMs used to forecast streamflow and Tripathi et al., 2006 for an example of SVMs in downscaling.
Implementing SVMs
In Python, Scikit-learn has an easy to use implementation of SVMs that can be used for classification or regression.
Matlab has several functions for fitting SVMs including fitcsvm.
R has an svm function, and a library devoted to SVMs as part of the e1071 statistical package.
References
Herman, J.D., Zeff, H.B., Lamontagne, J.R., Reed, P.M., Characklis, G.W., 2016. Synthetic drought scenario generation to support bottom-up water supply vulnerability assessments. J. Water Resour. Plann. Manage. 142 (11), 04016050.
Groves, D.G., Lempert, R.J., 2007. A new analytic method for finding policy-relevant scenarios. Global Environ. Change 17 (1), 73–85. http://dx.doi.org/10.1016/j. gloenvcha.20 06.11.0 06 . Uncertainty and Climate Change Adaptation and Mitiga- tion.

Pingback: Intro to Machine Learning Part 6: Gaussian Naive Bayes and Logistic Regression – Water Programming: A Collaborative Research Blog